 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSL4SAR: Self-Supervised Learning for Glacier Calving Front Extraction from SAR Imagery
Jul 02, 2025Glaciers are losing ice mass at unprecedented rates, increasing the need for accurate, year-round monitoring to understand frontal ablation, particularly the factors driving the calving process. Deep learning models can extract calving front positions from Synthetic Aperture Radar imagery to track seasonal ice losses at the calving fronts of marine- and lake-terminating glaciers. The current state-of-the-art model relies on ImageNet-pretrained weights. However, they are suboptimal due to the domain shift between the natural images in ImageNet and the specialized characteristics of remote sensing imagery, in particular for Synthetic Aperture Radar imagery. To address this challenge, we propose two novel self-supervised multimodal pretraining techniques that leverage SSL4SAR, a new unlabeled dataset comprising 9,563 Sentinel-1 and 14 Sentinel-2 images of Arctic glaciers, with one optical image per glacier in the dataset. Additionally, we introduce a novel hybrid model architecture that combines a Swin Transformer encoder with a residual Convolutional Neural Network (CNN) decoder. When pretrained on SSL4SAR, this model achieves a mean distance error of 293 m on the "CAlving Fronts and where to Find thEm" (CaFFe) benchmark dataset, outperforming the prior best model by 67 m. Evaluating an ensemble of the proposed model on a multi-annotator study of the benchmark dataset reveals a mean distance error of 75 m, approaching the human performance of 38 m. This advancement enables precise monitoring of seasonal changes in glacier calving fronts.
Nuremberg Letterbooks: A Multi-Transcriptional Dataset of Early 15th Century Manuscripts for Document Analysis
Nov 11, 2024



Most datasets in the field of document analysis utilize highly standardized labels, which, while simplifying specific tasks, often produce outputs that are not directly applicable to humanities research. In contrast, the Nuremberg Letterbooks dataset, which comprises historical documents from the early 15th century, addresses this gap by providing multiple types of transcriptions and accompanying metadata. This approach allows for developing methods that are more closely aligned with the needs of the humanities. The dataset includes 4 books containing 1711 labeled pages written by 10 scribes. Three types of transcriptions are provided for handwritten text recognition: Basic, diplomatic, and regularized. For the latter two, versions with and without expanded abbreviations are also available. A combination of letter ID and writer ID supports writer identification due to changing writers within pages. In the technical validation, we established baselines for various tasks, demonstrating data consistency and providing benchmarks for future research to build upon.
Zero-Shot Paragraph-level Handwriting Imitation with Latent Diffusion Models
Sep 01, 2024



