 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Interpret and Tell: Entity-aware Contextualised Image Captioning in Wikipedia
Sep 21, 2022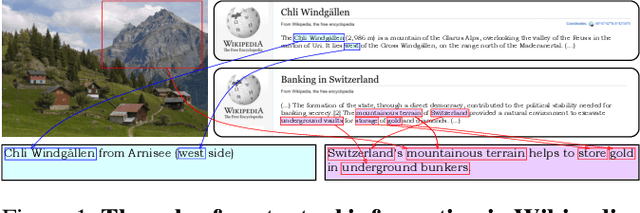
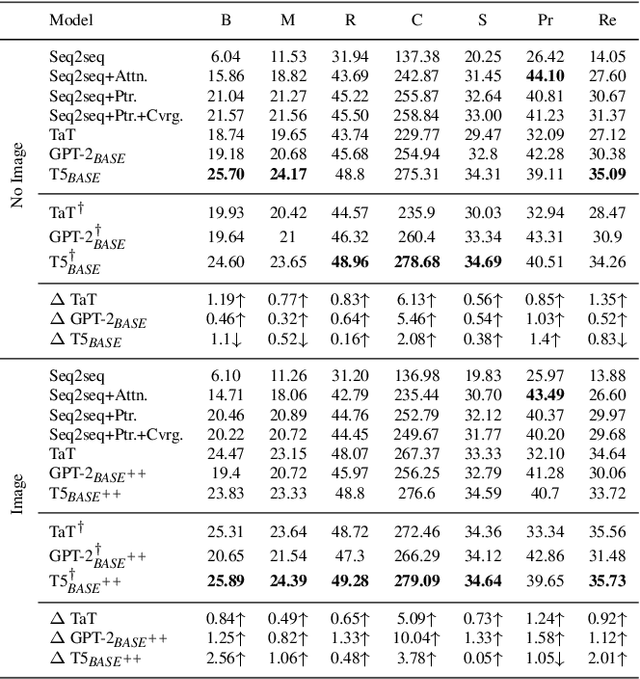
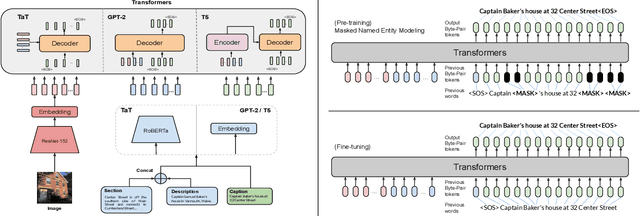
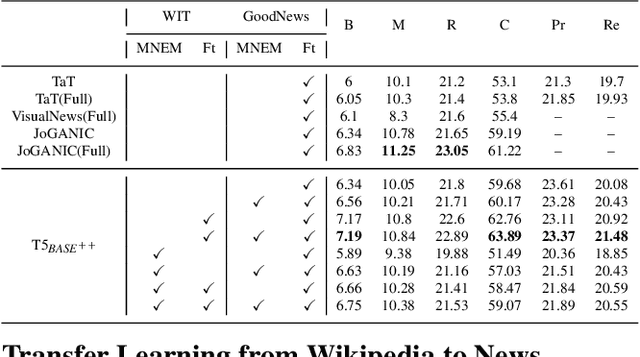
Humans exploit prior knowledge to describe images, and are able to adapt their explanation to specific contextual information, even to the extent of inventing plausible explanations when contextual information and images do not match. In this work, we propose the novel task of captioning Wikipedia images by integrating contextual knowledge. Specifically, we produce models that jointly reason over Wikipedia articles, Wikimedia images and their associated descriptions to produce contextualized captions. Particularly, a similar Wikimedia image can be used to illustrate different articles, and the produced caption needs to be adapted to a specific context, therefore allowing us to explore the limits of a model to adjust captions to different contextual information. A particular challenging task in this domain is dealing with out-of-dictionary words and Named Entities. To address this, we propose a pre-training objective, Masked Named Entity Modeling (MNEM), and show that this pretext task yields an improvement compared to baseline models. Furthermore, we verify that a model pre-trained with the MNEM objective in Wikipedia generalizes well to a News Captioning dataset. Additionally, we define two different test splits according to the difficulty of the captioning task. We offer insights on the role and the importance of each modality and highlight the limitations of our model. The code, models and data splits are publicly available at Upon acceptance.
