 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-DIAE: Degradation Invariant Autoencoders for Text Recognition and Document Enhancement
Paper and Code
Mar 16, 2022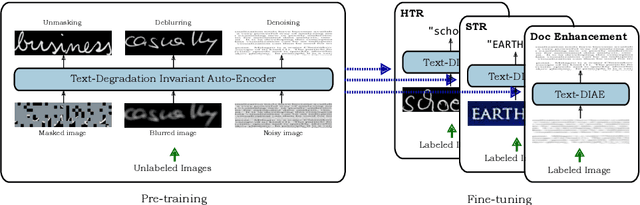
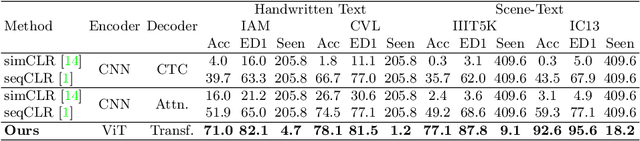
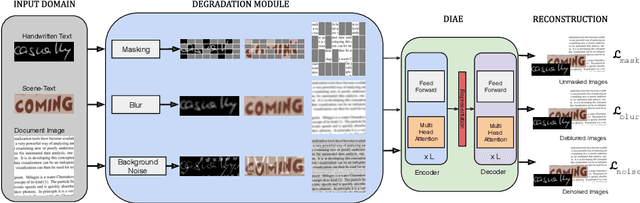
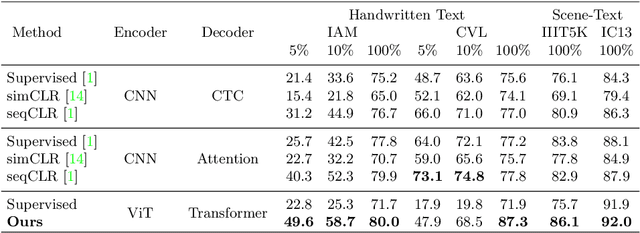
In this work, we propose Text-Degradation Invariant Auto Encoder (Text-DIAE) aimed to solve two tasks, text recognition (handwritten or scene-text) and document image enhancement. We define three pretext tasks as learning objectives to be optimized during pre-training without the usage of labelled data. Each of the pre-text objectives is specifically tailored for the final downstream tasks. We conduct several ablation experiments that show the importance of each degradation for a specific domain. Exhaustive experimentation shows that our method does not have limitations of previous state-of-the-art based on contrastive losses while at the same time requiring essentially fewer data samples to converge. Finally, we demonstrate that our method surpasses the state-of-the-art significantly in existing supervised and self-supervised settings in handwritten and scene text recognition and document image enhancement. Our code and trained models will be made publicly available at~\url{ http://Upon_Acceptance}.