 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Fair Evaluation of Various Deep Learning-Based Document Image Binarization Approaches
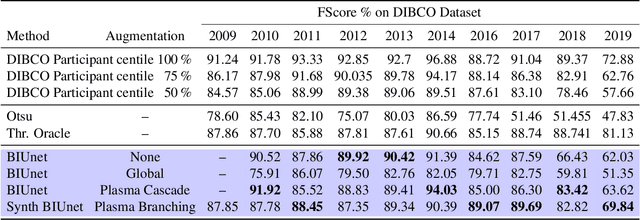
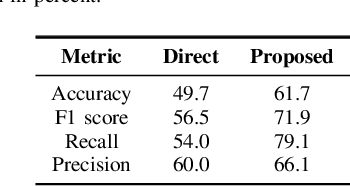
Jan 22, 2024Binarization of document images is an important pre-processing step in the field of document analysis. Traditional image binarization techniques usually rely on histograms or local statistics to identify a valid threshold to differentiate between different aspects of the image. Deep learning techniques are able to generate binarized versions of the images by learning context-dependent features that are less error-prone to degradation typically occurring in document images. In recent years, many deep learning-based methods have been developed for document binarization. But which one to choose? There have been no studies that compare these methods rigorously. Therefore, this work focuses on the evaluation of different deep learning-based methods under the same evaluation protocol. We evaluate them on different Document Image Binarization Contest (DIBCO) datasets and obtain very heterogeneous results. We show that the DE-GAN model was able to perform better compared to other models when evaluated on the DIBCO2013 dataset while DP-LinkNet performed best on the DIBCO2017 dataset. The 2-StageGAN performed best on the DIBCO2018 dataset while SauvolaNet outperformed the others on the DIBCO2019 challenge. Finally, we make the code, all models and evaluation publicly available (https://github.com/RichSu95/Document_Binarization_Collection) to ensure reproducibility and simplify future binarization evaluations.
* DAS 2022
Efficient Annotation of Medieval Charters
Jun 24, 2023Diplomatics, the analysis of medieval charters, is a major field of research in which paleography is applied. Annotating data, if performed by laymen, needs validation and correction by experts. In this paper, we propose an effective and efficient annotation approach for charter segmentation, essentially reducing it to object detection. This approach allows for a much more efficient use of the paleographer's time and produces results that can compete and even outperform pixel-level segmentation in some use cases. Further experiments shed light on how to design a class ontology in order to make the best use of annotators' time and effort. Exploiting the presence of calibration cards in the image, we further annotate the data with the physical length in pixels and train regression neural networks to predict it from image patches.
Writer Retrieval and Writer Identification in Greek Papyri
Dec 15, 2022The analysis of digitized historical manuscripts is typically addressed by paleographic experts. Writer identification refers to the classification of known writers while writer retrieval seeks to find the writer by means of image similarity in a dataset of images. While automatic writer identification/retrieval methods already provide promising results for many historical document types, papyri data is very challenging due to the fiber structures and severe artifacts. Thus, an important step for an improved writer identification is the preprocessing and feature sampling process. We investigate several methods and show that a good binarization is key to an improved writer identification in papyri writings. We focus mainly on writer retrieval using unsupervised feature methods based on traditional or self-supervised-based methods. It is, however, also comparable to the state of the art supervised deep learning-based method in the case of writer classification/re-identification.