MUST-VQA: MUltilingual Scene-text VQA
Sep 14, 2022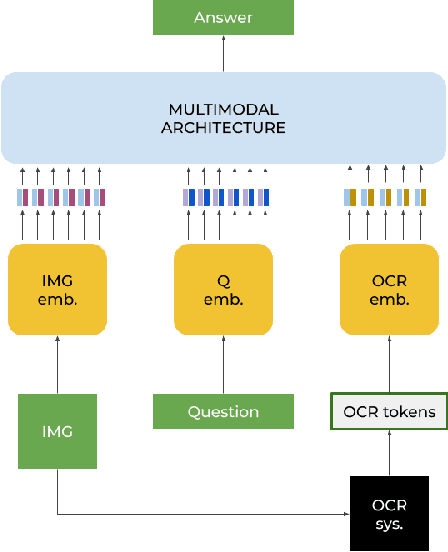
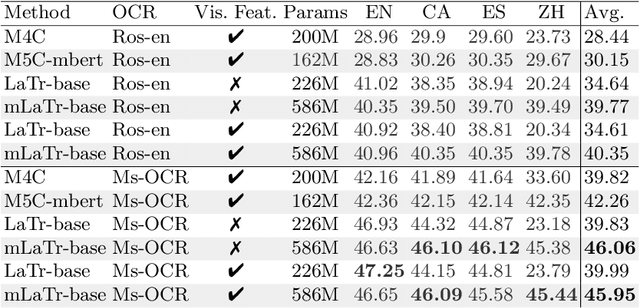
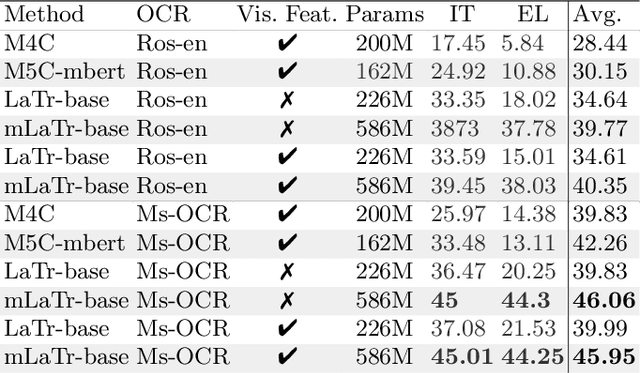
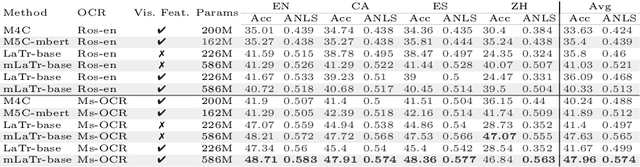
In this paper, we present a framework for Multilingual Scene Text Visual Question Answering that deals with new languages in a zero-shot fashion. Specifically, we consider the task of Scene Text Visual Question Answering (STVQA) in which the question can be asked in different languages and it is not necessarily aligned to the scene text language. Thus, we first introduce a natural step towards a more generalized version of STVQA: MUST-VQA. Accounting for this, we discuss two evaluation scenarios in the constrained setting, namely IID and zero-shot and we demonstrate that the models can perform on a par on a zero-shot setting. We further provide extensive experimentation and show the effectiveness of adapting multilingual language models into STVQA tasks.
