 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShow, Interpret and Tell: Entity-aware Contextualised Image Captioning in Wikipedia
Paper and Code
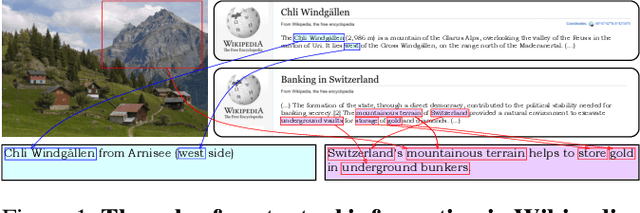
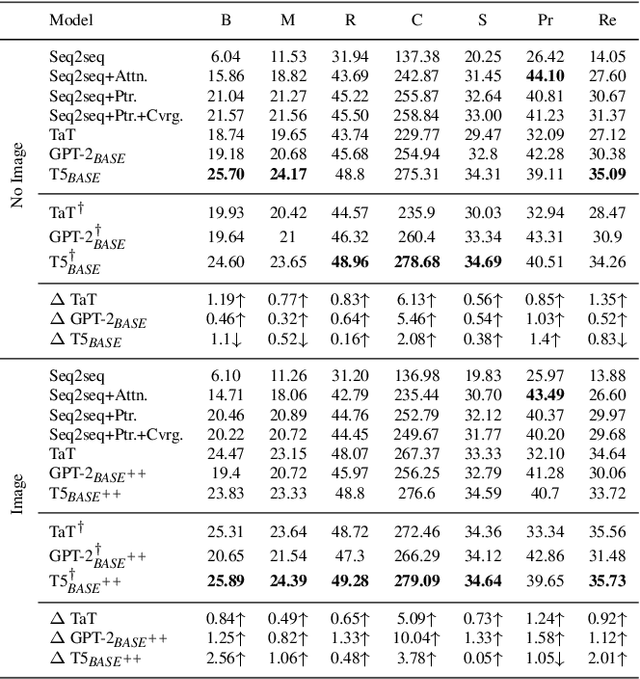
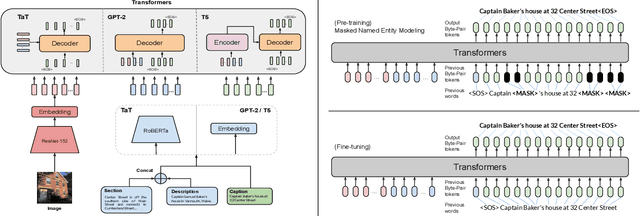
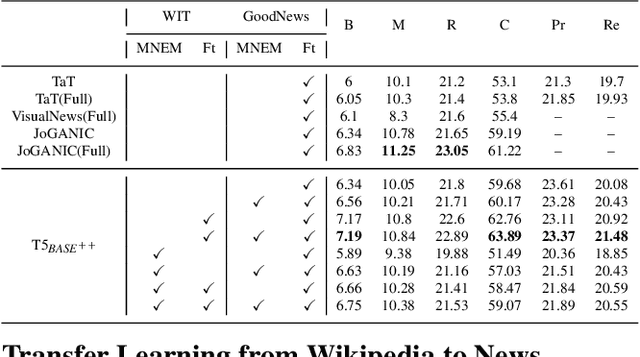
Humans exploit prior knowledge to describe images, and are able to adapt their explanation to specific contextual information, even to the extent of inventing plausible explanations when contextual information and images do not match. In this work, we propose the novel task of captioning Wikipedia images by integrating contextual knowledge. Specifically, we produce models that jointly reason over Wikipedia articles, Wikimedia images and their associated descriptions to produce contextualized captions. Particularly, a similar Wikimedia image can be used to illustrate different articles, and the produced caption needs to be adapted to a specific context, therefore allowing us to explore the limits of a model to adjust captions to different contextual information. A particular challenging task in this domain is dealing with out-of-dictionary words and Named Entities. To address this, we propose a pre-training objective, Masked Named Entity Modeling (MNEM), and show that this pretext task yields an improvement compared to baseline models. Furthermore, we verify that a model pre-trained with the MNEM objective in Wikipedia generalizes well to a News Captioning dataset. Additionally, we define two different test splits according to the difficulty of the captioning task. We offer insights on the role and the importance of each modality and highlight the limitations of our model. The code, models and data splits are publicly available at Upon acceptance.