 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORCA: Orchestrated Reasoning with Collaborative Agents for Document Visual Question Answering
Mar 02, 2026Document Visual Question Answering (DocVQA) remains challenging for existing Vision-Language Models (VLMs), especially under complex reasoning and multi-step workflows. Current approaches struggle to decompose intricate questions into manageable sub-tasks and often fail to leverage specialized processing paths for different document elements. We present ORCA: Orchestrated Reasoning with Collaborative Agents for Document Visual Question Answering, a novel multi-agent framework that addresses these limitations through strategic agent coordination and iterative refinement. ORCA begins with a reasoning agent that decomposes queries into logical steps, followed by a routing mechanism that activates task-specific agents from a specialized agent dock. Our framework leverages a set of specialized AI agents, each dedicated to a distinct modality, enabling fine-grained understanding and collaborative reasoning across diverse document components. To ensure answer reliability, ORCA employs a debate mechanism with stress-testing, and when necessary, a thesis-antithesis adjudication process. This is followed by a sanity checker to ensure format consistency. Extensive experiments on three benchmarks demonstrate that our approach achieves significant improvements over state-of-the-art methods, establishing a new paradigm for collaborative agent systems in vision-language reasoning.
FATURA: A Multi-Layout Invoice Image Dataset for Document Analysis and Understanding
Nov 20, 2023Document analysis and understanding models often require extensive annotated data to be trained. However, various document-related tasks extend beyond mere text transcription, requiring both textual content and precise bounding-box annotations to identify different document elements. Collecting such data becomes particularly challenging, especially in the context of invoices, where privacy concerns add an additional layer of complexity. In this paper, we introduce FATURA, a pivotal resource for researchers in the field of document analysis and understanding. FATURA is a highly diverse dataset featuring multi-layout, annotated invoice document images. Comprising $10,000$ invoices with $50$ distinct layouts, it represents the largest openly accessible image dataset of invoice documents known to date. We also provide comprehensive benchmarks for various document analysis and understanding tasks and conduct experiments under diverse training and evaluation scenarios. The dataset is freely accessible at https://zenodo.org/record/8261508, empowering researchers to advance the field of document analysis and understanding.
MSdocTr-Lite: A Lite Transformer for Full Page Multi-script Handwriting Recognition
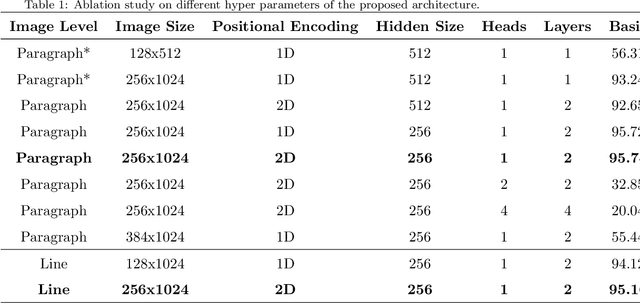
Mar 24, 2023The Transformer has quickly become the dominant architecture for various pattern recognition tasks due to its capacity for long-range representation. However, transformers are data-hungry models and need large datasets for training. In Handwritten Text Recognition (HTR), collecting a massive amount of labeled data is a complicated and expensive task. In this paper, we propose a lite transformer architecture for full-page multi-script handwriting recognition. The proposed model comes with three advantages: First, to solve the common problem of data scarcity, we propose a lite transformer model that can be trained on a reasonable amount of data, which is the case of most HTR public datasets, without the need for external data. Second, it can learn the reading order at page-level thanks to a curriculum learning strategy, allowing it to avoid line segmentation errors, exploit a larger context and reduce the need for costly segmentation annotations. Third, it can be easily adapted to other scripts by applying a simple transfer-learning process using only page-level labeled images. Extensive experiments on different datasets with different scripts (French, English, Spanish, and Arabic) show the effectiveness of the proposed model.
CSSL-MHTR: Continual Self-Supervised Learning for Scalable Multi-script Handwritten Text Recognition
Mar 16, 2023Self-supervised learning has recently emerged as a strong alternative in document analysis. These approaches are now capable of learning high-quality image representations and overcoming the limitations of supervised methods, which require a large amount of labeled data. However, these methods are unable to capture new knowledge in an incremental fashion, where data is presented to the model sequentially, which is closer to the realistic scenario. In this paper, we explore the potential of continual self-supervised learning to alleviate the catastrophic forgetting problem in handwritten text recognition, as an example of sequence recognition. Our method consists in adding intermediate layers called adapters for each task, and efficiently distilling knowledge from the previous model while learning the current task. Our proposed framework is efficient in both computation and memory complexity. To demonstrate its effectiveness, we evaluate our method by transferring the learned model to diverse text recognition downstream tasks, including Latin and non-Latin scripts. As far as we know, this is the first application of continual self-supervised learning for handwritten text recognition. We attain state-of-the-art performance on English, Italian and Russian scripts, whilst adding only a few parameters per task. The code and trained models will be publicly available.
