 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalizing Infinity-shaped fishes: Sketch-guided object localization in the wild
Sep 24, 2021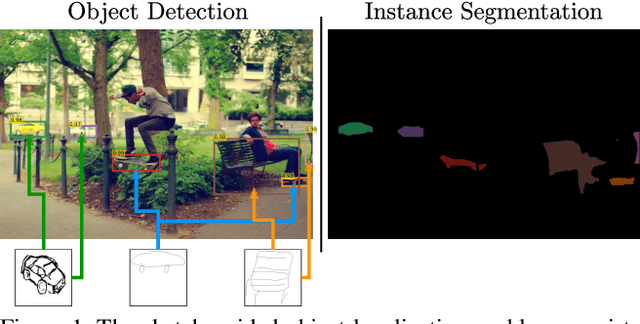

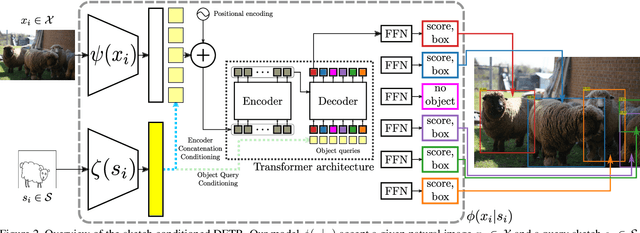
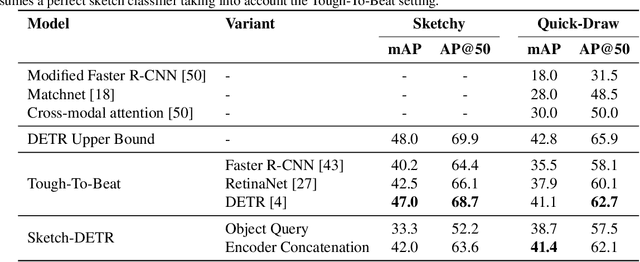
This work investigates the problem of sketch-guided object localization (SGOL), where human sketches are used as queries to conduct the object localization in natural images. In this cross-modal setting, we first contribute with a tough-to-beat baseline that without any specific SGOL training is able to outperform the previous works on a fixed set of classes. The baseline is useful to analyze the performance of SGOL approaches based on available simple yet powerful methods. We advance prior arts by proposing a sketch-conditioned DETR (DEtection TRansformer) architecture which avoids a hard classification and alleviates the domain gap between sketches and images to localize object instances. Although the main goal of SGOL is focused on object detection, we explored its natural extension to sketch-guided instance segmentation. This novel task allows to move towards identifying the objects at pixel level, which is of key importance in several applications. We experimentally demonstrate that our model and its variants significantly advance over previous state-of-the-art results. All training and testing code of our model will be released to facilitate future research{{https://github.com/priba/sgol_wild}}.
One-shot Compositional Data Generation for Low Resource Handwritten Text Recognition
May 11, 2021
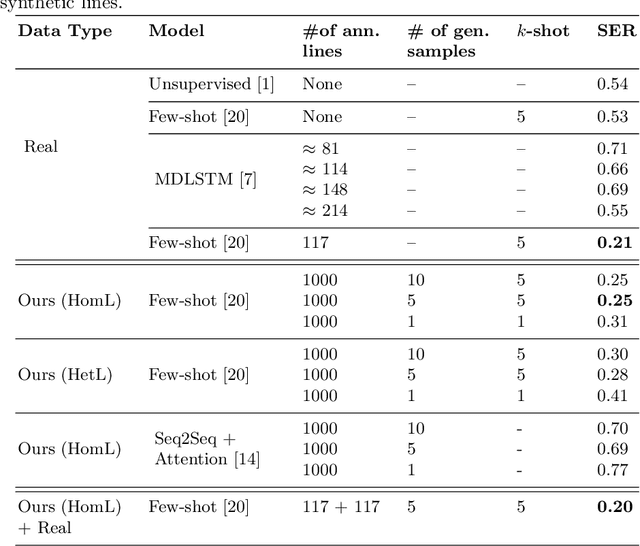
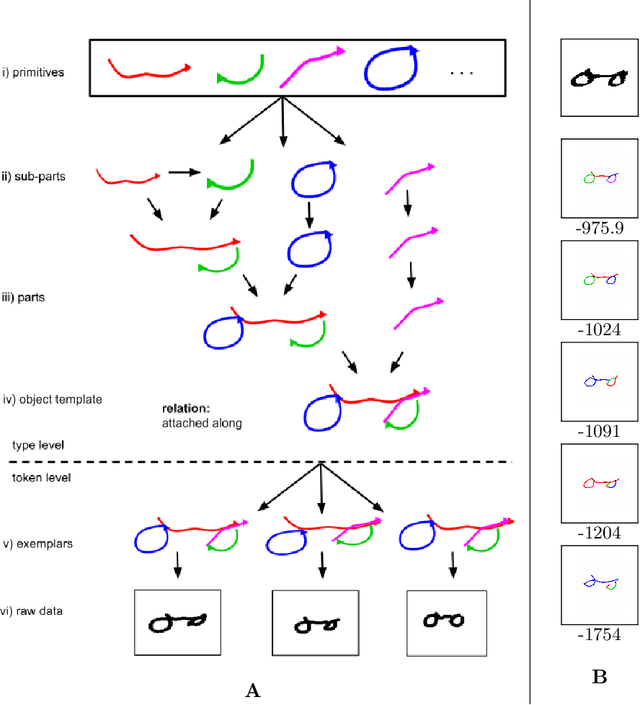

