 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeST-KeyS: Self-Supervised Transformer for Keyword Spotting in Historical Handwritten Documents
Mar 06, 2023



Keyword spotting (KWS) in historical documents is an important tool for the initial exploration of digitized collections. Nowadays, the most efficient KWS methods are relying on machine learning techniques that require a large amount of annotated training data. However, in the case of historical manuscripts, there is a lack of annotated corpus for training. To handle the data scarcity issue, we investigate the merits of the self-supervised learning to extract useful representations of the input data without relying on human annotations and then using these representations in the downstream task. We propose ST-KeyS, a masked auto-encoder model based on vision transformers where the pretraining stage is based on the mask-and-predict paradigm, without the need of labeled data. In the fine-tuning stage, the pre-trained encoder is integrated into a siamese neural network model that is fine-tuned to improve feature embedding from the input images. We further improve the image representation using pyramidal histogram of characters (PHOC) embedding to create and exploit an intermediate representation of images based on text attributes. In an exhaustive experimental evaluation on three widely used benchmark datasets (Botany, Alvermann Konzilsprotokolle and George Washington), the proposed approach outperforms state-of-the-art methods trained on the same datasets.
DocEnTr: An End-to-End Document Image Enhancement Transformer
Jan 25, 2022Document images can be affected by many degradation scenarios, which cause recognition and processing difficulties. In this age of digitization, it is important to denoise them for proper usage. To address this challenge, we present a new encoder-decoder architecture based on vision transformers to enhance both machine-printed and handwritten document images, in an end-to-end fashion. The encoder operates directly on the pixel patches with their positional information without the use of any convolutional layers, while the decoder reconstructs a clean image from the encoded patches. Conducted experiments show a superiority of the proposed model compared to the state-of the-art methods on several DIBCO benchmarks. Code and models will be publicly available at: \url{https://github.com/dali92002/DocEnTR}.
Enhance to Read Better: An Improved Generative Adversarial Network for Handwritten Document Image Enhancement
May 26, 2021
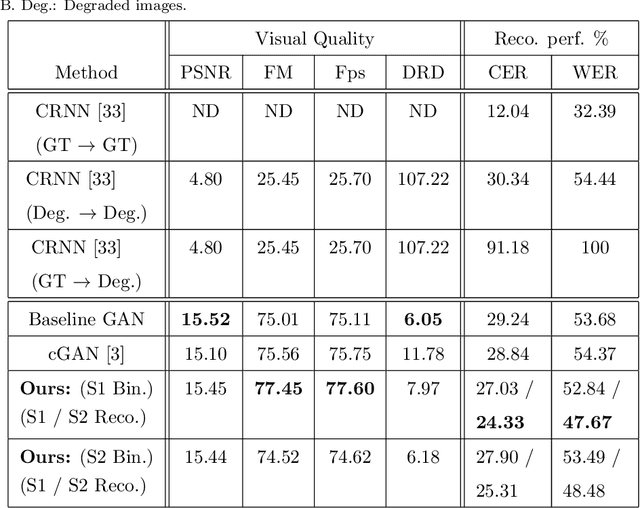
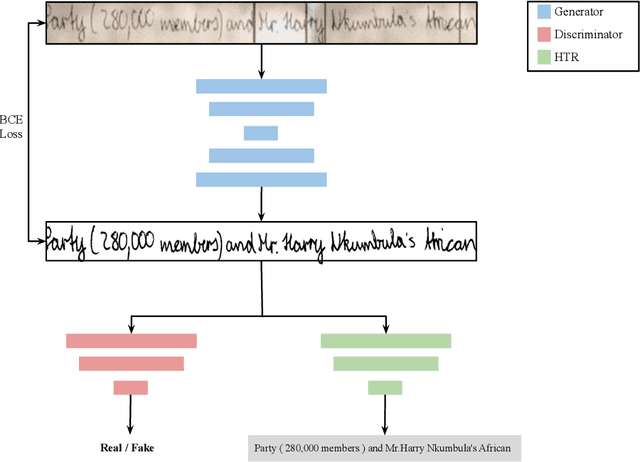
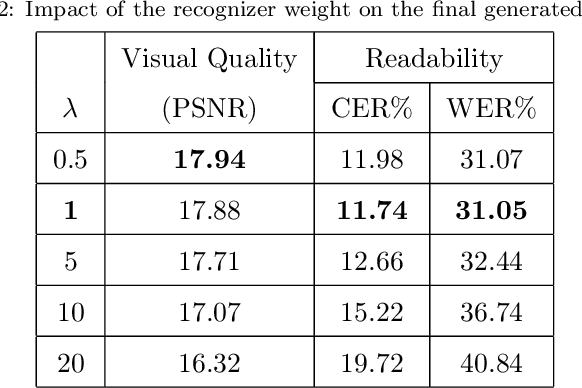
Handwritten document images can be highly affected by degradation for different reasons: Paper ageing, daily-life scenarios (wrinkles, dust, etc.), bad scanning process and so on. These artifacts raise many readability issues for current Handwritten Text Recognition (HTR) algorithms and severely devalue their efficiency. In this paper, we propose an end to end architecture based on Generative Adversarial Networks (GANs) to recover the degraded documents into a clean and readable form. Unlike the most well-known document binarization methods, which try to improve the visual quality of the degraded document, the proposed architecture integrates a handwritten text recognizer that promotes the generated document image to be more readable. To the best of our knowledge, this is the first work to use the text information while binarizing handwritten documents. Extensive experiments conducted on degraded Arabic and Latin handwritten documents demonstrate the usefulness of integrating the recognizer within the GAN architecture, which improves both the visual quality and the readability of the degraded document images. Moreover, we outperform the state of the art in H-DIBCO 2018 challenge, after fine tuning our pre-trained model with synthetically degraded Latin handwritten images, on this task.