 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHEDAD: SNN-Enhanced District Heating Anomaly Detection for Urban Substations
Aug 23, 2024District Heating (DH) systems are essential for energy-efficient urban heating. However, despite the advancements in automated fault detection and diagnosis (FDD), DH still faces challenges in operational faults that impact efficiency. This study introduces the Shared Nearest Neighbor Enhanced District Heating Anomaly Detection (SHEDAD) approach, designed to approximate the DH network topology and allow for local anomaly detection without disclosing sensitive information, such as substation locations. The approach leverages a multi-adaptive k-Nearest Neighbor (k-NN) graph to improve the initial neighborhood creation. Moreover, it introduces a merging technique that reduces noise and eliminates trivial edges. We use the Median Absolute Deviation (MAD) and modified z-scores to flag anomalous substations. The results reveal that SHEDAD outperforms traditional clustering methods, achieving significantly lower intra-cluster variance and distance. Additionally, SHEDAD effectively isolates and identifies two distinct categories of anomalies: supply temperatures and substation performance. We identified 30 anomalous substations and reached a sensitivity of approximately 65\% and specificity of approximately 97\%. By focusing on this subset of poor-performing substations in the network, SHEDAD enables more targeted and effective maintenance interventions, which can reduce energy usage while optimizing network performance.
ST-KeyS: Self-Supervised Transformer for Keyword Spotting in Historical Handwritten Documents
Mar 06, 2023



Keyword spotting (KWS) in historical documents is an important tool for the initial exploration of digitized collections. Nowadays, the most efficient KWS methods are relying on machine learning techniques that require a large amount of annotated training data. However, in the case of historical manuscripts, there is a lack of annotated corpus for training. To handle the data scarcity issue, we investigate the merits of the self-supervised learning to extract useful representations of the input data without relying on human annotations and then using these representations in the downstream task. We propose ST-KeyS, a masked auto-encoder model based on vision transformers where the pretraining stage is based on the mask-and-predict paradigm, without the need of labeled data. In the fine-tuning stage, the pre-trained encoder is integrated into a siamese neural network model that is fine-tuned to improve feature embedding from the input images. We further improve the image representation using pyramidal histogram of characters (PHOC) embedding to create and exploit an intermediate representation of images based on text attributes. In an exhaustive experimental evaluation on three widely used benchmark datasets (Botany, Alvermann Konzilsprotokolle and George Washington), the proposed approach outperforms state-of-the-art methods trained on the same datasets.
ARMAS: Active Reconstruction of Missing Audio Segments
Nov 23, 2021

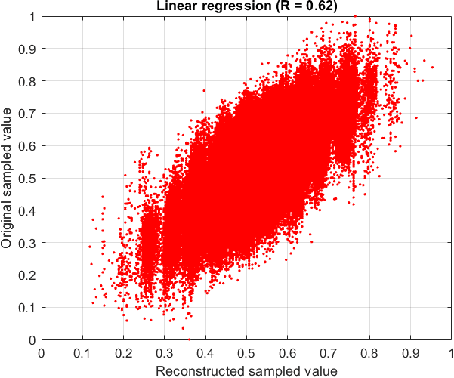
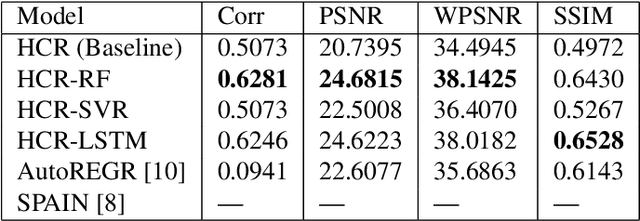
Digital audio signal reconstruction of lost or corrupt segment using deep learning algorithms has been explored intensively in the recent years. Nevertheless, prior traditional methods with linear interpolation, phase coding and tone insertion techniques are still in vogue. However, we found no research work on the reconstruction of audio signals with the fusion of dithering, steganography, and machine learning regressors. Therefore, this paper proposes the combination of steganography, halftoning (dithering), and state-of-the-art shallow (RF- Random Forest and SVR- Support Vector Regression) and deep learning (LSTM- Long Short-Term Memory) methods. The results (including comparison to the SPAIN and Autoregressive methods) are evaluated with four different metrics. The observations from the results show that the proposed solution is effective and can enhance the reconstruction of audio signals performed by the side information (noisy-latent representation) steganography provides. This work may trigger interest in the optimization of this approach and/or in transferring it to different domains (i.e., image reconstruction).