Low resource Handwritten Text Recognition (HTR) is a hard problem due to the scarce annotated data and the very limited linguistic information (dictionaries and language models). This appears, for example, in the case of historical ciphered manuscripts, which are usually written with invented alphabets to hide the content. Thus, in this paper we address this problem through a data generation technique based on Bayesian Program Learning (BPL). Contrary to traditional generation approaches, which require a huge amount of annotated images, our method is able to generate human-like handwriting using only one sample of each symbol from the desired alphabet. After generating symbols, we create synthetic lines to train state-of-the-art HTR architectures in a segmentation free fashion. Quantitative and qualitative analyses were carried out and confirm the effectiveness of the proposed method, achieving competitive results compared to the usage of real annotated data.
Multi-Modal Reasoning Graph for Scene-Text Based Fine-Grained Image Classification and Retrieval
Sep 21, 2020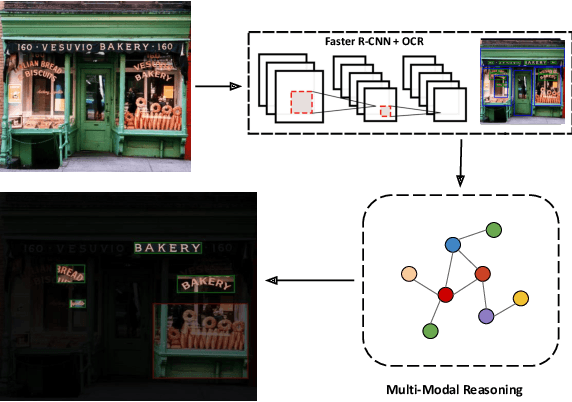
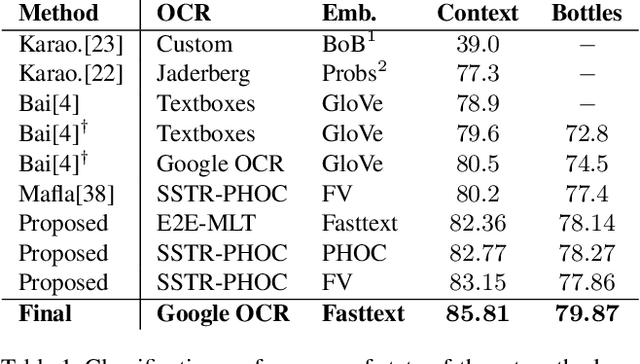
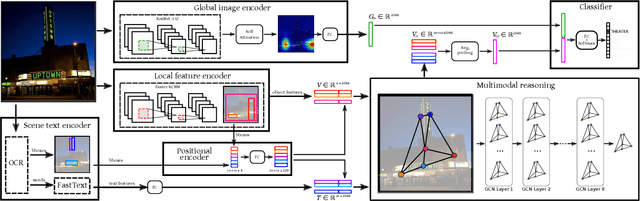
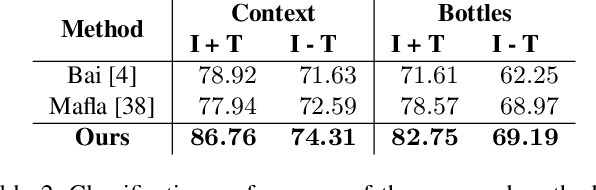
Scene text instances found in natural images carry explicit semantic information that can provide important cues to solve a wide array of computer vision problems. In this paper, we focus on leveraging multi-modal content in the form of visual and textual cues to tackle the task of fine-grained image classification and retrieval. First, we obtain the text instances from images by employing a text reading system. Then, we combine textual features with salient image regions to exploit the complementary