TorMentor: Deterministic dynamic-path, data augmentations with fractals
Apr 07, 2022

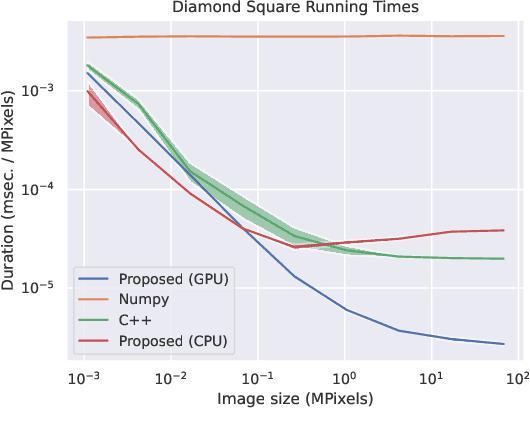
We propose the use of fractals as a means of efficient data augmentation. Specifically, we employ plasma fractals for adapting global image augmentation transformations into continuous local transforms. We formulate the diamond square algorithm as a cascade of simple convolution operations allowing efficient computation of plasma fractals on the GPU. We present the TorMentor image augmentation framework that is totally modular and deterministic across images and point-clouds. All image augmentation operations can be combined through pipelining and random branching to form flow networks of arbitrary width and depth. We demonstrate the efficiency of the proposed approach with experiments on document image segmentation (binarization) with the DIBCO datasets. The proposed approach demonstrates superior performance to traditional image augmentation techniques. Finally, we use extended synthetic binary text images in a self-supervision regiment and outperform the same model when trained with limited data and simple extensions.
How Will Your Tweet Be Received? Predicting the Sentiment Polarity of Tweet Replies
Apr 21, 2021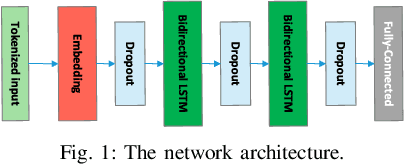

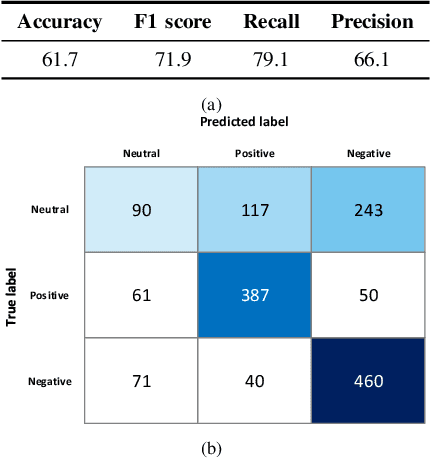
Twitter sentiment analysis, which often focuses on predicting the polarity of tweets, has attracted increasing attention over the last years, in particular with the rise of deep learning (DL). In this paper, we propose a new task: predicting the predominant sentiment among (first-order) replies to a given tweet. Therefore, we created RETWEET, a large dataset of tweets and replies manually annotated with sentiment labels. As a strong baseline, we propose a two-stage DL-based method: first, we create automatically labeled training data by applying a standard sentiment classifier to tweet replies and aggregating its predictions for each original tweet; our rationale is that individual errors made by the classifier are likely to cancel out in the aggregation step. Second, we use the automatically labeled data for supervised training of a neural network to predict reply sentiment from the original tweets. The resulting classifier is evaluated on the new RETWEET dataset, showing promising results, especially considering that it has been trained without any manually labeled data. Both the dataset and the baseline implementation are publicly available.
* Published in 2021 IEEE 15th International Conference on Semantic Computing (ICSC)
Differentiable Data Augmentation with Kornia
Nov 19, 2020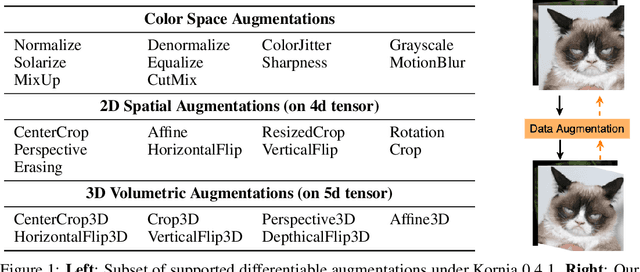
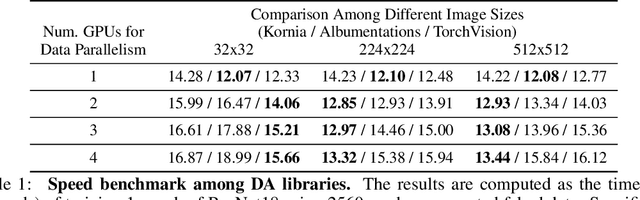
In this paper we present a review of the Kornia differentiable data augmentation (DDA) module for both for spatial (2D) and volumetric (3D) tensors. This module leverages differentiable computer vision solutions from Kornia, with an aim of integrating data augmentation (DA) pipelines and strategies to existing PyTorch components (e.g. autograd for differentiability, optim for optimization). In addition, we provide a benchmark comparing different DA frameworks and a short review for a number of approaches that make use of Kornia DDA.