End-to-End Approach for Recognition of Historical Digit Strings
Apr 28, 2021
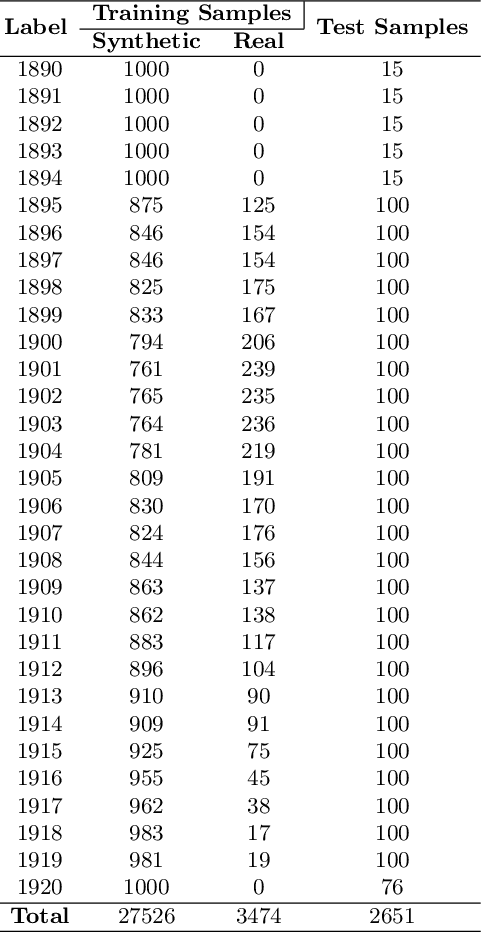
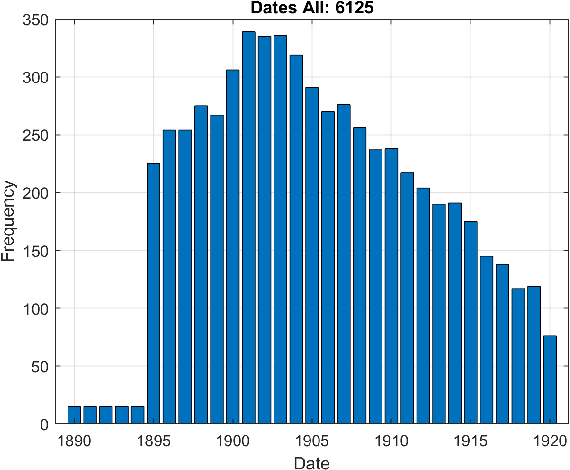

The plethora of digitalised historical document datasets released in recent years has rekindled interest in advancing the field of handwriting pattern recognition. In the same vein, a recently published data set, known as ARDIS, presents handwritten digits manually cropped from 15.000 scanned documents of Swedish church books and exhibiting various handwriting styles. To this end, we propose an end-to-end segmentation-free deep learning approach to handle this challenging ancient handwriting style of dates present in the ARDIS dataset (4-digits long strings). We show that with slight modifications in the VGG-16 deep model, the framework can achieve a recognition rate of 93.2%, resulting in a feasible solution free of heuristic methods, segmentation, and fusion methods. Moreover, the proposed approach outperforms the well-known CRNN method (a model widely applied in handwriting recognition tasks).