ST-KeyS: Self-Supervised Transformer for Keyword Spotting in Historical Handwritten Documents
Mar 06, 2023



Keyword spotting (KWS) in historical documents is an important tool for the initial exploration of digitized collections. Nowadays, the most efficient KWS methods are relying on machine learning techniques that require a large amount of annotated training data. However, in the case of historical manuscripts, there is a lack of annotated corpus for training. To handle the data scarcity issue, we investigate the merits of the self-supervised learning to extract useful representations of the input data without relying on human annotations and then using these representations in the downstream task. We propose ST-KeyS, a masked auto-encoder model based on vision transformers where the pretraining stage is based on the mask-and-predict paradigm, without the need of labeled data. In the fine-tuning stage, the pre-trained encoder is integrated into a siamese neural network model that is fine-tuned to improve feature embedding from the input images. We further improve the image representation using pyramidal histogram of characters (PHOC) embedding to create and exploit an intermediate representation of images based on text attributes. In an exhaustive experimental evaluation on three widely used benchmark datasets (Botany, Alvermann Konzilsprotokolle and George Washington), the proposed approach outperforms state-of-the-art methods trained on the same datasets.
Text-DIAE: Degradation Invariant Autoencoders for Text Recognition and Document Enhancement
Mar 16, 2022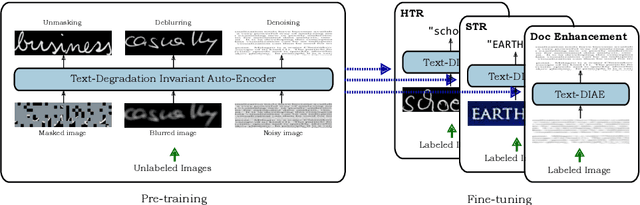
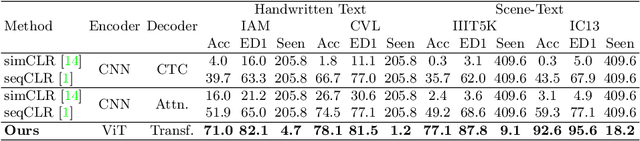
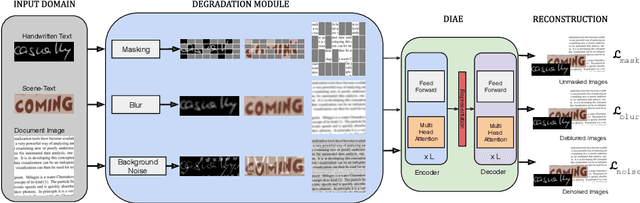
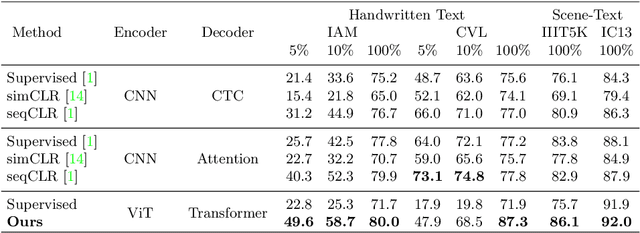
In this work, we propose Text-Degradation Invariant Auto Encoder (Text-DIAE) aimed to solve two tasks, text recognition (handwritten or scene-text) and document image enhancement. We define three pretext tasks as learning objectives to be optimized during pre-training without the usage of labelled data. Each of the pre-text objectives is specifically tailored for the final downstream tasks. We conduct several ablation experiments that show the importance of each degradation for a specific domain. Exhaustive experimentation shows that our method does not have limitations of previous state-of-the-art based on contrastive losses while at the same time requiring essentially fewer data samples to converge. Finally, we demonstrate that our method surpasses the state-of-the-art significantly in existing supervised and self-supervised settings in handwritten and scene text recognition and document image enhancement. Our code and trained models will be made publicly available at~\url{ http://Upon_Acceptance}.
