 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKornia-rs: A Low-Level 3D Computer Vision Library In Rust
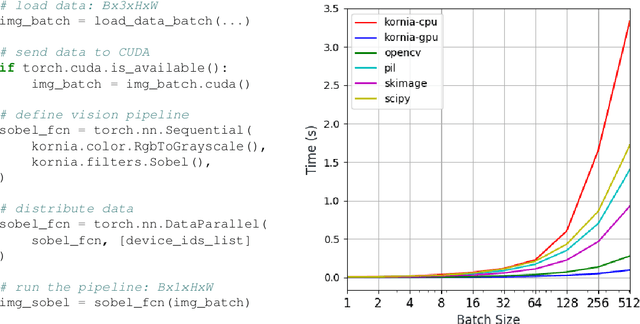
May 18, 2025We present \textit{kornia-rs}, a high-performance 3D computer vision library written entirely in native Rust, designed for safety-critical and real-time applications. Unlike C++-based libraries like OpenCV or wrapper-based solutions like OpenCV-Rust, \textit{kornia-rs} is built from the ground up to leverage Rust's ownership model and type system for memory and thread safety. \textit{kornia-rs} adopts a statically-typed tensor system and a modular set of crates, providing efficient image I/O, image processing and 3D operations. To aid cross-platform compatibility, \textit{kornia-rs} offers Python bindings, enabling seamless and efficient integration with Rust code. Empirical results show that \textit{kornia-rs} achieves a 3~ 5 times speedup in image transformation tasks over native Rust alternatives, while offering comparable performance to C++ wrapper-based libraries. In addition to 2D vision capabilities, \textit{kornia-rs} addresses a significant gap in the Rust ecosystem by providing a set of 3D computer vision operators. This paper presents the architecture and performance characteristics of \textit{kornia-rs}, demonstrating its effectiveness in real-world computer vision applications.
TorMentor: Deterministic dynamic-path, data augmentations with fractals
Apr 07, 2022
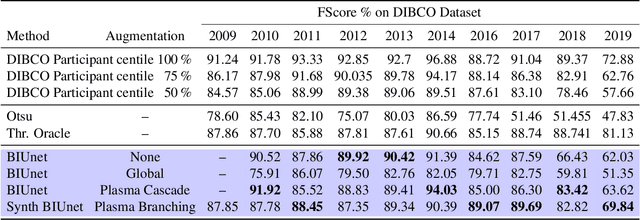

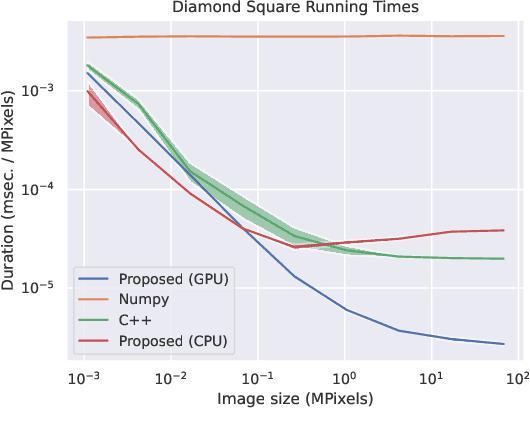
We propose the use of fractals as a means of efficient data augmentation. Specifically, we employ plasma fractals for adapting global image augmentation transformations into continuous local transforms. We formulate the diamond square algorithm as a cascade of simple convolution operations allowing efficient computation of plasma fractals on the GPU. We present the TorMentor image augmentation framework that is totally modular and deterministic across images and point-clouds. All image augmentation operations can be combined through pipelining and random branching to form flow networks of arbitrary width and depth. We demonstrate the efficiency of the proposed approach with experiments on document image segmentation (binarization) with the DIBCO datasets. The proposed approach demonstrates superior performance to traditional image augmentation techniques. Finally, we use extended synthetic binary text images in a self-supervision regiment and outperform the same model when trained with limited data and simple extensions.
Differentiable Data Augmentation with Kornia
Nov 19, 2020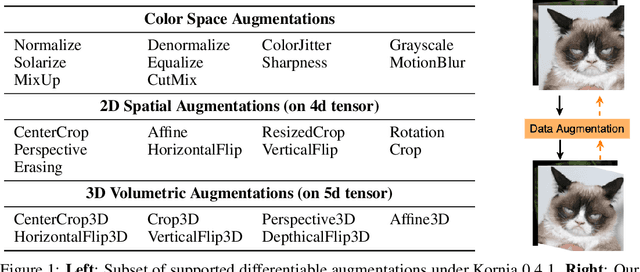
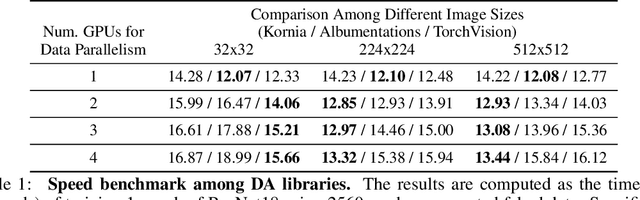
In this paper we present a review of the Kornia differentiable data augmentation (DDA) module for both for spatial (2D) and volumetric (3D) tensors. This module leverages differentiable computer vision solutions from Kornia, with an aim of integrating data augmentation (DA) pipelines and strategies to existing PyTorch components (e.g. autograd for differentiability, optim for optimization). In addition, we provide a benchmark comparing different DA frameworks and a short review for a number of approaches that make use of Kornia DDA.