Text-DIAE: Degradation Invariant Autoencoders for Text Recognition and Document Enhancement
Mar 16, 2022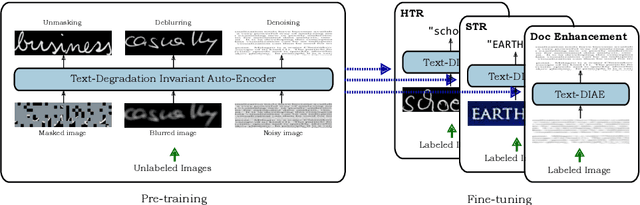
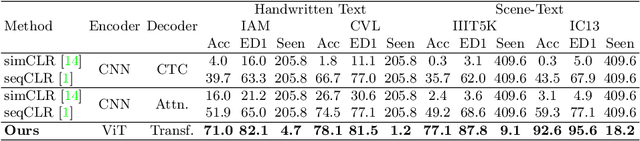
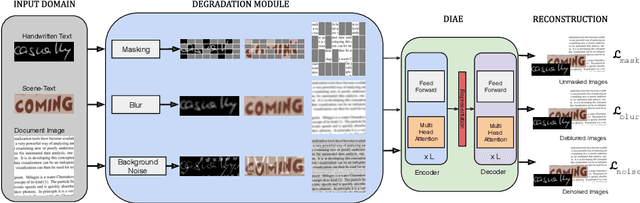
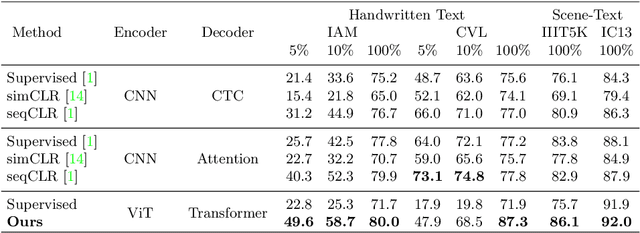
In this work, we propose Text-Degradation Invariant Auto Encoder (Text-DIAE) aimed to solve two tasks, text recognition (handwritten or scene-text) and document image enhancement. We define three pretext tasks as learning objectives to be optimized during pre-training without the usage of labelled data. Each of the pre-text objectives is specifically tailored for the final downstream tasks. We conduct several ablation experiments that show the importance of each degradation for a specific domain. Exhaustive experimentation shows that our method does not have limitations of previous state-of-the-art based on contrastive losses while at the same time requiring essentially fewer data samples to converge. Finally, we demonstrate that our method surpasses the state-of-the-art significantly in existing supervised and self-supervised settings in handwritten and scene text recognition and document image enhancement. Our code and trained models will be made publicly available at~\url{ http://Upon_Acceptance}.
Is An Image Worth Five Sentences? A New Look into Semantics for Image-Text Matching
Oct 06, 2021


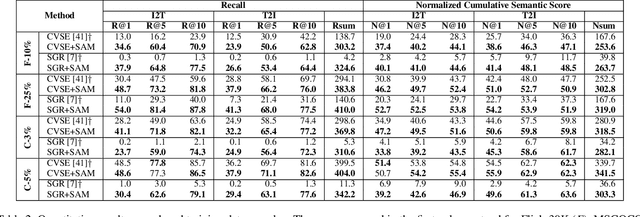
The task of image-text matching aims to map representations from different modalities into a common joint visual-textual embedding. However, the most widely used datasets for this task, MSCOCO and Flickr30K, are actually image captioning datasets that offer a very limited set of relationships between images and sentences in their ground-truth annotations. This limited ground truth information forces us to use evaluation metrics based on binary relevance: given a sentence query we consider only one image as relevant. However, many other relevant images or captions may be present in the dataset. In this work, we propose two metrics that evaluate the degree of semantic relevance of retrieved items, independently of their annotated binary relevance. Additionally, we incorporate a novel strategy that uses an image captioning metric, CIDEr, to define a Semantic Adaptive Margin (SAM) to be optimized in a standard triplet loss. By incorporating our formulation to existing models, a \emph{large} improvement is obtained in scenarios where available training data is limited. We also demonstrate that the performance on the annotated image-caption pairs is maintained while improving on other non-annotated relevant items when employing the full training set. Code with our metrics and adaptive margin formulation will be made public.