ICFHR 2020 Competition on Image Retrieval for Historical Handwritten Fragments
Oct 20, 2020



This competition succeeds upon a line of competitions for writer and style analysis of historical document images. In particular, we investigate the performance of large-scale retrieval of historical document fragments in terms of style and writer identification. The analysis of historic fragments is a difficult challenge commonly solved by trained humanists. In comparison to previous competitions, we make the results more meaningful by addressing the issue of sample granularity and moving from writer to page fragment retrieval. The two approaches, style and author identification, provide information on what kind of information each method makes better use of and indirectly contribute to the interpretability of the participating method. Therefore, we created a large dataset consisting of more than 120 000 fragments. Although the most teams submitted methods based on convolutional neural networks, the winning entry achieves an mAP below 40%.
ICDAR 2019 Competition on Image Retrieval for Historical Handwritten Documents
Dec 08, 2019
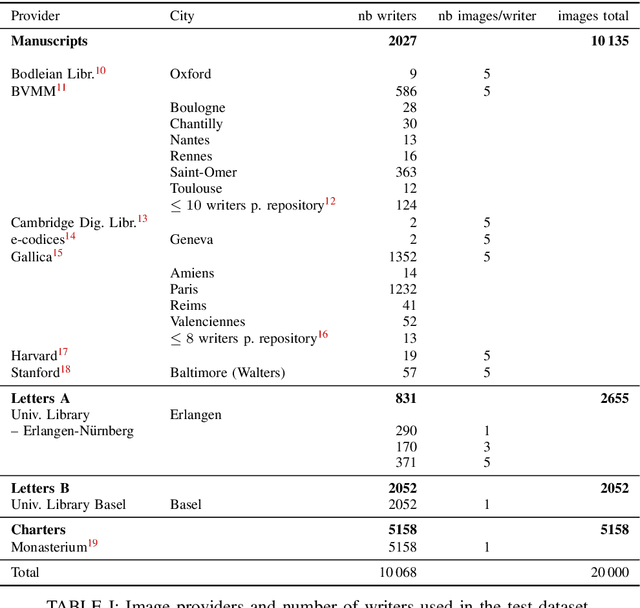
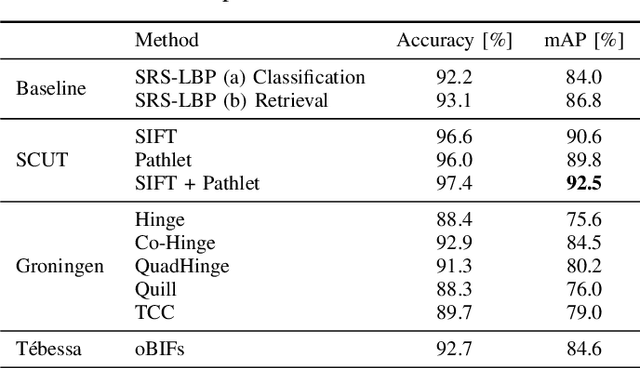
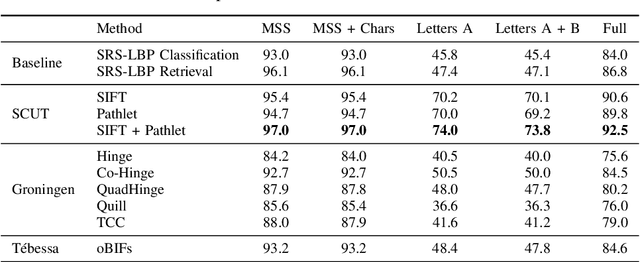
This competition investigates the performance of large-scale retrieval of historical document images based on writing style. Based on large image data sets provided by cultural heritage institutions and digital libraries, providing a total of 20 000 document images representing about 10 000 writers, divided in three types: writers of (i) manuscript books, (ii) letters, (iii) charters and legal documents. We focus on the task of automatic image retrieval to simulate common scenarios of humanities research, such as writer retrieval. The most teams submitted traditional methods not using deep learning techniques. The competition results show that a combination of methods is outperforming single methods. Furthermore, letters are much more difficult to retrieve than manuscripts.