Kornia: an Open Source Differentiable Computer Vision Library for PyTorch
Oct 09, 2019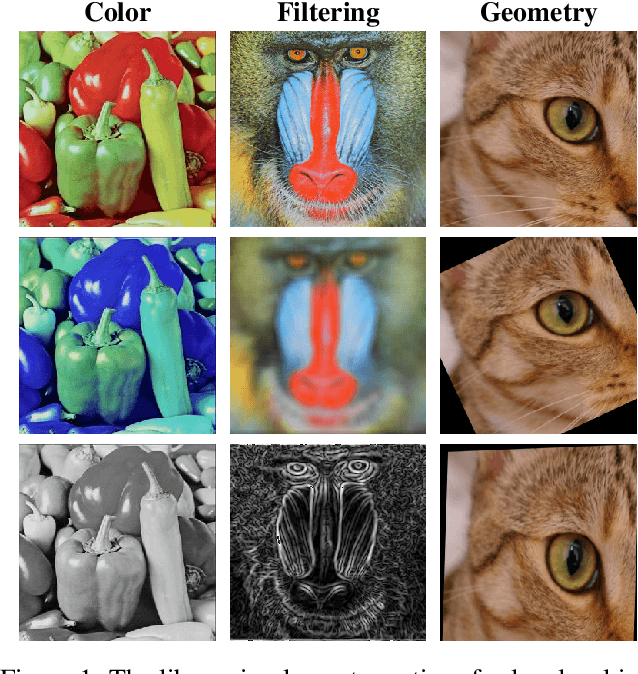

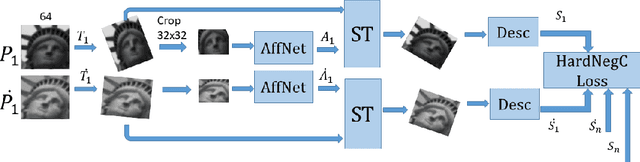
This work presents Kornia -- an open source computer vision library which consists of a set of differentiable routines and modules to solve generic computer vision problems. The package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions. Inspired by OpenCV, Kornia is composed of a set of modules containing operators that can be inserted inside neural networks to train models to perform image transformations, camera calibration, epipolar geometry, and low level image processing techniques, such as filtering and edge detection that operate directly on high dimensional tensor representations. Examples of classical vision problems implemented using our framework are provided including a benchmark comparing to existing vision libraries.
Dense Extreme Inception Network: Towards a Robust CNN Model for Edge Detection
Sep 04, 2019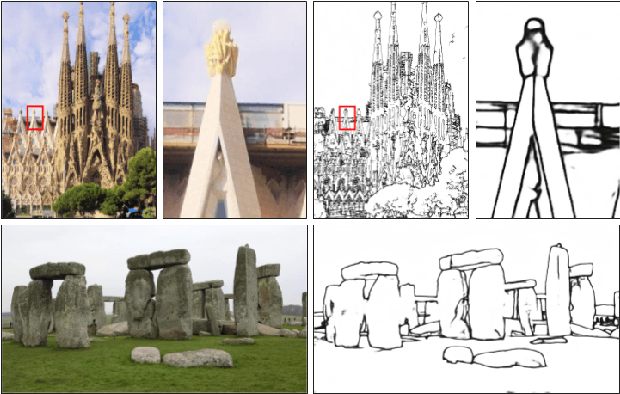


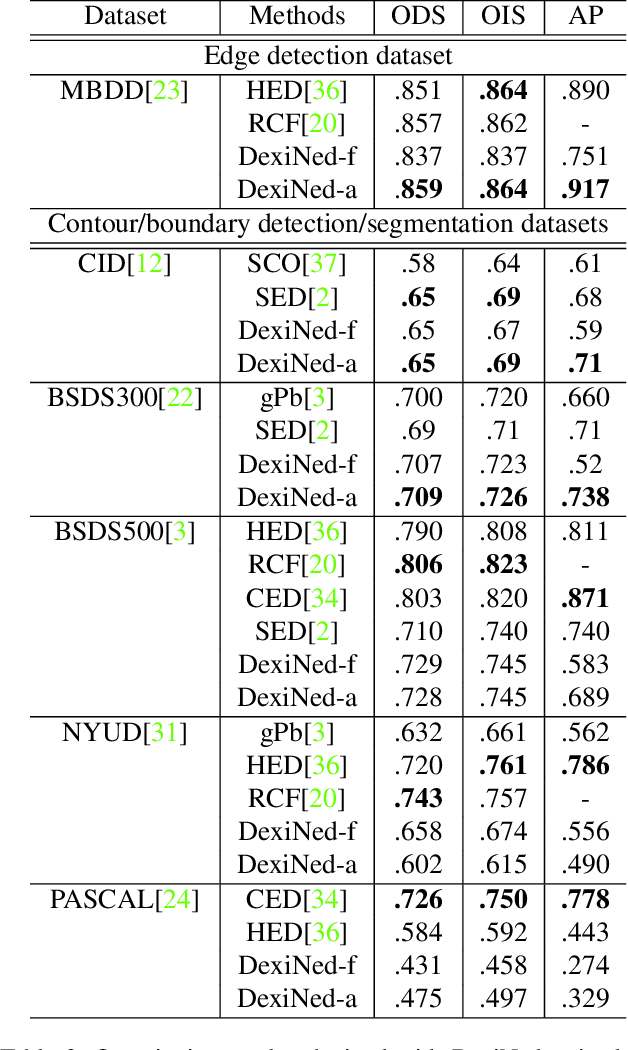
This paper proposes a Deep Learning based edge detector, which is inspired on both HED (Holistically-Nested Edge Detection) and Xception networks. The proposed approach generates thin edge-maps that are plausible for human eyes; it can be used in any edge detection task without previous training or fine tuning process. As a second contribution, a large dataset with carefully annotated edges has been generated. This dataset has been used for training the proposed approach as well as the state-of-the-art algorithms for comparisons. Quantitative and qualitative evaluations have been performed on different benchmarks showing improvements with the proposed method when F-measure of ODS and OIS are considered.