information carried by the two sources. Specifically, we employ a Graph Convolutional Network to perform multi-modal reasoning and obtain relationship-enhanced features by learning a common semantic space between salient objects and text found in an image. By obtaining an enhanced set of visual and textual features, the proposed model greatly outperforms the previous state-of-the-art in two different tasks, fine-grained classification and image retrieval in the Con-Text and Drink Bottle datasets.
Fine-grained Image Classification and Retrieval by Combining Visual and Locally Pooled Textual Features
Jan 14, 2020
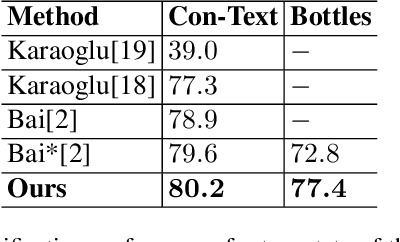
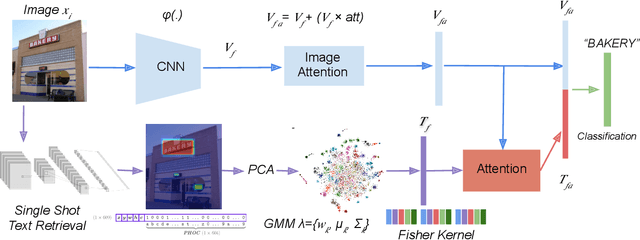
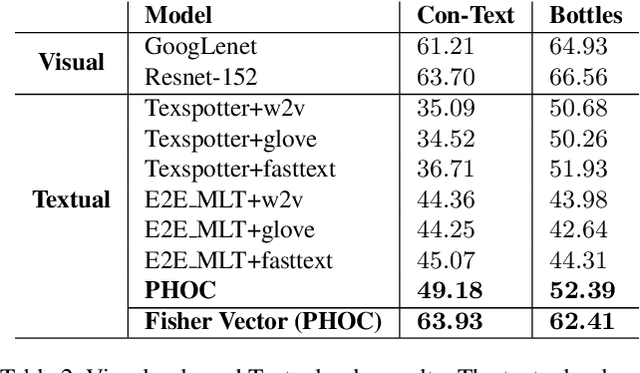
Text contained in an image carries high-level semantics that can be exploited to achieve richer image understanding. In particular, the mere presence of text provides strong guiding content that should be employed to tackle a diversity of computer vision tasks such as image retrieval, fine-grained classification, and visual question answering. In this paper, we address the problem of fine-grained classification and image retrieval by leveraging textual information along with visual cues to comprehend the existing intrinsic relation between the two modalities. The novelty of the proposed model consists of the usage of a PHOC descriptor to construct a bag of textual words along with a Fisher Vector Encoding that captures the morphology of text. This approach provides a stronger multimodal representation for this task and as our experiments demonstrate, it achieves state-of-the-art results on two different tasks, fine-grained classification and image retrieval.