Mini-DDSM: Mammography-based Automatic Age Estimation
Oct 01, 2020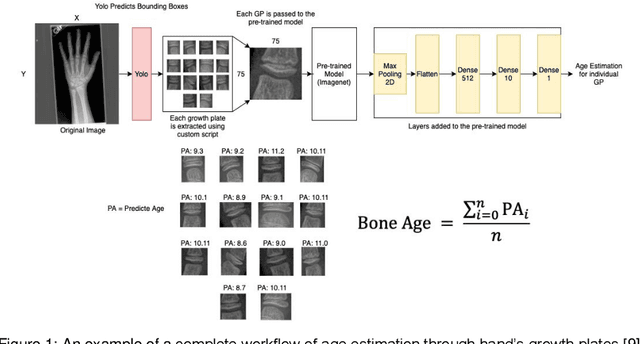
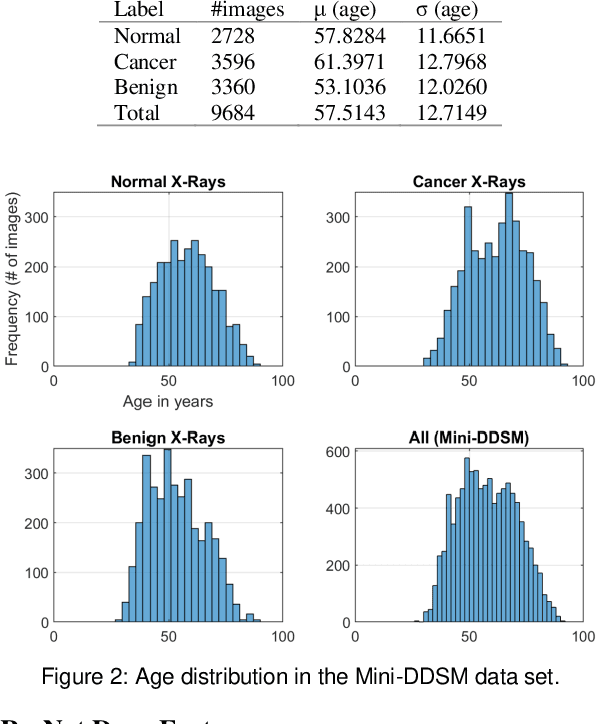

Age estimation has attracted attention for its various medical applications. There are many studies on human age estimation from biomedical images. However, there is no research done on mammograms for age estimation, as far as we know. The purpose of this study is to devise an AI-based model for estimating age from mammogram images. Due to lack of public mammography data sets that have the age attribute, we resort to using a web crawler to download thumbnail mammographic images and their age fields from the public data set; the Digital Database for Screening Mammography. The original images in this data set unfortunately can only be retrieved by a software which is broken. Subsequently, we extracted deep learning features from the collected data set, by which we built a model using Random Forests regressor to estimate the age automatically. The performance assessment was measured using the mean absolute error values. The average error value out of 10 tests on random selection of samples was around 8 years. In this paper, we show the merits of this approach to fill up missing age values. We ran logistic and linear regression models on another independent data set to further validate the advantage of our proposed work. This paper also introduces the free-access Mini-DDSM data set.
On Box-Cox Transformation for Image Normality and Pattern Classification
Apr 15, 2020
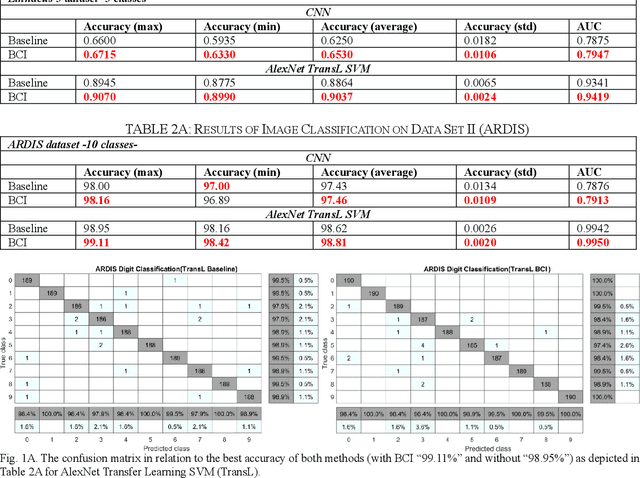
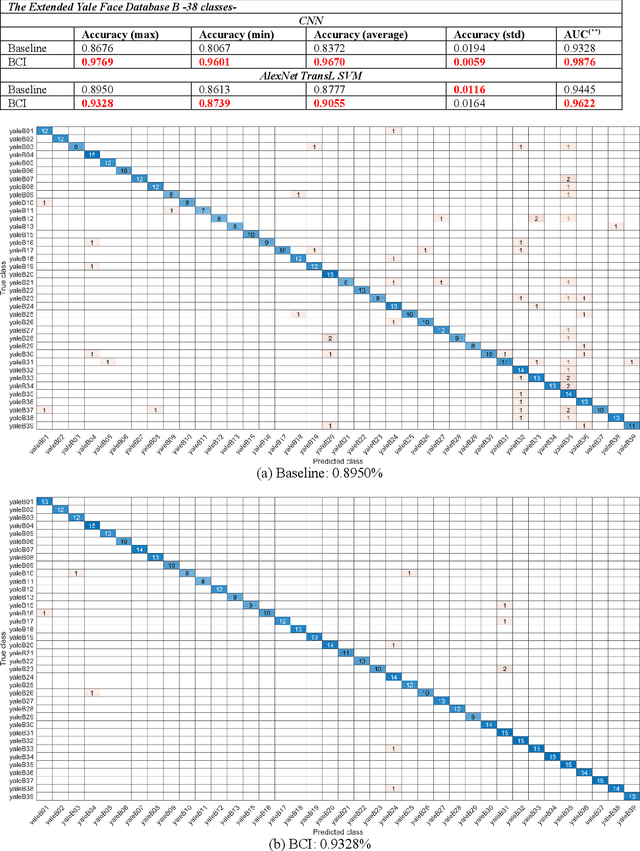
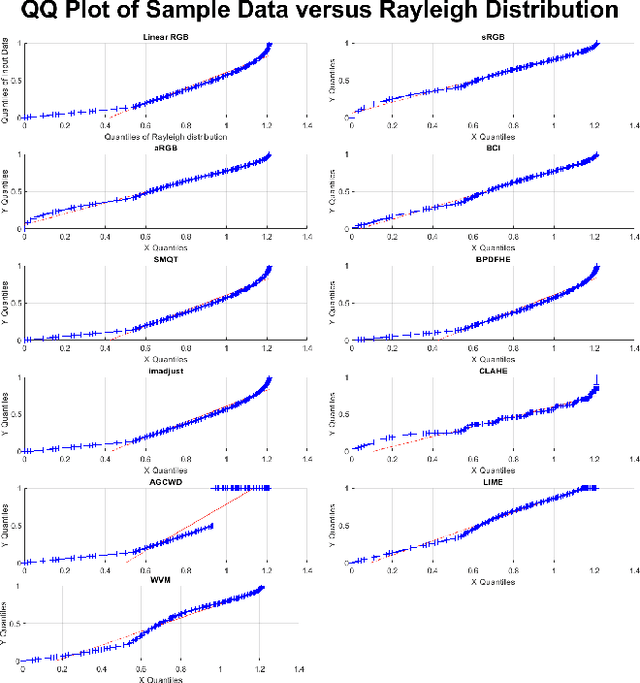
A unique member of the power transformation family is known as the Box-Cox transformation. The latter can be seen as a mathematical operation that leads to finding the optimum lambda ({\lambda}) value that maximizes the log-likelihood function to transform a data to a normal distribution and to reduce heteroscedasticity. In data analytics, a normality assumption underlies a variety of statistical test models. This technique, however, is best known in statistical analysis to handle one-dimensional data. Herein, this paper revolves around the utility of such a tool as a pre-processing step to transform two-dimensional data, namely, digital images and to study its effect. Moreover, to reduce time complexity, it suffices to estimate the parameter lambda in real-time for large two-dimensional matrices by merely considering their probability density function as a statistical inference of the underlying data distribution. We compare the effect of this light-weight Box-Cox transformation with well-established state-of-the-art low light image enhancement techniques. We also demonstrate the effectiveness of our approach through several test-bed data sets for generic improvement of visual appearance of images and for ameliorating the performance of a colour pattern classification algorithm as an example application. Results with and without the proposed approach, are compared using the state-of-the art transfer/deep learning which are discussed in the Appendix. To the best of our knowledge, this is the first time that the Box-Cox transformation is extended to digital images by exploiting histogram transformation.