 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Shots Is All You Need: A Progressive Few Shot Learning Approach for Low Resource Handwriting Recognition
Jul 21, 2021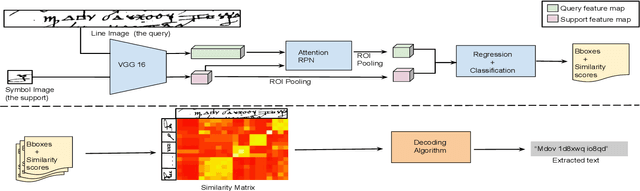
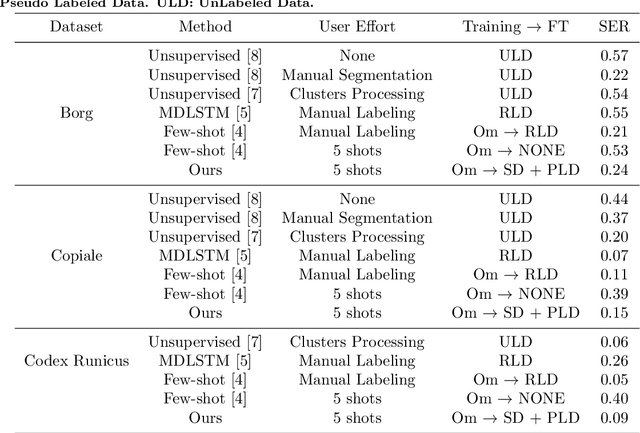
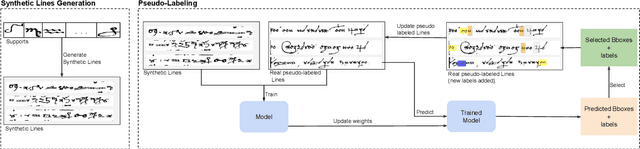
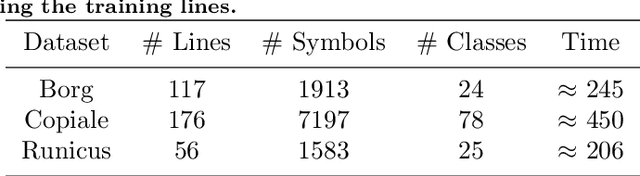
Handwritten text recognition in low resource scenarios, such as manuscripts with rare alphabets, is a challenging problem. The main difficulty comes from the very few annotated data and the limited linguistic information (e.g. dictionaries and language models). Thus, we propose a few-shot learning-based handwriting recognition approach that significantly reduces the human labor annotation process, requiring only few images of each alphabet symbol. First, our model detects all symbols of a given alphabet in a textline image, then a decoding step maps the symbol similarity scores to the final sequence of transcribed symbols. Our model is first pretrained on synthetic line images generated from any alphabet, even though different from the target domain. A second training step is then applied to diminish the gap between the source and target data. Since this retraining would require annotation of thousands of handwritten symbols together with their bounding boxes, we propose to avoid such human effort through an unsupervised progressive learning approach that automatically assigns pseudo-labels to the non-annotated data. The evaluation on different manuscript datasets show that our model can lead to competitive results with a significant reduction in human effort.
Decipherment of Historical Manuscript Images
Oct 09, 2018
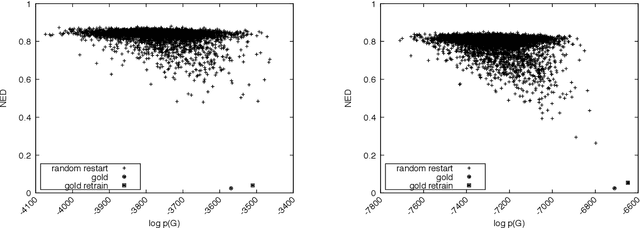
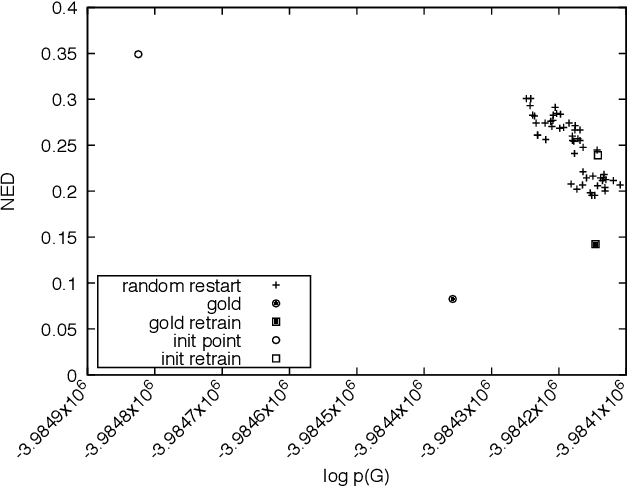
European libraries and archives are filled with enciphered manuscripts from the early modern period. These include military and diplomatic correspondence, records of secret societies, private letters, and so on. Although they are enciphered with classical cryptographic algorithms, their contents are unavailable to working historians. We therefore attack the problem of automatically converting cipher manuscript images into plaintext. We develop unsupervised models for character segmentation, character-image clustering, and decipherment of cluster sequences. We experiment with both pipelined and joint models, and we give empirical results for multiple ciphers.