Multi-Modal Reasoning Graph for Scene-Text Based Fine-Grained Image Classification and Retrieval
Sep 21, 2020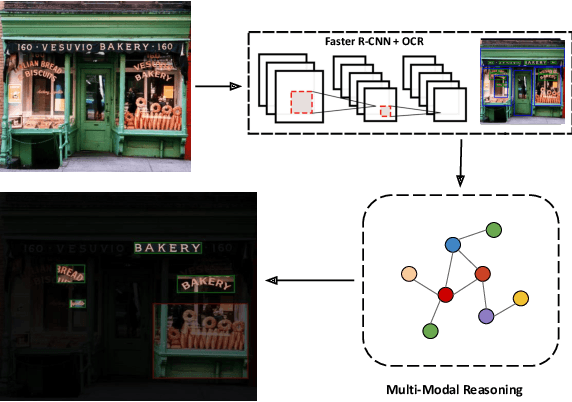
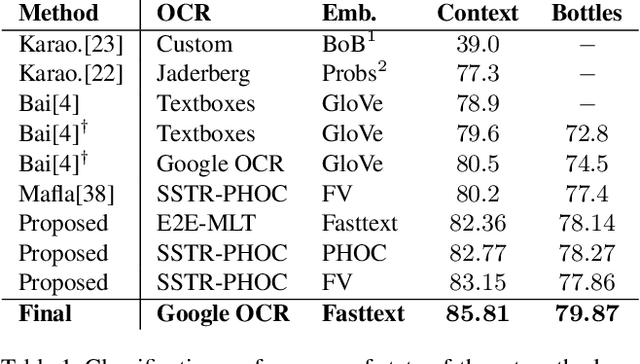
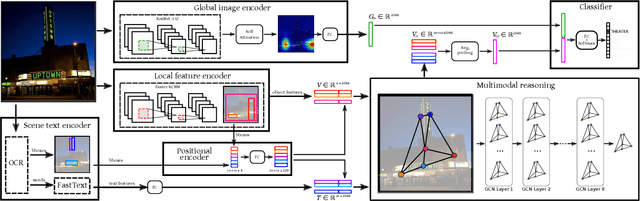
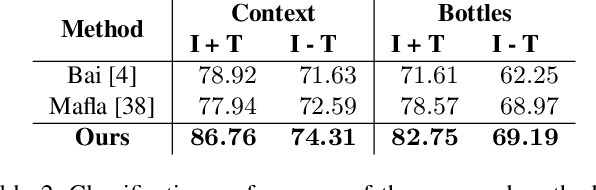
Scene text instances found in natural images carry explicit semantic information that can provide important cues to solve a wide array of computer vision problems. In this paper, we focus on leveraging multi-modal content in the form of visual and textual cues to tackle the task of fine-grained image classification and retrieval. First, we obtain the text instances from images by employing a text reading system. Then, we combine textual features with salient image regions to exploit the complementary information carried by the two sources. Specifically, we employ a Graph Convolutional Network to perform multi-modal reasoning and obtain relationship-enhanced features by learning a common semantic space between salient objects and text found in an image. By obtaining an enhanced set of visual and textual features, the proposed model greatly outperforms the previous state-of-the-art in two different tasks, fine-grained classification and image retrieval in the Con-Text and Drink Bottle datasets.