Doodle to Search: Practical Zero-Shot Sketch-based Image Retrieval
Apr 06, 2019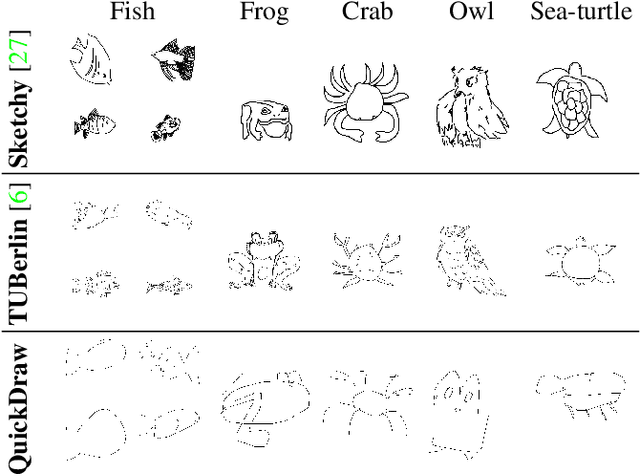


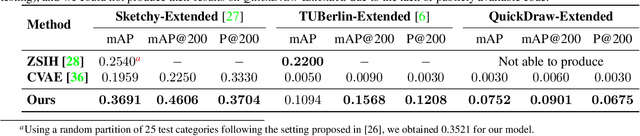
In this paper, we investigate the problem of zero-shot sketch-based image retrieval (ZS-SBIR), where human sketches are used as queries to conduct retrieval of photos from unseen categories. We importantly advance prior arts by proposing a novel ZS-SBIR scenario that represents a firm step forward in its practical application. The new setting uniquely recognizes two important yet often neglected challenges of practical ZS-SBIR, (i) the large domain gap between amateur sketch and photo, and (ii) the necessity for moving towards large-scale retrieval. We first contribute to the community a novel ZS-SBIR dataset, QuickDraw-Extended, that consists of 330,000 sketches and 204,000 photos spanning across 110 categories. Highly abstract amateur human sketches are purposefully sourced to maximize the domain gap, instead of ones included in existing datasets that can often be semi-photorealistic. We then formulate a ZS-SBIR framework to jointly model sketches and photos into a common embedding space. A novel strategy to mine the mutual information among domains is specifically engineered to alleviate the domain gap. External semantic knowledge is further embedded to aid semantic transfer. We show that, rather surprisingly, retrieval performance significantly outperforms that of state-of-the-art on existing datasets that can already be achieved using a reduced version of our model. We further demonstrate the superior performance of our full model by comparing with a number of alternatives on the newly proposed dataset. The new dataset, plus all training and testing code of our model, will be publicly released to facilitate future research
Non-deterministic Behavior of Ranking-based Metrics when Evaluating Embeddings
Jun 19, 2018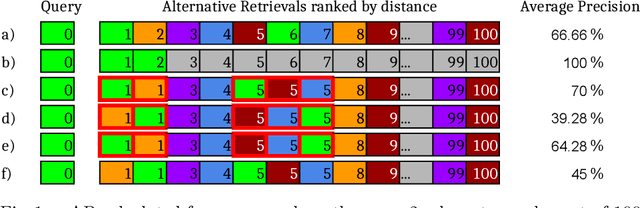
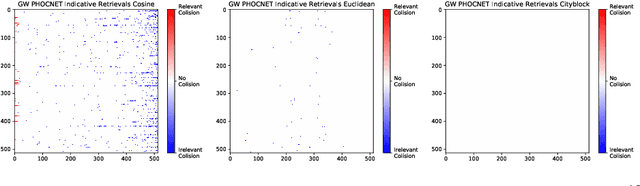


Embedding data into vector spaces is a very popular strategy of pattern recognition methods. When distances between embeddings are quantized, performance metrics become ambiguous. In this paper, we present an analysis of the ambiguity quantized distances introduce and provide bounds on the effect. We demonstrate that it can have a measurable effect in empirical data in state-of-the-art systems. We also approach the phenomenon from a computer security perspective and demonstrate how someone being evaluated by a third party can exploit this ambiguity and greatly outperform a random predictor without even access to the input data. We also suggest a simple solution making the performance metrics, which rely on ranking, totally deterministic and impervious to such exploits.
