 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't only Feel Read: Using Scene text to understand advertisements
Jun 26, 2018


We propose a framework for automated classification of Advertisement Images, using not just Visual features but also Textual cues extracted from embedded text. Our approach takes inspiration from the assumption that Ad images contain meaningful textual content, that can provide discriminative semantic interpretetion, and can thus aid in classifcation tasks. To this end, we develop a framework using off-the-shelf components, and demonstrate the effectiveness of Textual cues in semantic Classfication tasks.
Learning Cross-Modal Deep Embeddings for Multi-Object Image Retrieval using Text and Sketch
Apr 28, 2018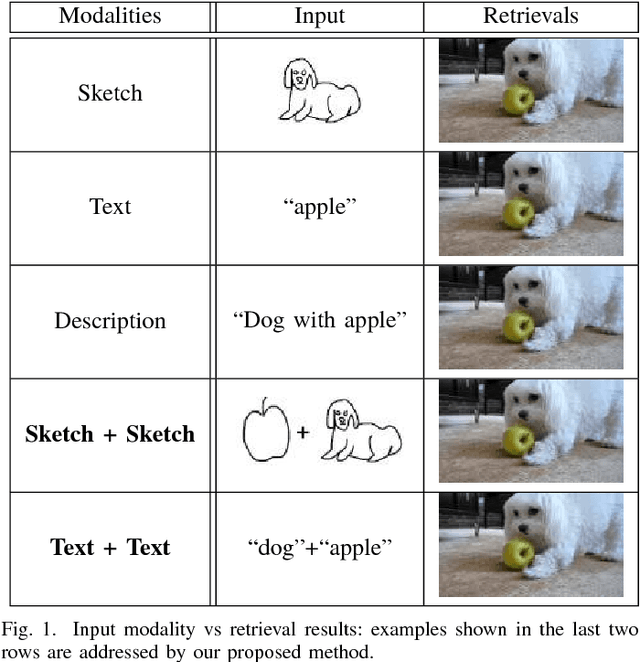
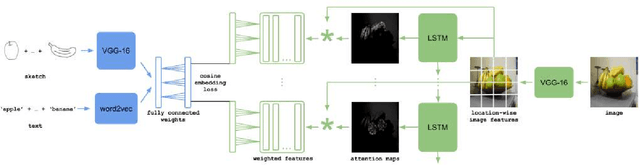

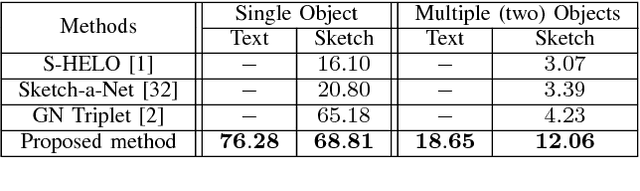
In this work we introduce a cross modal image retrieval system that allows both text and sketch as input modalities for the query. A cross-modal deep network architecture is formulated to jointly model the sketch and text input modalities as well as the the image output modality, learning a common embedding between text and images and between sketches and images. In addition, an attention model is used to selectively focus the attention on the different objects of the image, allowing for retrieval with multiple objects in the query. Experiments show that the proposed method performs the best in both single and multiple object image retrieval in standard datasets.
SigNet: Convolutional Siamese Network for Writer Independent Offline Signature Verification
Sep 30, 2017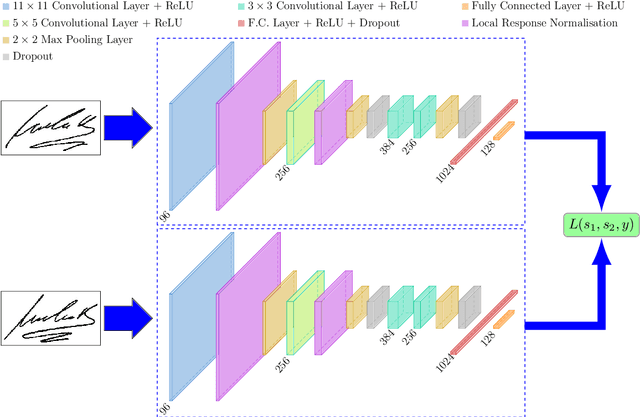


Offline signature verification is one of the most challenging tasks in biometrics and document forensics. Unlike other verification problems, it needs to model minute but critical details between genuine and forged signatures, because a skilled falsification might often resembles the real signature with small deformation. This verification task is even harder in writer independent scenarios which is undeniably fiscal for realistic cases. In this paper, we model an offline writer independent signature verification task with a convolutional Siamese network. Siamese networks are twin networks with shared weights, which can be trained to learn a feature space where similar observations are placed in proximity. This is achieved by exposing the network to a pair of similar and dissimilar observations and minimizing the Euclidean distance between similar pairs while simultaneously maximizing it between dissimilar pairs. Experiments conducted on cross-domain datasets emphasize the capability of our network to model forgery in different languages (scripts) and handwriting styles. Moreover, our designed Siamese network, named SigNet, exceeds the state-of-the-art results on most of the benchmark signature datasets, which paves the way for further research in this direction.
