 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Morphology for Historical Script Metrological Analysis
Jun 08, 2026Advances in handwritten text recognition have enabled large-scale transcription of historical documents, but still provide limited access to interpretable visual measurements for paleography, the study of historical scripts. In this paper, our main insight is that morphological script analysis, in particular the capacity to learn character prototypes from line-level transcriptions, enables the definition of scalable, meaningful, and stable paleographic measurements. More precisely, we leverage a transformer-based detection architecture together with a prototype-based line reconstruction module to learn prototypical characters and their occurrence, deformation, and positioning. Our contributions are twofold. First, we introduce a deep architecture and learning methodology that enables efficient character modeling with only line-level transcription supervision, significantly improving over the Learnable Typewriter baseline and enabling accurate character bounding box prediction, unlocking its potential for paleographic measurements. Second, we introduce and demonstrate the paleographical relevance of automatic measurements enabled by our architecture for characters, bi-grams, and spaces between graphical units. For this demonstration, we extend the annotations of the codex Paris, BnF, fr. 2813, commissioned in the late fourteenth century by Charles V and copied by four hands, to 160 pages. We visualize our measurements over these pages, showing how they enable us not only to differentiate graphical profiles, but also to discover and analyze subtle variations. This case study outlines the scalability of our approach and its frugality in terms of required training data, since a single column of text is sufficient to compute our measurements on each of the 160 pages. Data and code are publicly available at: https://malamatenia.github.io/morphology4metrology-analysis.
HORAE: an annotated dataset of books of hours
Dec 01, 2020


We introduce in this paper a new dataset of annotated pages from books of hours, a type of handwritten prayer books owned and used by rich lay people in the late middle ages. The dataset was created for conducting historical research on the evolution of the religious mindset in Europe at this period since the book of hours represent one of the major sources of information thanks both to their rich illustrations and the different types of religious sources they contain. We first describe how the corpus was collected and manually annotated then present the evaluation of a state-of-the-art system for text line detection and for zone detection and typing. The corpus is freely available for research.
ICFHR 2020 Competition on Image Retrieval for Historical Handwritten Fragments
Oct 20, 2020



This competition succeeds upon a line of competitions for writer and style analysis of historical document images. In particular, we investigate the performance of large-scale retrieval of historical document fragments in terms of style and writer identification. The analysis of historic fragments is a difficult challenge commonly solved by trained humanists. In comparison to previous competitions, we make the results more meaningful by addressing the issue of sample granularity and moving from writer to page fragment retrieval. The two approaches, style and author identification, provide information on what kind of information each method makes better use of and indirectly contribute to the interpretability of the participating method. Therefore, we created a large dataset consisting of more than 120 000 fragments. Although the most teams submitted methods based on convolutional neural networks, the winning entry achieves an mAP below 40%.
ICDAR 2019 Competition on Image Retrieval for Historical Handwritten Documents
Dec 08, 2019
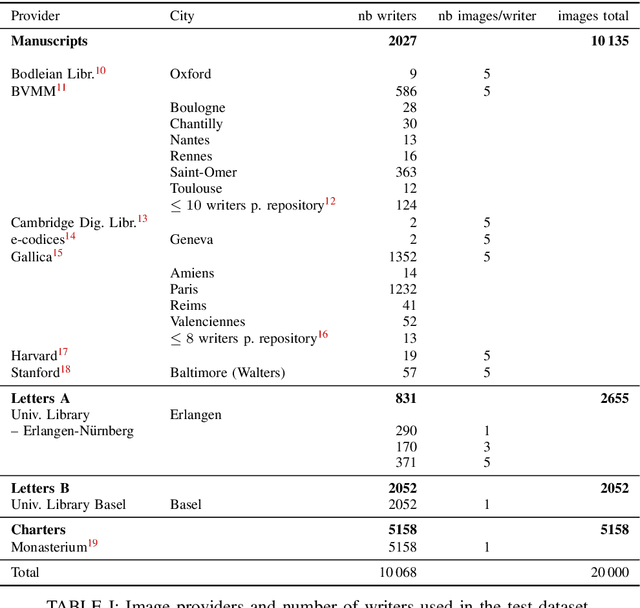
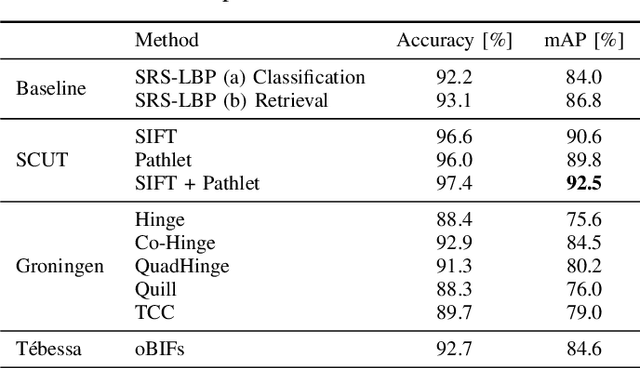
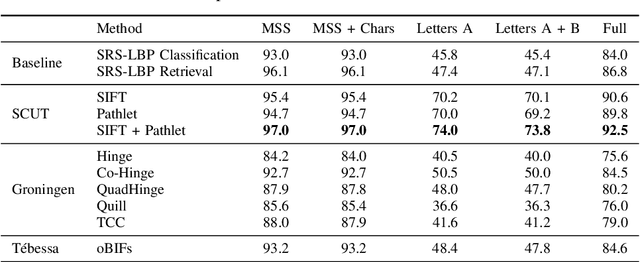
This competition investigates the performance of large-scale retrieval of historical document images based on writing style. Based on large image data sets provided by cultural heritage institutions and digital libraries, providing a total of 20 000 document images representing about 10 000 writers, divided in three types: writers of (i) manuscript books, (ii) letters, (iii) charters and legal documents. We focus on the task of automatic image retrieval to simulate common scenarios of humanities research, such as writer retrieval. The most teams submitted traditional methods not using deep learning techniques. The competition results show that a combination of methods is outperforming single methods. Furthermore, letters are much more difficult to retrieve than manuscripts.