Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument Visual Question Answering Challenge 2020
Paper and Code
Aug 20, 2020
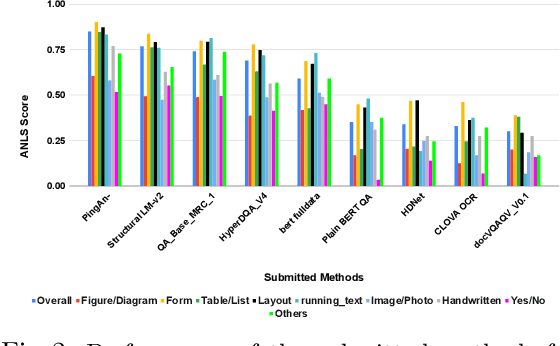
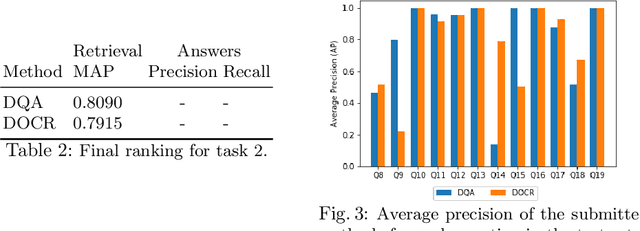
This paper presents results of Document Visual Question Answering Challenge organized as part of "Text and Documents in the Deep Learning Era" workshop, in CVPR 2020. The challenge introduces a new problem - Visual Question Answering on document images. The challenge comprised two tasks. The first task concerns with asking questions on a single document image. On the other hand, the second task is set as a retrieval task where the question is posed over a collection of images. For the task 1 a new dataset is introduced comprising 50,000 questions-answer(s) pairs defined over 12,767 document images. For task 2 another dataset has been created comprising 20 questions over 14,362 document images which share the same document template.
* to be published as a short paper in DAS 2020
View paper on