Learning Cross-Modal Deep Embeddings for Multi-Object Image Retrieval using Text and Sketch
Apr 28, 2018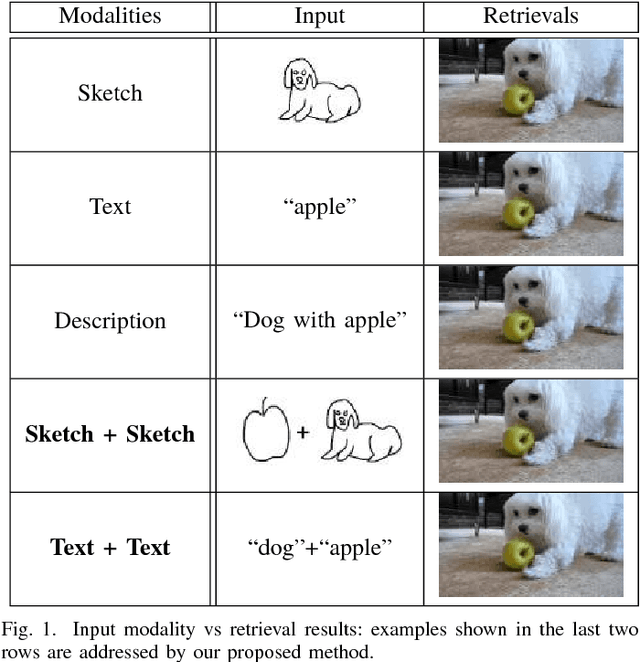
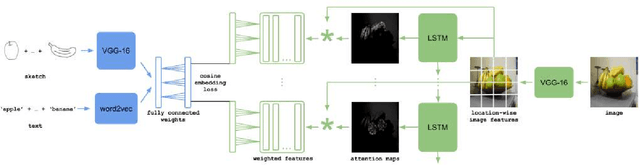

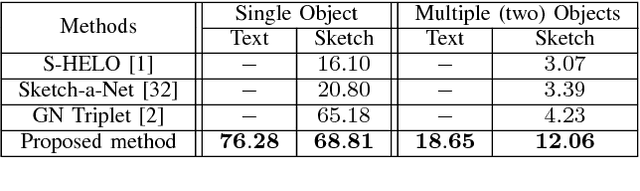
In this work we introduce a cross modal image retrieval system that allows both text and sketch as input modalities for the query. A cross-modal deep network architecture is formulated to jointly model the sketch and text input modalities as well as the the image output modality, learning a common embedding between text and images and between sketches and images. In addition, an attention model is used to selectively focus the attention on the different objects of the image, allowing for retrieval with multiple objects in the query. Experiments show that the proposed method performs the best in both single and multiple object image retrieval in standard datasets.
SigNet: Convolutional Siamese Network for Writer Independent Offline Signature Verification
Sep 30, 2017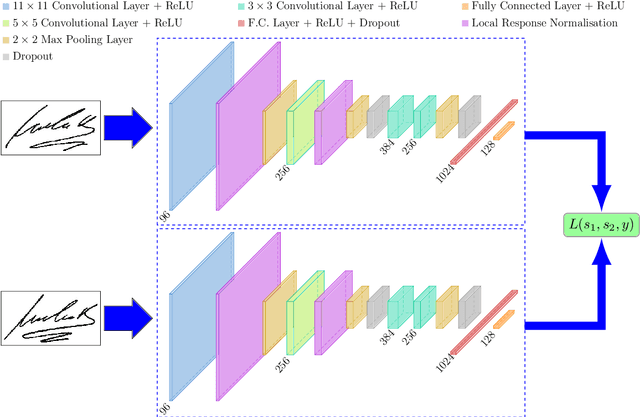
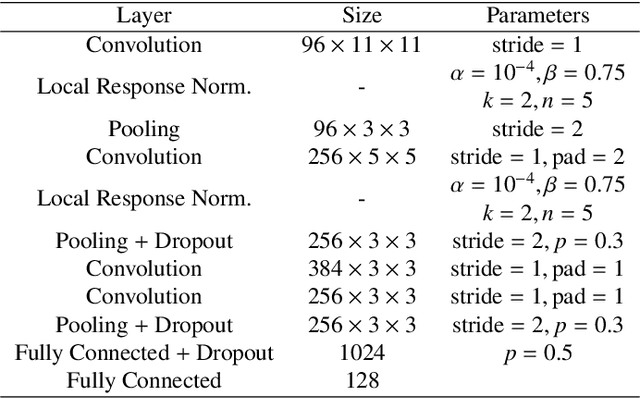


Offline signature verification is one of the most challenging tasks in biometrics and document forensics. Unlike other verification problems, it needs to model minute but critical details between genuine and forged signatures, because a skilled falsification might often resembles the real signature with small deformation. This verification task is even harder in writer independent scenarios which is undeniably fiscal for realistic cases. In this paper, we model an offline writer independent signature verification task with a convolutional Siamese network. Siamese networks are twin networks with shared weights, which can be trained to learn a feature space where similar observations are placed in proximity. This is achieved by exposing the network to a pair of similar and dissimilar observations and minimizing the Euclidean distance between similar pairs while simultaneously maximizing it between dissimilar pairs. Experiments conducted on cross-domain datasets emphasize the capability of our network to model forgery in different languages (scripts) and handwriting styles. Moreover, our designed Siamese network, named SigNet, exceeds the state-of-the-art results on most of the benchmark signature datasets, which paves the way for further research in this direction.