Fine-grained Image Classification and Retrieval by Combining Visual and Locally Pooled Textual Features
Jan 14, 2020
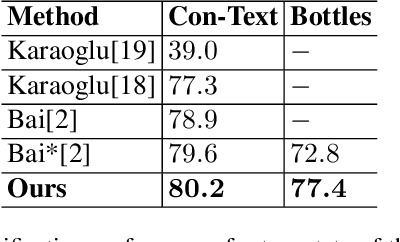
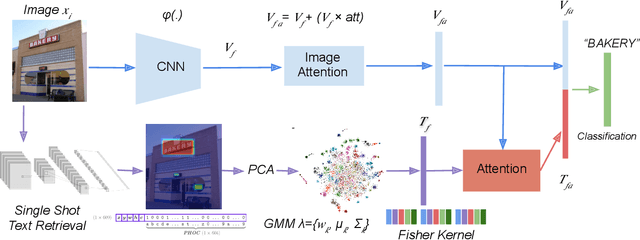
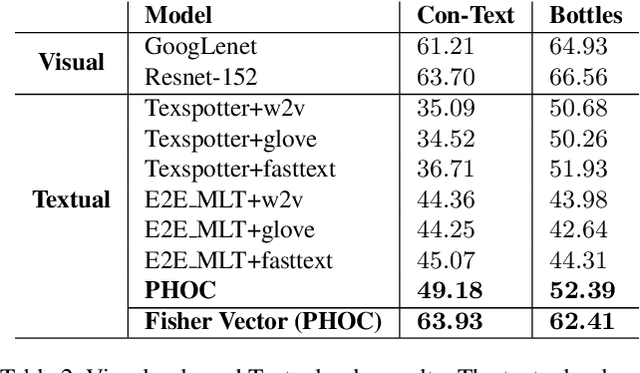
Text contained in an image carries high-level semantics that can be exploited to achieve richer image understanding. In particular, the mere presence of text provides strong guiding content that should be employed to tackle a diversity of computer vision tasks such as image retrieval, fine-grained classification, and visual question answering. In this paper, we address the problem of fine-grained classification and image retrieval by leveraging textual information along with visual cues to comprehend the existing intrinsic relation between the two modalities. The novelty of the proposed model consists of the usage of a PHOC descriptor to construct a bag of textual words along with a Fisher Vector Encoding that captures the morphology of text. This approach provides a stronger multimodal representation for this task and as our experiments demonstrate, it achieves state-of-the-art results on two different tasks, fine-grained classification and image retrieval.
ICDAR 2019 Competition on Scene Text Visual Question Answering
Jun 30, 2019
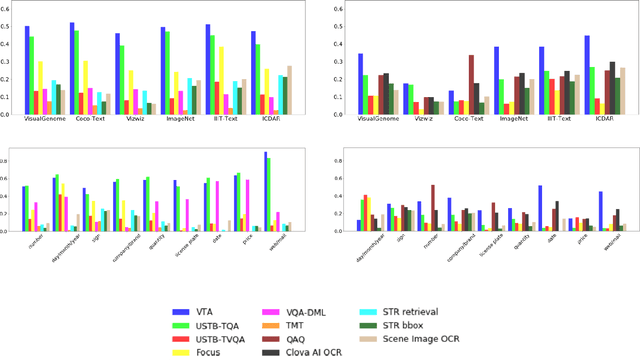
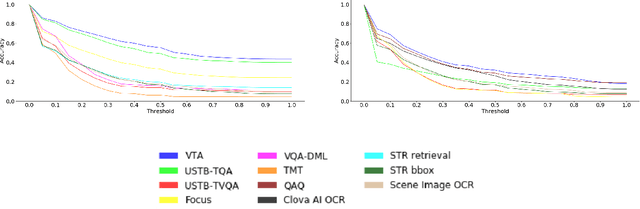
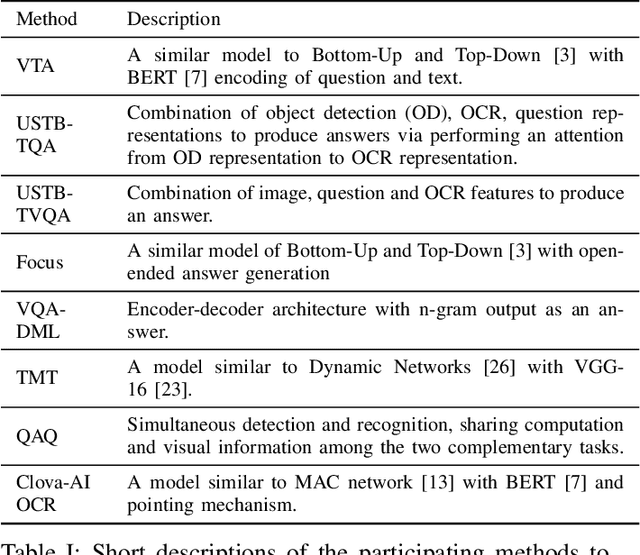
This paper presents final results of ICDAR 2019 Scene Text Visual Question Answering competition (ST-VQA). ST-VQA introduces an important aspect that is not addressed by any Visual Question Answering system up to date, namely the incorporation of scene text to answer questions asked about an image. The competition introduces a new dataset comprising 23,038 images annotated with 31,791 question/answer pairs where the answer is always grounded on text