 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenting Numerical Substitution Ciphers
May 25, 2022



Deciphering historical substitution ciphers is a challenging problem. Example problems that have been previously studied include detecting cipher type, detecting plaintext language, and acquiring the substitution key for segmented ciphers. However, attacking unsegmented, space-free ciphers is still a challenging task. Segmentation (i.e. finding substitution units) is the first step towards cracking those ciphers. In this work, we propose the first automatic methods to segment those ciphers using Byte Pair Encoding (BPE) and unigram language models. Our methods achieve an average segmentation error of 2\% on 100 randomly-generated monoalphabetic ciphers and 27\% on 3 real homophonic ciphers. We also propose a method for solving non-deterministic ciphers with existing keys using a lattice and a pretrained language model. Our method leads to the full solution of the IA cipher; a real historical cipher that has not been fully solved until this work.
Can Sequence-to-Sequence Models Crack Substitution Ciphers?
Dec 30, 2020
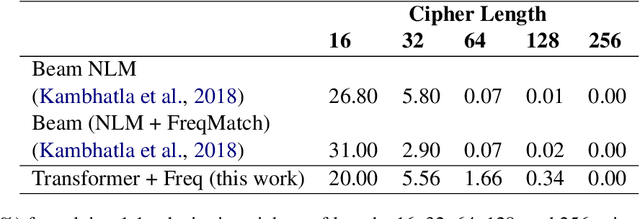


Decipherment of historical ciphers is a challenging problem. The language of the target plaintext might be unknown, and ciphertext can have a lot of noise. State-of-the-art decipherment methods use beam search and a neural language model to score candidate plaintext hypotheses for a given cipher, assuming plaintext language is known. We propose an end-to-end multilingual model for solving simple substitution ciphers. We test our model on synthetic and real historical ciphers and show that our proposed method can decipher text without explicit language identification and can still be robust to noise.
Translating Translationese: A Two-Step Approach to Unsupervised Machine Translation
Jun 11, 2019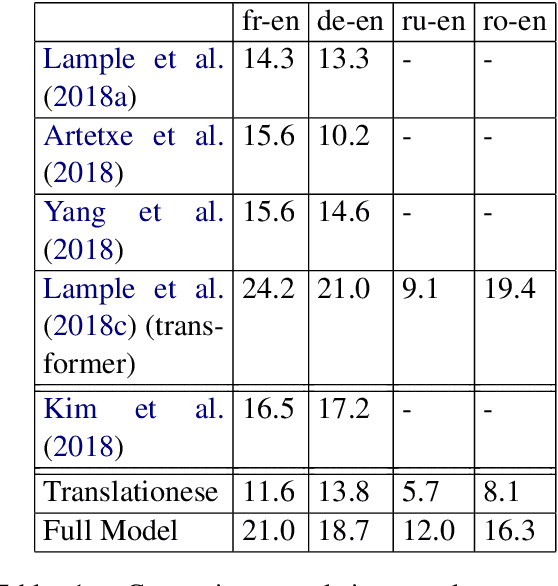
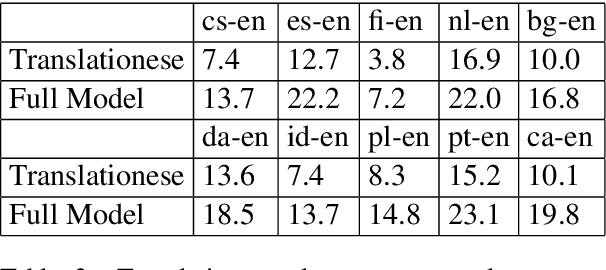
Given a rough, word-by-word gloss of a source language sentence, target language natives can uncover the latent, fully-fluent rendering of the translation. In this work we explore this intuition by breaking translation into a two step process: generating a rough gloss by means of a dictionary and then `translating' the resulting pseudo-translation, or `Translationese' into a fully fluent translation. We build our Translationese decoder once from a mish-mash of parallel data that has the target language in common and then can build dictionaries on demand using unsupervised techniques, resulting in rapidly generated unsupervised neural MT systems for many source languages. We apply this process to 14 test languages, obtaining better or comparable translation results on high-resource languages than previously published unsupervised MT studies, and obtaining good quality results for low-resource languages that have never been used in an unsupervised MT scenario.
Decipherment of Historical Manuscript Images
Oct 09, 2018
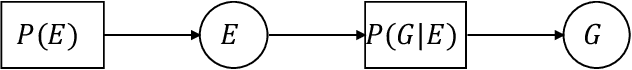
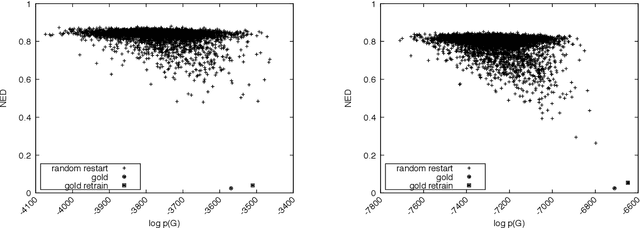
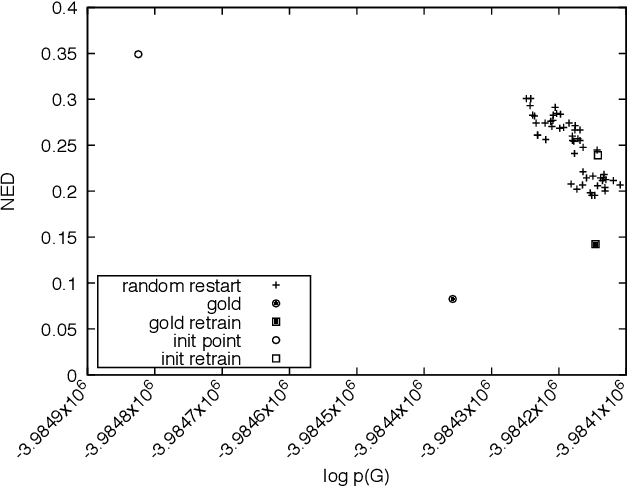
European libraries and archives are filled with enciphered manuscripts from the early modern period. These include military and diplomatic correspondence, records of secret societies, private letters, and so on. Although they are enciphered with classical cryptographic algorithms, their contents are unavailable to working historians. We therefore attack the problem of automatically converting cipher manuscript images into plaintext. We develop unsupervised models for character segmentation, character-image clustering, and decipherment of cluster sequences. We experiment with both pipelined and joint models, and we give empirical results for multiple ciphers.