Evaluation of the Effect of Improper Segmentation on Word Spotting
Apr 21, 2016
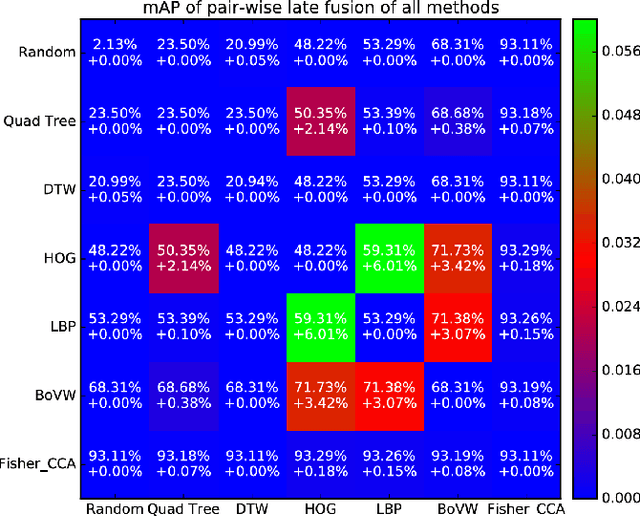

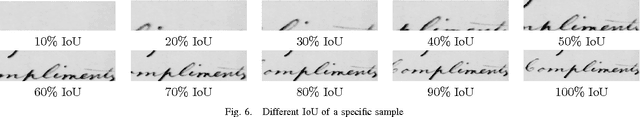
Word spotting is an important recognition task in historical document analysis. In most cases methods are developed and evaluated assuming perfect word segmentations. In this paper we propose an experimental framework to quantify the effect of goodness of word segmentation has on the performance achieved by word spotting methods in identical unbiased conditions. The framework consists of generating systematic distortions on segmentation and retrieving the original queries from the distorted dataset. We apply the framework on the George Washington and Barcelona Marriage Dataset and on several established and state-of-the-art methods. The experiments allow for an estimate of the end-to-end performance of word spotting methods.
Local Binary Pattern for Word Spotting in Handwritten Historical Document
Apr 21, 2016



Digital libraries store images which can be highly degraded and to index this kind of images we resort to word spot- ting as our information retrieval system. Information retrieval for handwritten document images is more challenging due to the difficulties in complex layout analysis, large variations of writing styles, and degradation or low quality of historical manuscripts. This paper presents a simple innovative learning-free method for word spotting from large scale historical documents combining Local Binary Pattern (LBP) and spatial sampling. This method offers three advantages: firstly, it operates in completely learning free paradigm which is very different from unsupervised learning methods, secondly, the computational time is significantly low because of the LBP features which are very fast to compute, and thirdly, the method can be used in scenarios where annotations are not available. Finally we compare the results of our proposed retrieval method with the other methods in the literature.