instances present in the image. The images are taken from 7 different public computer vision datasets, covering a wide range of scenarios. The competition was structured in three tasks of increasing difficulty, that require reading the text in a scene and understanding it in the context of the scene, to correctly answer a given question. A novel evaluation metric is presented, which elegantly assesses both key capabilities expected from an optimal model: text recognition and image understanding. A detailed analysis of results from different participants is showcased, which provides insight into the current capabilities of VQA systems that can read. We firmly believe the dataset proposed in this challenge will be an important milestone to consider towards a path of more robust and general models that can exploit scene text to achieve holistic image understanding.
Scene Text Visual Question Answering
May 31, 2019
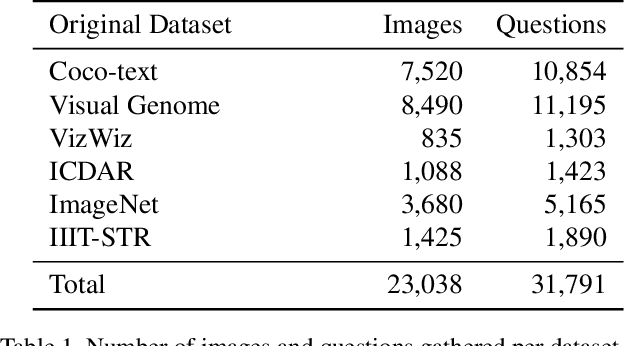
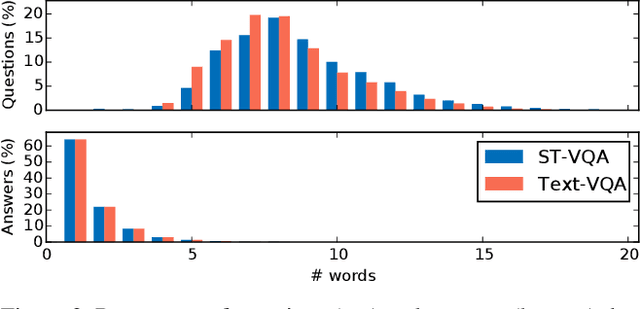
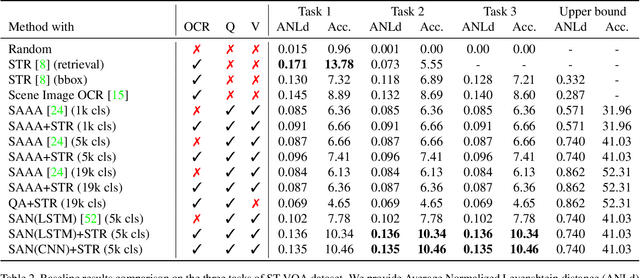
Current visual question answering datasets do not consider the rich semantic information conveyed by text within an image. In this work, we present a new dataset, ST-VQA, that aims to highlight the importance of exploiting high-level semantic information present in images as textual cues in the VQA process. We use this dataset to define a series of tasks of increasing difficulty for which reading the scene text in the context provided by the visual information is necessary to reason and generate an appropriate answer. We propose a new evaluation metric for these tasks to account both for reasoning errors as well as shortcomings of the text recognition module. In addition we put forward a series of baseline methods, which provide further insight to the newly released dataset, and set the scene for further research.