Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of the Effect of Improper Segmentation on Word Spotting
Paper and Code
Apr 21, 2016
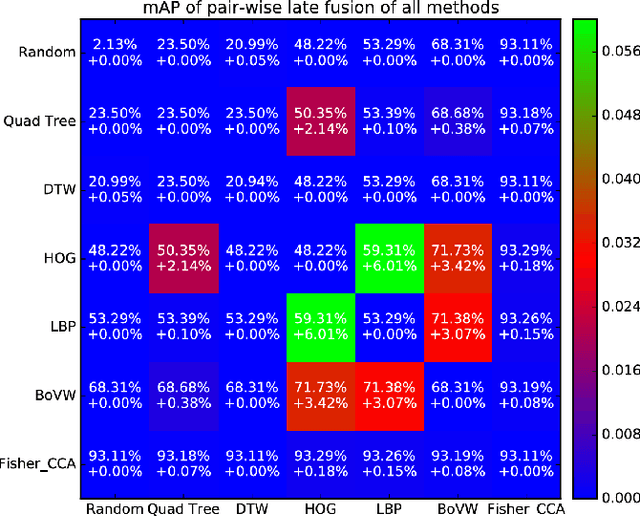

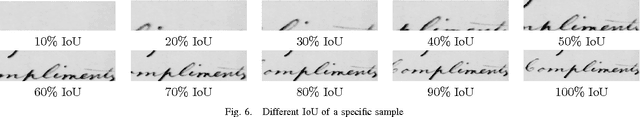
Word spotting is an important recognition task in historical document analysis. In most cases methods are developed and evaluated assuming perfect word segmentations. In this paper we propose an experimental framework to quantify the effect of goodness of word segmentation has on the performance achieved by word spotting methods in identical unbiased conditions. The framework consists of generating systematic distortions on segmentation and retrieving the original queries from the distorted dataset. We apply the framework on the George Washington and Barcelona Marriage Dataset and on several established and state-of-the-art methods. The experiments allow for an estimate of the end-to-end performance of word spotting methods.
View paper on