 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual attention models for scene text recognition
Paper and Code
Jun 05, 2017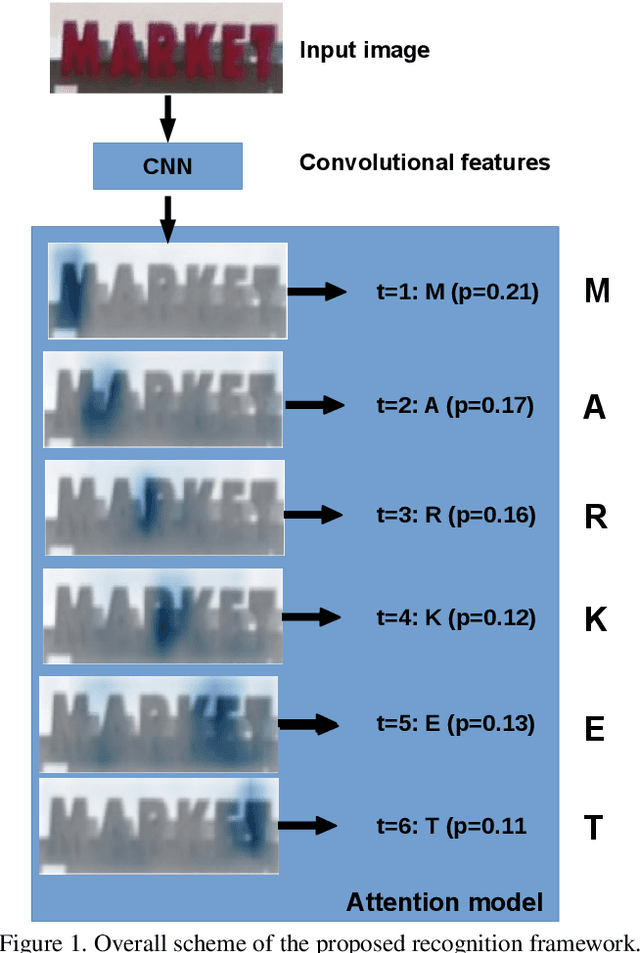
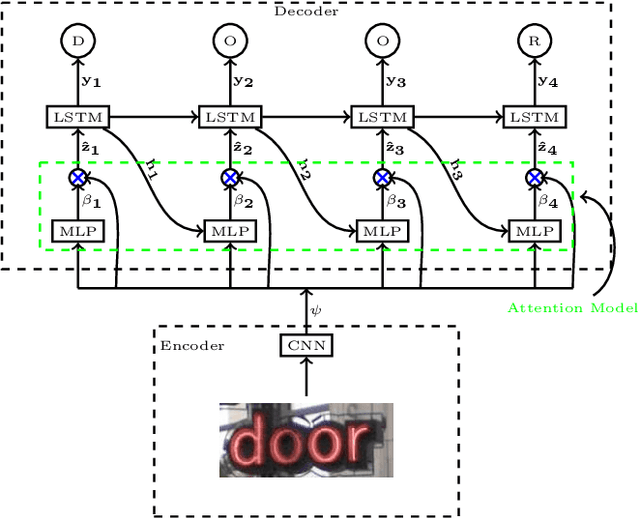
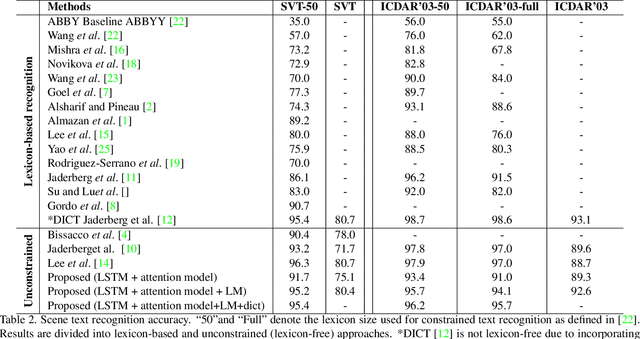
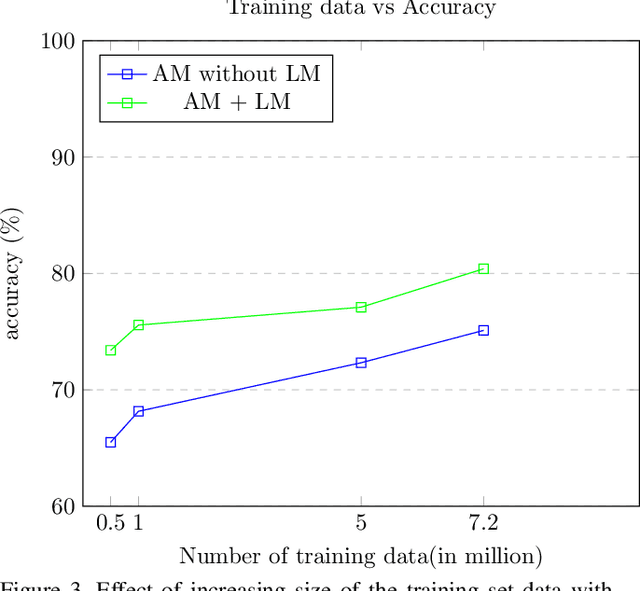
In this paper we propose an approach to lexicon-free recognition of text in scene images. Our approach relies on a LSTM-based soft visual attention model learned from convolutional features. A set of feature vectors are derived from an intermediate convolutional layer corresponding to different areas of the image. This permits encoding of spatial information into the image representation. In this way, the framework is able to learn how to selectively focus on different parts of the image. At every time step the recognizer emits one character using a weighted combination of the convolutional feature vectors according to the learned attention model. Training can be done end-to-end using only word level annotations. In addition, we show that modifying the beam search algorithm by integrating an explicit language model leads to significantly better recognition results. We validate the performance of our approach on standard SVT and ICDAR'03 scene text datasets, showing state-of-the-art performance in unconstrained text recognition.