DocEnTr: An End-to-End Document Image Enhancement Transformer
Jan 25, 2022Document images can be affected by many degradation scenarios, which cause recognition and processing difficulties. In this age of digitization, it is important to denoise them for proper usage. To address this challenge, we present a new encoder-decoder architecture based on vision transformers to enhance both machine-printed and handwritten document images, in an end-to-end fashion. The encoder operates directly on the pixel patches with their positional information without the use of any convolutional layers, while the decoder reconstructs a clean image from the encoded patches. Conducted experiments show a superiority of the proposed model compared to the state-of the-art methods on several DIBCO benchmarks. Code and models will be publicly available at: \url{https://github.com/dali92002/DocEnTR}.
Transformer-Based Approach for Joint Handwriting and Named Entity Recognition in Historical documents
Dec 08, 2021

The extraction of relevant information carried out by named entities in handwriting documents is still a challenging task. Unlike traditional information extraction approaches that usually face text transcription and named entity recognition as separate subsequent tasks, we propose in this paper an end-to-end transformer-based approach to jointly perform these two tasks. The proposed approach operates at the paragraph level, which brings two main benefits. First, it allows the model to avoid unrecoverable early errors due to line segmentation. Second, it allows the model to exploit larger bi-dimensional context information to identify the semantic categories, reaching a higher final prediction accuracy. We also explore different training scenarios to show their effect on the performance and we demonstrate that a two-stage learning strategy can make the model reach a higher final prediction accuracy. As far as we know, this work presents the first approach that adopts the transformer networks for named entity recognition in handwritten documents. We achieve the new state-of-the-art performance in the ICDAR 2017 Information Extraction competition using the Esposalles database, for the complete task, even though the proposed technique does not use any dictionaries, language modeling, or post-processing.
Few Shots Is All You Need: A Progressive Few Shot Learning Approach for Low Resource Handwriting Recognition
Jul 21, 2021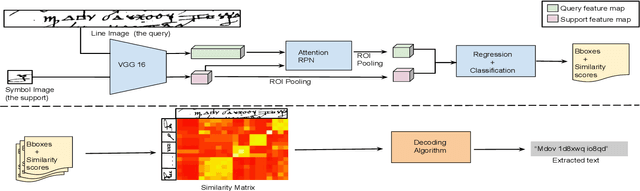
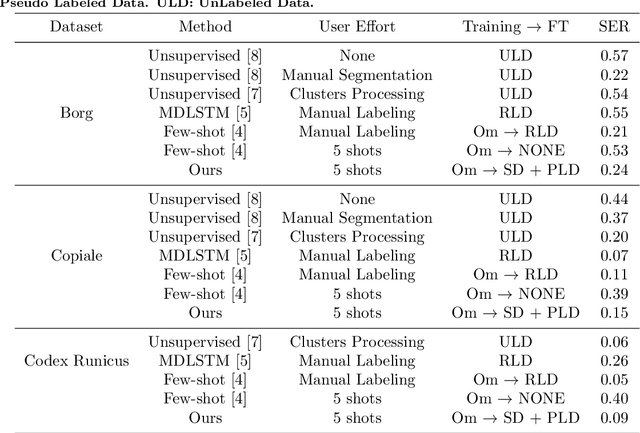
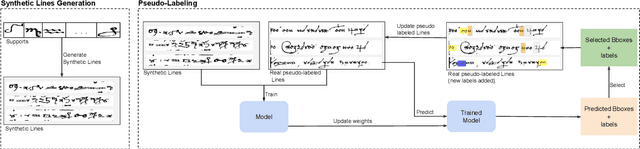
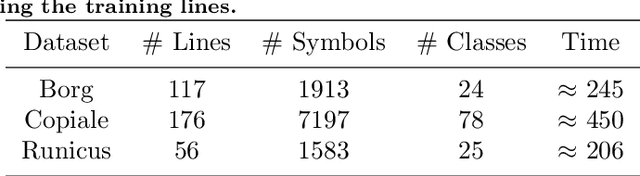
Handwritten text recognition in low resource scenarios, such as manuscripts with rare alphabets, is a challenging problem. The main difficulty comes from the very few annotated data and the limited linguistic information (e.g. dictionaries and language models). Thus, we propose a few-shot learning-based handwriting recognition approach that significantly reduces the human labor annotation process, requiring only few images of each alphabet symbol. First, our model detects all symbols of a given alphabet in a textline image, then a decoding step maps the symbol similarity scores to the final sequence of transcribed symbols. Our model is first pretrained on synthetic line images generated from any alphabet, even though different from the target domain. A second training step is then applied to diminish the gap between the source and target data. Since this retraining would require annotation of thousands of handwritten symbols together with their bounding boxes, we propose to avoid such human effort through an unsupervised progressive learning approach that automatically assigns pseudo-labels to the non-annotated data. The evaluation on different manuscript datasets show that our model can lead to competitive results with a significant reduction in human effort.