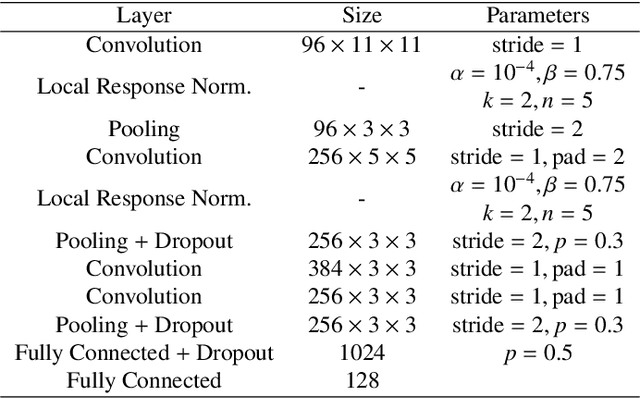
Visual attention models for scene text recognition
Jun 05, 2017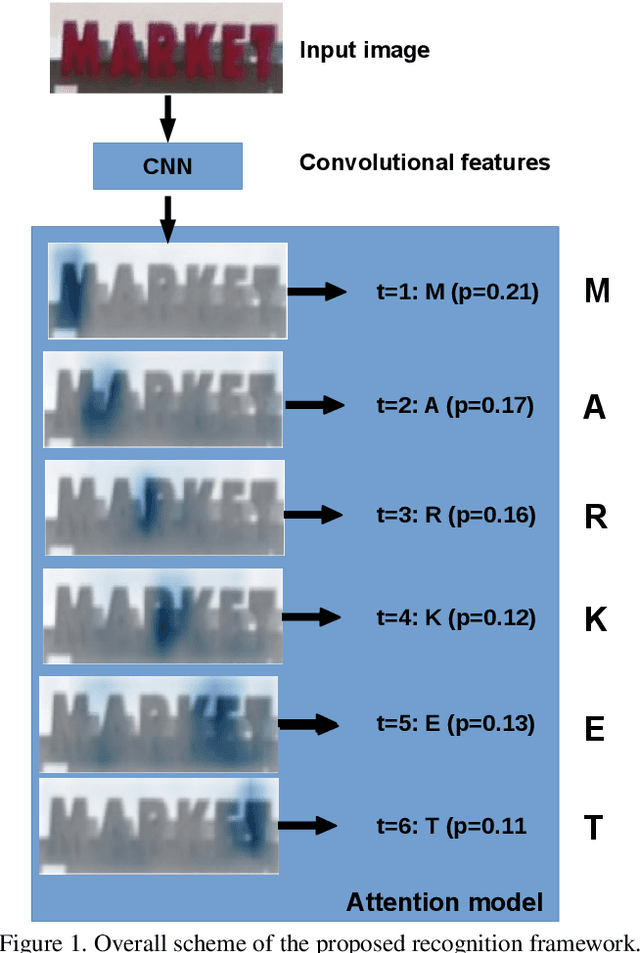
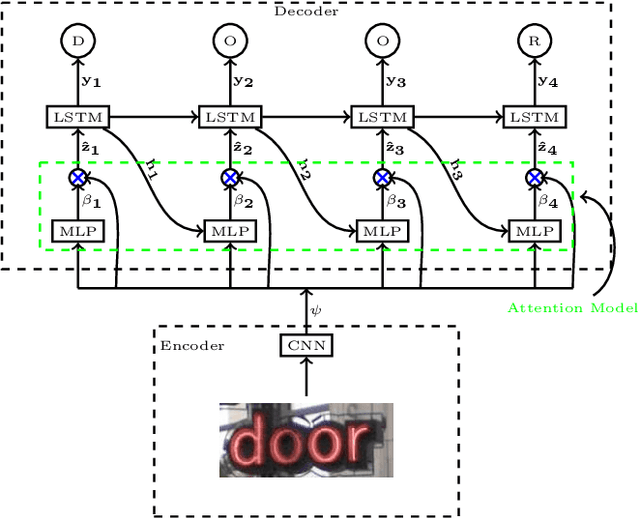
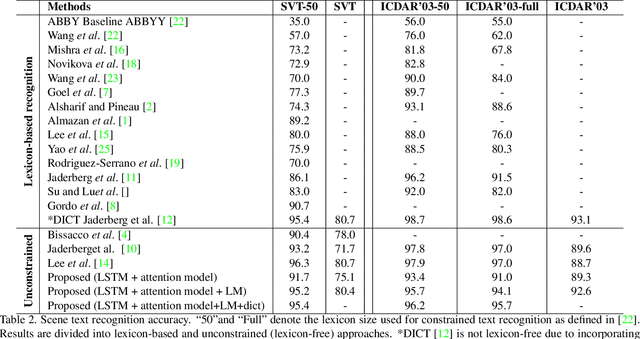
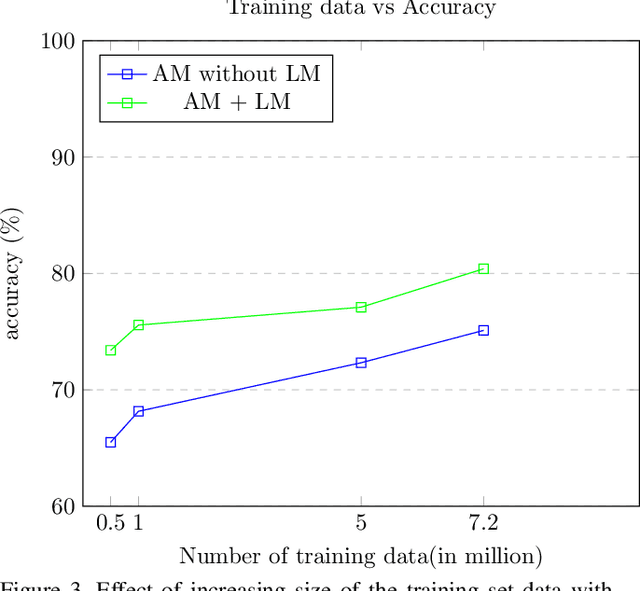
In this paper we propose an approach to lexicon-free recognition of text in scene images. Our approach relies on a LSTM-based soft visual attention model learned from convolutional features. A set of feature vectors are derived from an intermediate convolutional layer corresponding to different areas of the image. This permits encoding of spatial information into the image representation. In this way, the framework is able to learn how to selectively focus on different parts of the image. At every time step the recognizer emits one character using a weighted combination of the convolutional feature vectors according to the learned attention model. Training can be done end-to-end using only word level annotations. In addition, we show that modifying the beam search algorithm by integrating an explicit language model leads to significantly better recognition results. We validate the performance of our approach on standard SVT and ICDAR'03 scene text datasets, showing state-of-the-art performance in unconstrained text recognition.
Query by String word spotting based on character bi-gram indexing
May 28, 2015

In this paper we propose a segmentation-free query by string word spotting method. Both the documents and query strings are encoded using a recently proposed word representa- tion that projects images and strings into a common atribute space based on a pyramidal histogram of characters(PHOC). These attribute models are learned using linear SVMs over the Fisher Vector representation of the images along with the PHOC labels of the corresponding strings. In order to search through the whole page, document regions are indexed per character bi- gram using a similar attribute representation. On top of that, we propose an integral image representation of the document using a simplified version of the attribute model for efficient computation. Finally we introduce a re-ranking step in order to boost retrieval performance. We show state-of-the-art results for segmentation-free query by string word spotting in single-writer and multi-writer standard datasets