 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUST-VQA: MUltilingual Scene-text VQA
Paper and Code
Sep 14, 2022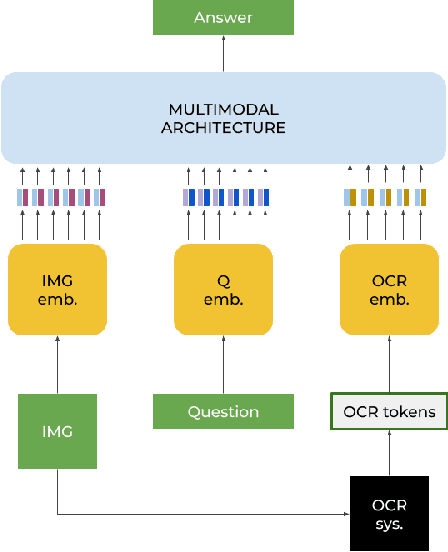
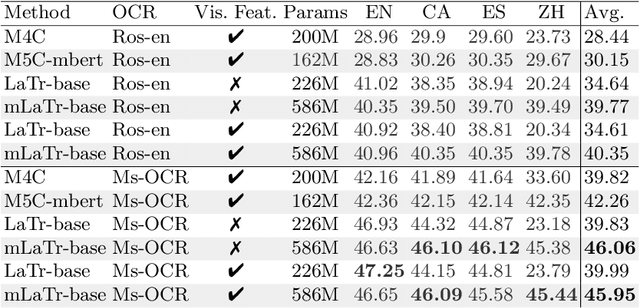
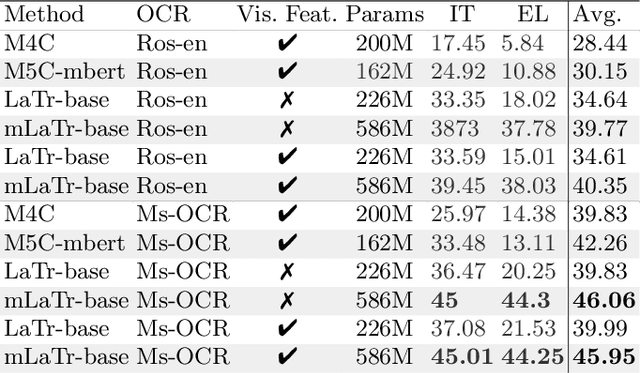
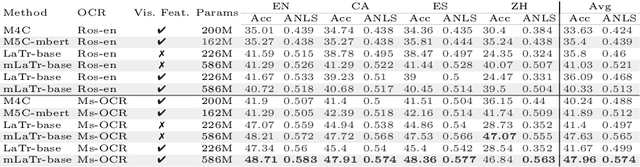
In this paper, we present a framework for Multilingual Scene Text Visual Question Answering that deals with new languages in a zero-shot fashion. Specifically, we consider the task of Scene Text Visual Question Answering (STVQA) in which the question can be asked in different languages and it is not necessarily aligned to the scene text language. Thus, we first introduce a natural step towards a more generalized version of STVQA: MUST-VQA. Accounting for this, we discuss two evaluation scenarios in the constrained setting, namely IID and zero-shot and we demonstrate that the models can perform on a par on a zero-shot setting. We further provide extensive experimentation and show the effectiveness of adapting multilingual language models into STVQA tasks.