Deep Generalized Max Pooling
Aug 14, 2019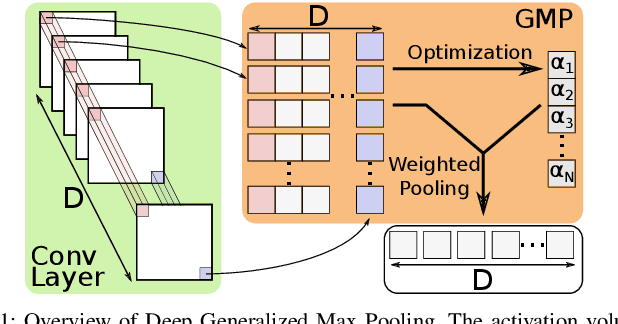


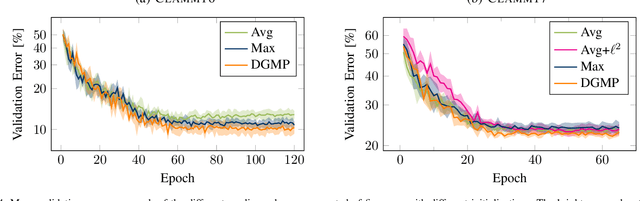
Global pooling layers are an essential part of Convolutional Neural Networks (CNN). They are used to aggregate activations of spatial locations to produce a fixed-size vector in several state-of-the-art CNNs. Global average pooling or global max pooling are commonly used for converting convolutional features of variable size images to a fix-sized embedding. However, both pooling layer types are computed spatially independent: each individual activation map is pooled and thus activations of different locations are pooled together. In contrast, we propose Deep Generalized Max Pooling that balances the contribution of all activations of a spatially coherent region by re-weighting all descriptors so that the impact of frequent and rare ones is equalized. We show that this layer is superior to both average and max pooling on the classification of Latin medieval manuscripts (CLAMM'16, CLAMM'17), as well as writer identification (Historical-WI'17).
Non-deterministic Behavior of Ranking-based Metrics when Evaluating Embeddings
Jun 19, 2018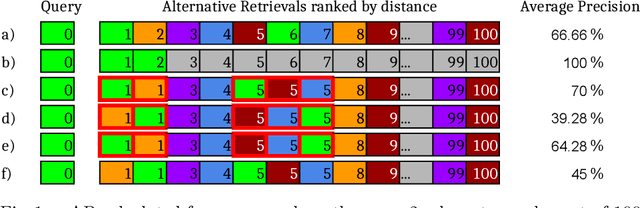
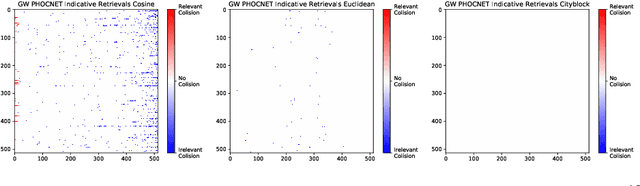


Embedding data into vector spaces is a very popular strategy of pattern recognition methods. When distances between embeddings are quantized, performance metrics become ambiguous. In this paper, we present an analysis of the ambiguity quantized distances introduce and provide bounds on the effect. We demonstrate that it can have a measurable effect in empirical data in state-of-the-art systems. We also approach the phenomenon from a computer security perspective and demonstrate how someone being evaluated by a third party can exploit this ambiguity and greatly outperform a random predictor without even access to the input data. We also suggest a simple solution making the performance metrics, which rely on ranking, totally deterministic and impervious to such exploits.