 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Implementing a Recommender System for Historical Research in the Humanities
Oct 28, 2024
This extended abstract describes the challenges in implementing recommender systems for digital archives in the humanities, focusing on Monasterium.net, a platform for historical legal documents. We discuss three key aspects: (i) the unique characteristics of so-called charters as items for recommendation, (ii) the complex multi-stakeholder environment, and (iii) the distinct information-seeking behavior of scholars in the humanities. By examining these factors, we aim to contribute to the development of more effective and tailored recommender systems for (digital) humanities research.
Value Identification in Multistakeholder Recommender Systems for Humanities and Historical Research: The Case of the Digital Archive Monasterium.net
Sep 26, 2024Recommender systems remain underutilized in humanities and historical research, despite their potential to enhance the discovery of cultural records. This paper offers an initial value identification of the multiple stakeholders that might be impacted by recommendations in Monasterium.net, a digital archive for historical legal documents. Specifically, we discuss the diverse values and objectives of its stakeholders, such as editors, aggregators, platform owners, researchers, publishers, and funding agencies. These in-depth insights into the potentially conflicting values of stakeholder groups allow designing and adapting recommender systems to enhance their usefulness for humanities and historical research. Additionally, our findings will support deeper engagement with additional stakeholders to refine value models and evaluation metrics for recommender systems in the given domains. Our conclusions are embedded in and applicable to other digital archives and a broader cultural heritage context.
Efficient Annotation of Medieval Charters
Jun 24, 2023Diplomatics, the analysis of medieval charters, is a major field of research in which paleography is applied. Annotating data, if performed by laymen, needs validation and correction by experts. In this paper, we propose an effective and efficient annotation approach for charter segmentation, essentially reducing it to object detection. This approach allows for a much more efficient use of the paleographer's time and produces results that can compete and even outperform pixel-level segmentation in some use cases. Further experiments shed light on how to design a class ontology in order to make the best use of annotators' time and effort. Exploiting the presence of calibration cards in the image, we further annotate the data with the physical length in pixels and train regression neural networks to predict it from image patches.
TorMentor: Deterministic dynamic-path, data augmentations with fractals
Apr 07, 2022
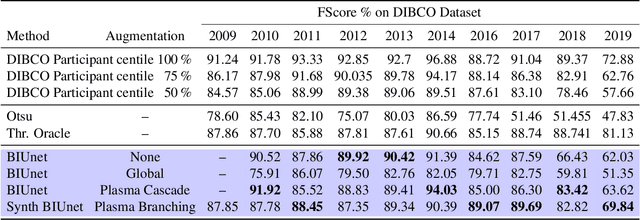

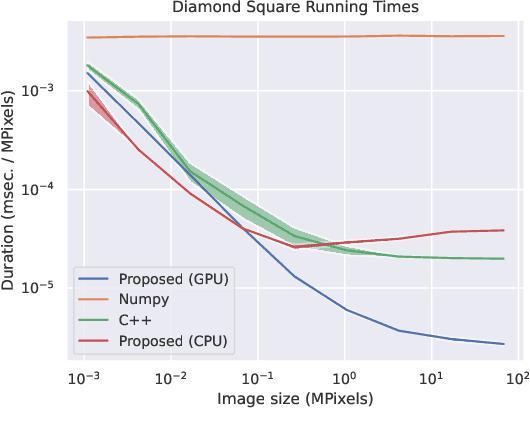
We propose the use of fractals as a means of efficient data augmentation. Specifically, we employ plasma fractals for adapting global image augmentation transformations into continuous local transforms. We formulate the diamond square algorithm as a cascade of simple convolution operations allowing efficient computation of plasma fractals on the GPU. We present the TorMentor image augmentation framework that is totally modular and deterministic across images and point-clouds. All image augmentation operations can be combined through pipelining and random branching to form flow networks of arbitrary width and depth. We demonstrate the efficiency of the proposed approach with experiments on document image segmentation (binarization) with the DIBCO datasets. The proposed approach demonstrates superior performance to traditional image augmentation techniques. Finally, we use extended synthetic binary text images in a self-supervision regiment and outperform the same model when trained with limited data and simple extensions.
The Notary in the Haystack -- Countering Class Imbalance in Document Processing with CNNs
Jul 15, 2020


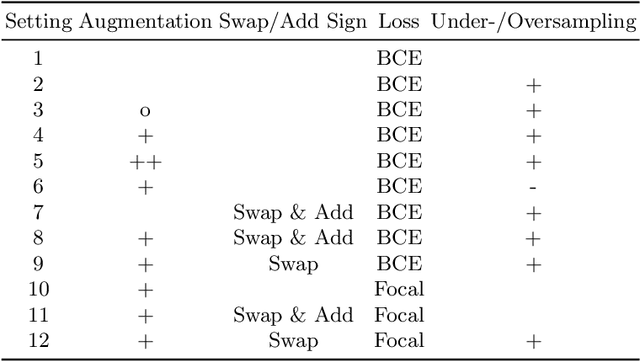
Notarial instruments are a category of documents. A notarial instrument can be distinguished from other documents by its notary sign, a prominent symbol in the certificate, which also allows to identify the document's issuer. Naturally, notarial instruments are underrepresented in regard to other documents. This makes a classification difficult because class imbalance in training data worsens the performance of Convolutional Neural Networks. In this work, we evaluate different countermeasures for this problem. They are applied to a binary classification and a segmentation task on a collection of medieval documents. In classification, notarial instruments are distinguished from other documents, while the notary sign is separated from the certificate in the segmentation task. We evaluate different techniques, such as data augmentation, under- and oversampling, as well as regularizing with focal loss. The combination of random minority oversampling and data augmentation leads to the best performance. In segmentation, we evaluate three loss-functions and their combinations, where only class-weighted dice loss was able to segment the notary sign sufficiently.