 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy do you think that? Exploring Faithful Sentence-Level Rationales Without Supervision
Paper and Code
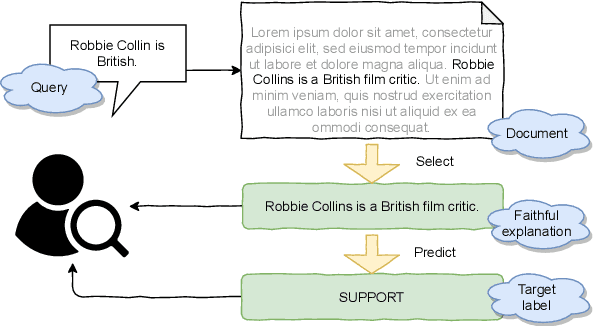


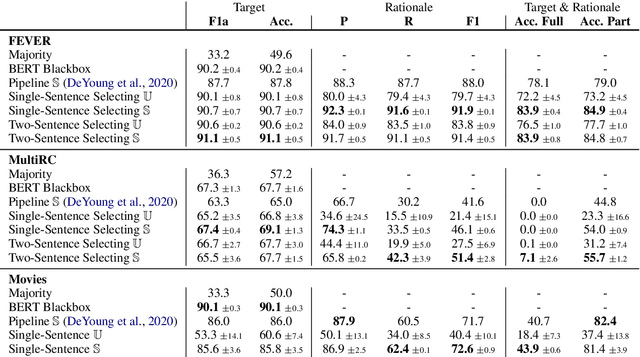
Evaluating the trustworthiness of a model's prediction is essential for differentiating between `right for the right reasons' and `right for the wrong reasons'. Identifying textual spans that determine the target label, known as faithful rationales, usually relies on pipeline approaches or reinforcement learning. However, such methods either require supervision and thus costly annotation of the rationales or employ non-differentiable models. We propose a differentiable training-framework to create models which output faithful rationales on a sentence level, by solely applying supervision on the target task. To achieve this, our model solves the task based on each rationale individually and learns to assign high scores to those which solved the task best. Our evaluation on three different datasets shows competitive results compared to a standard BERT blackbox while exceeding a pipeline counterpart's performance in two cases. We further exploit the transparent decision-making process of these models to prefer selecting the correct rationales by applying direct supervision, thereby boosting the performance on the rationale-level.