Key.Net: Keypoint Detection by Handcrafted and Learned CNN Filters
Apr 02, 2019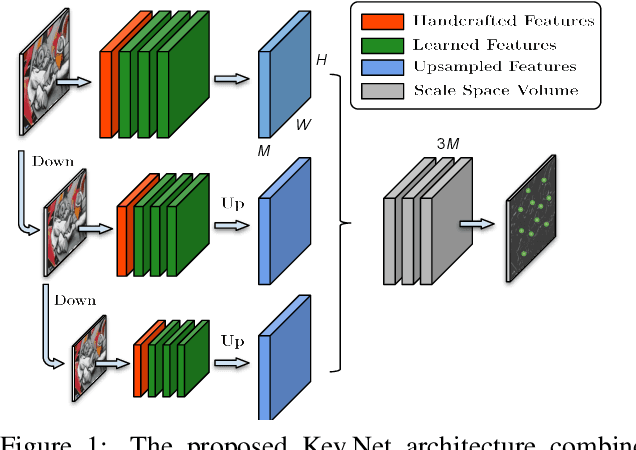
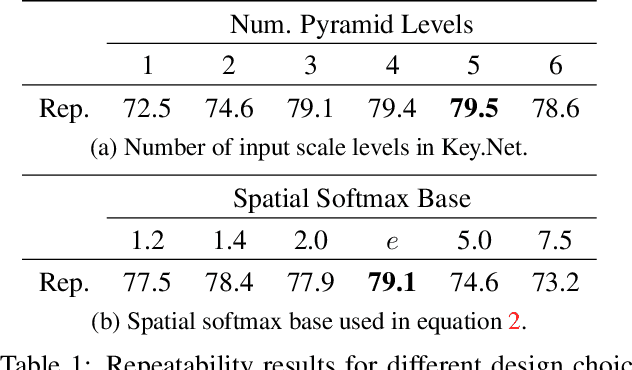
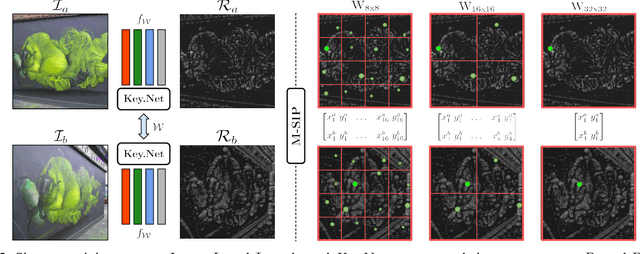
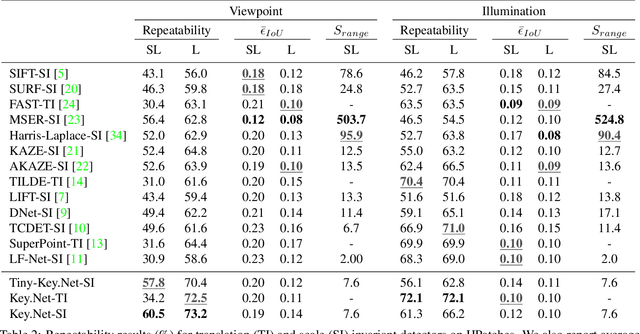
We introduce a novel approach for keypoint detection task that combines handcrafted and learned CNN filters within a shallow multi-scale architecture. Handcrafted filters provide anchor structures for learned filters, which localize, score and rank repeatable features. Scale-space representation is used within the network to extract keypoints at different levels. We design a loss function to detect robust features that exist across a range of scales and to maximize the repeatability score. Our Key.Net model is trained on data synthetically created from ImageNet and evaluated on HPatches benchmark. Results show that our approach outperforms state-of-the-art detectors in terms of repeatability, matching performance and complexity.