 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Visual Question Answering Challenge 2020
Aug 20, 2020
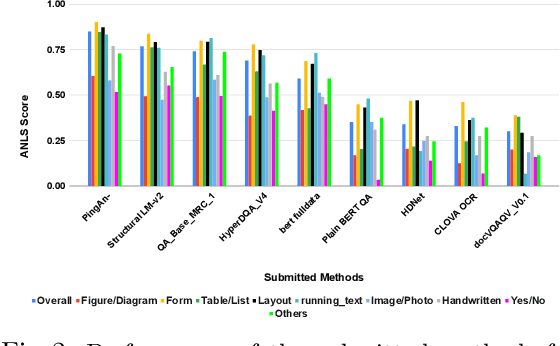
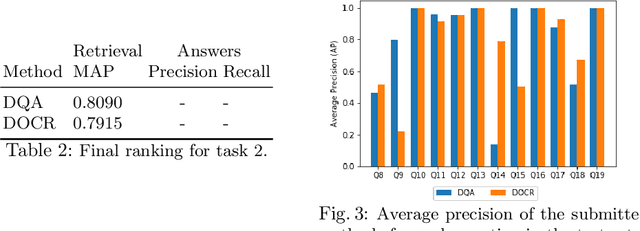
This paper presents results of Document Visual Question Answering Challenge organized as part of "Text and Documents in the Deep Learning Era" workshop, in CVPR 2020. The challenge introduces a new problem - Visual Question Answering on document images. The challenge comprised two tasks. The first task concerns with asking questions on a single document image. On the other hand, the second task is set as a retrieval task where the question is posed over a collection of images. For the task 1 a new dataset is introduced comprising 50,000 questions-answer(s) pairs defined over 12,767 document images. For task 2 another dataset has been created comprising 20 questions over 14,362 document images which share the same document template.
Scene Text Visual Question Answering
May 31, 2019
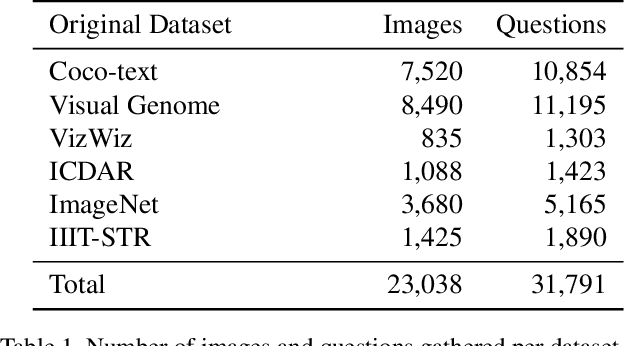
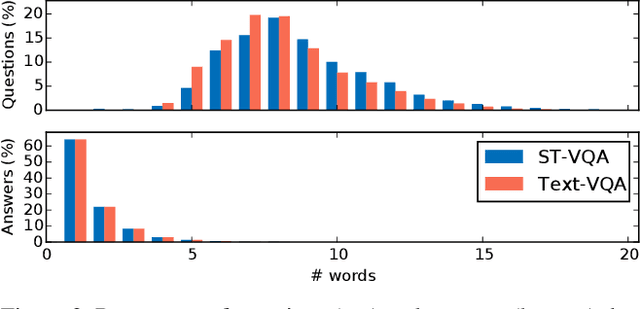
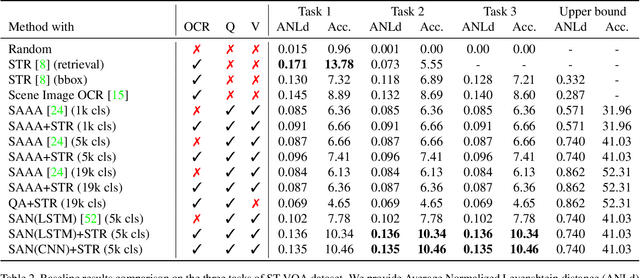
Current visual question answering datasets do not consider the rich semantic information conveyed by text within an image. In this work, we present a new dataset, ST-VQA, that aims to highlight the importance of exploiting high-level semantic information present in images as textual cues in the VQA process. We use this dataset to define a series of tasks of increasing difficulty for which reading the scene text in the context provided by the visual information is necessary to reason and generate an appropriate answer. We propose a new evaluation metric for these tasks to account both for reasoning errors as well as shortcomings of the text recognition module. In addition we put forward a series of baseline methods, which provide further insight to the newly released dataset, and set the scene for further research.