The imitation of cursive handwriting is mainly limited to generating handwritten words or lines. Multiple synthetic outputs must be stitched together to create paragraphs or whole pages, whereby consistency and layout information are lost. To close this gap, we propose a method for imitating handwriting at the paragraph level that also works for unseen writing styles. Therefore, we introduce a modified latent diffusion model that enriches the encoder-decoder mechanism with specialized loss functions that explicitly preserve the style and content. We enhance the attention mechanism of the diffusion model with adaptive 2D positional encoding and the conditioning mechanism to work with two modalities simultaneously: a style image and the target text. This significantly improves the realism of the generated handwriting. Our approach sets a new benchmark in our comprehensive evaluation. It outperforms all existing imitation methods at both line and paragraph levels, considering combined style and content preservation.
A Fair Evaluation of Various Deep Learning-Based Document Image Binarization Approaches
Jan 22, 2024Binarization of document images is an important pre-processing step in the field of document analysis. Traditional image binarization techniques usually rely on histograms or local statistics to identify a valid threshold to differentiate between different aspects of the image. Deep learning techniques are able to generate binarized versions of the images by learning context-dependent features that are less error-prone to degradation typically occurring in document images. In recent years, many deep learning-based methods have been developed for document binarization. But which one to choose? There have been no studies that compare these methods rigorously. Therefore, this work focuses on the evaluation of different deep learning-based methods under the same evaluation protocol. We evaluate them on different Document Image Binarization Contest (DIBCO) datasets and obtain very heterogeneous results. We show that the DE-GAN model was able to perform better compared to other models when evaluated on the DIBCO2013 dataset while DP-LinkNet performed best on the DIBCO2017 dataset. The 2-StageGAN performed best on the DIBCO2018 dataset while SauvolaNet outperformed the others on the DIBCO2019 challenge. Finally, we make the code, all models and evaluation publicly available (https://github.com/RichSu95/Document_Binarization_Collection) to ensure reproducibility and simplify future binarization evaluations.
* DAS 2022
Combining OCR Models for Reading Early Modern Printed Books
May 11, 2023In this paper, we investigate the usage of fine-grained font recognition on OCR for books printed from the 15th to the 18th century. We used a newly created dataset for OCR of early printed books for which fonts are labeled with bounding boxes. We know not only the font group used for each character, but the locations of font changes as well. In books of this period, we frequently find font group changes mid-line or even mid-word that indicate changes in language. We consider 8 different font groups present in our corpus and investigate 13 different subsets: the whole dataset and text lines with a single font, multiple fonts, Roman fonts, Gothic fonts, and each of the considered fonts, respectively. We show that OCR performance is strongly impacted by font style and that selecting fine-tuned models with font group recognition has a very positive impact on the results. Moreover, we developed a system using local font group recognition in order to combine the output of multiple font recognition models, and show that while slower, this approach performs better not only on text lines composed of multiple fonts but on the ones containing a single font only as well.
Writer Retrieval and Writer Identification in Greek Papyri
Dec 15, 2022The analysis of digitized historical manuscripts is typically addressed by paleographic experts. Writer identification refers to the classification of known writers while writer retrieval seeks to find the writer by means of image similarity in a dataset of images. While automatic writer identification/retrieval methods already provide promising results for many historical document types, papyri data is very challenging due to the fiber structures and severe artifacts. Thus, an important step for an improved writer identification is the preprocessing and feature sampling process. We investigate several methods and show that a good binarization is key to an improved writer identification in papyri writings. We focus mainly on writer retrieval using unsupervised feature methods based on traditional or self-supervised-based methods. It is, however, also comparable to the state of the art supervised deep learning-based method in the case of writer classification/re-identification.
SmartPatch: Improving Handwritten Word Imitation with Patch Discriminators
May 21, 2021
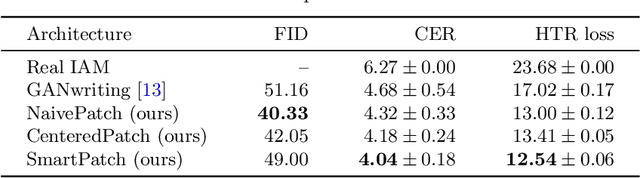
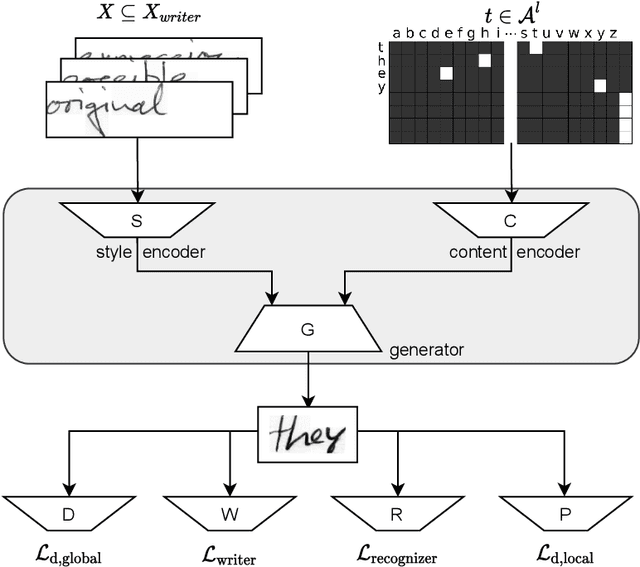

As of recent generative adversarial networks have allowed for big leaps in the realism of generated images in diverse domains, not the least of which being handwritten text generation. The generation of realistic-looking hand-written text is important because it can be used for data augmentation in handwritten text recognition (HTR) systems or human-computer interaction. We propose SmartPatch, a new technique increasing the performance of current state-of-the-art methods by augmenting the training feedback with a tailored solution to mitigate pen-level artifacts. We combine the well-known patch loss with information gathered from the parallel trained handwritten text recognition system and the separate characters of the word. This leads to a more enhanced local discriminator and results in more realistic and higher-quality generated handwritten words.
Spatio-Temporal Handwriting Imitation
Mar 24, 2020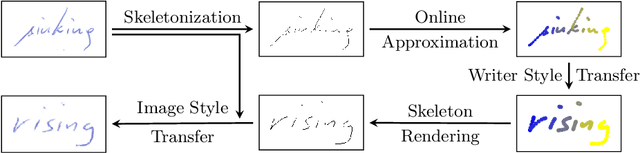

