 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs An Image Worth Five Sentences? A New Look into Semantics for Image-Text Matching
Paper and Code
Oct 06, 2021


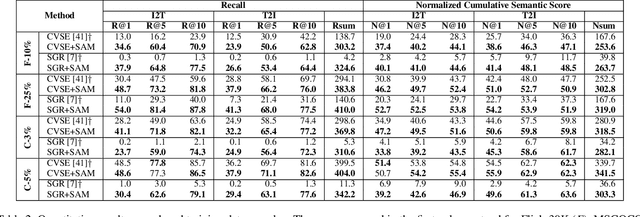
The task of image-text matching aims to map representations from different modalities into a common joint visual-textual embedding. However, the most widely used datasets for this task, MSCOCO and Flickr30K, are actually image captioning datasets that offer a very limited set of relationships between images and sentences in their ground-truth annotations. This limited ground truth information forces us to use evaluation metrics based on binary relevance: given a sentence query we consider only one image as relevant. However, many other relevant images or captions may be present in the dataset. In this work, we propose two metrics that evaluate the degree of semantic relevance of retrieved items, independently of their annotated binary relevance. Additionally, we incorporate a novel strategy that uses an image captioning metric, CIDEr, to define a Semantic Adaptive Margin (SAM) to be optimized in a standard triplet loss. By incorporating our formulation to existing models, a \emph{large} improvement is obtained in scenarios where available training data is limited. We also demonstrate that the performance on the annotated image-caption pairs is maintained while improving on other non-annotated relevant items when employing the full training set. Code with our metrics and adaptive margin formulation will be made public.