 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecompose and Leverage Preferences from Expert Models for Improving Trustworthiness of MLLMs
Paper and Code
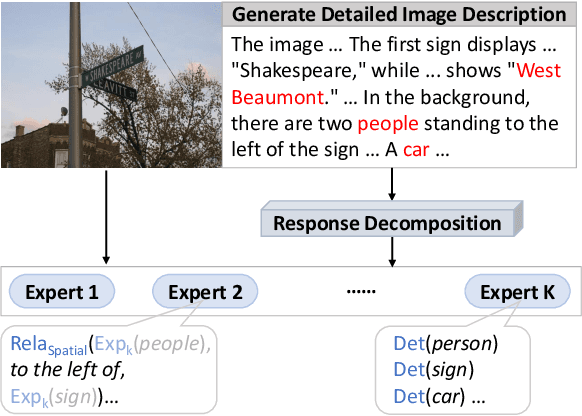

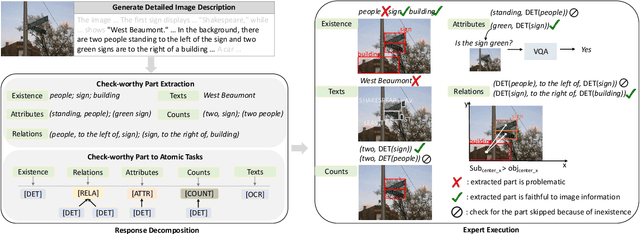
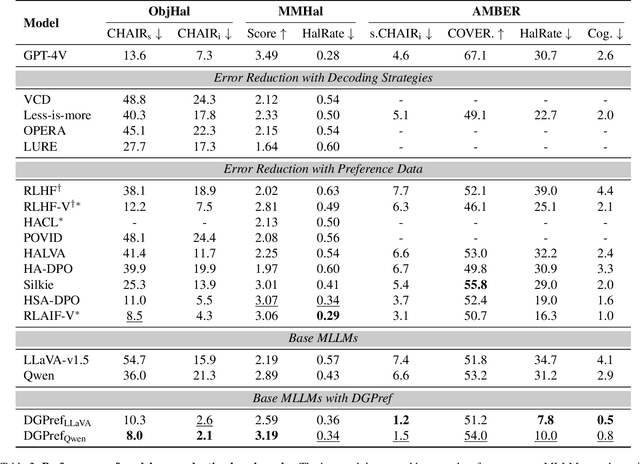
Multimodal Large Language Models (MLLMs) can enhance trustworthiness by aligning with human preferences. As human preference labeling is laborious, recent works employ evaluation models for assessing MLLMs' responses, using the model-based assessments to automate preference dataset construction. This approach, however, faces challenges with MLLMs' lengthy and compositional responses, which often require diverse reasoning skills that a single evaluation model may not fully possess. Additionally, most existing methods rely on closed-source models as evaluators. To address limitations, we propose DecompGen, a decomposable framework that uses an ensemble of open-sourced expert models. DecompGen breaks down each response into atomic verification tasks, assigning each task to an appropriate expert model to generate fine-grained assessments. The DecompGen feedback is used to automatically construct our preference dataset, DGPref. MLLMs aligned with DGPref via preference learning show improvements in trustworthiness, demonstrating the effectiveness of DecompGen.