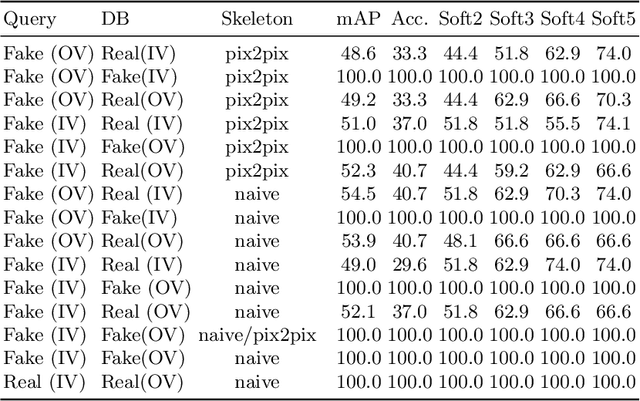
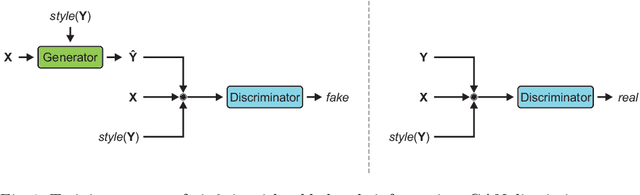
Most people think that their handwriting is unique and cannot be imitated by machines, especially not using completely new content. Current cursive handwriting synthesis is visually limited or needs user interaction. We show that subdividing the process into smaller subtasks makes it possible to imitate someone's handwriting with a high chance to be visually indistinguishable for humans. Therefore, a given handwritten sample will be used as the target style. This sample is transferred to an online sequence. Then, a method for online handwriting synthesis is used to produce a new realistic-looking text primed with the online input sequence. This new text is then rendered and style-adapted to the input pen. We show the effectiveness of the pipeline by generating in- and out-of-vocabulary handwritten samples that are validated in a comprehensive user study. Additionally, we show that also a typical writer identification system can partially be fooled by the created fake handwritings.
Weakly Supervised Segmentation of Cracks on Solar Cells using Normalized Lp Norm
Jan 30, 2020
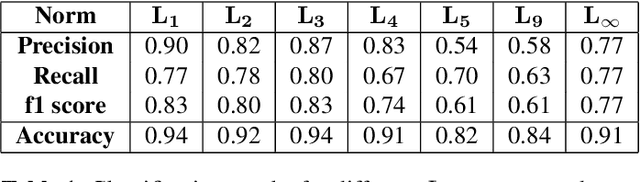
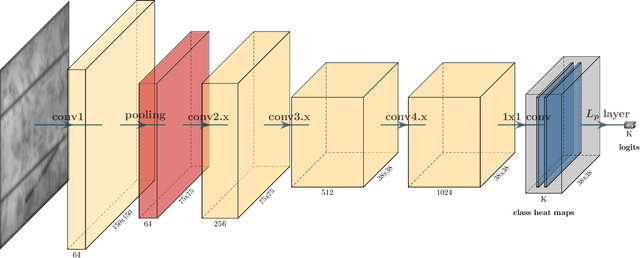

Photovoltaic is one of the most important renewable energy sources for dealing with world-wide steadily increasing energy consumption. This raises the demand for fast and scalable automatic quality management during production and operation. However, the detection and segmentation of cracks on electroluminescence (EL) images of mono- or polycrystalline solar modules is a challenging task. In this work, we propose a weakly supervised learning strategy that only uses image-level annotations to obtain a method that is capable of segmenting cracks on EL images of solar cells. We use a modified ResNet-50 to derive a segmentation from network activation maps. We use defect classification as a surrogate task to train the network. To this end, we apply normalized Lp normalization to aggregate the activation maps into single scores for classification. In addition, we provide a study how different parameterizations of the normalized Lp layer affect the segmentation performance. This approach shows promising results for the given task. However, we think that the method has the potential to solve other weakly supervised segmentation problems as well.