Enhance to Read Better: An Improved Generative Adversarial Network for Handwritten Document Image Enhancement
May 26, 2021
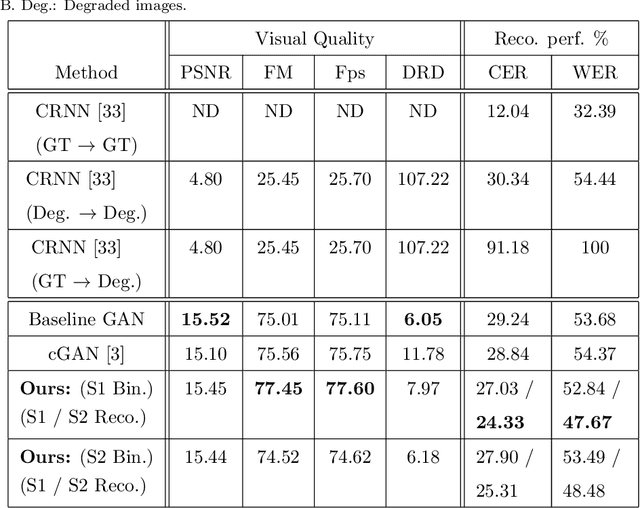
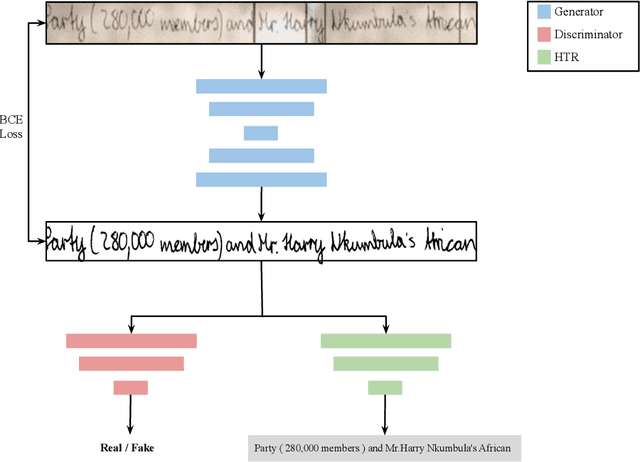
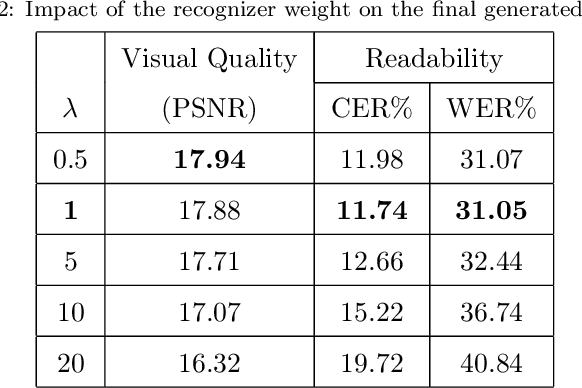
Handwritten document images can be highly affected by degradation for different reasons: Paper ageing, daily-life scenarios (wrinkles, dust, etc.), bad scanning process and so on. These artifacts raise many readability issues for current Handwritten Text Recognition (HTR) algorithms and severely devalue their efficiency. In this paper, we propose an end to end architecture based on Generative Adversarial Networks (GANs) to recover the degraded documents into a clean and readable form. Unlike the most well-known document binarization methods, which try to improve the visual quality of the degraded document, the proposed architecture integrates a handwritten text recognizer that promotes the generated document image to be more readable. To the best of our knowledge, this is the first work to use the text information while binarizing handwritten documents. Extensive experiments conducted on degraded Arabic and Latin handwritten documents demonstrate the usefulness of integrating the recognizer within the GAN architecture, which improves both the visual quality and the readability of the degraded document images. Moreover, we outperform the state of the art in H-DIBCO 2018 challenge, after fine tuning our pre-trained model with synthetically degraded Latin handwritten images, on this task.