 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARMAS: Active Reconstruction of Missing Audio Segments
Paper and Code


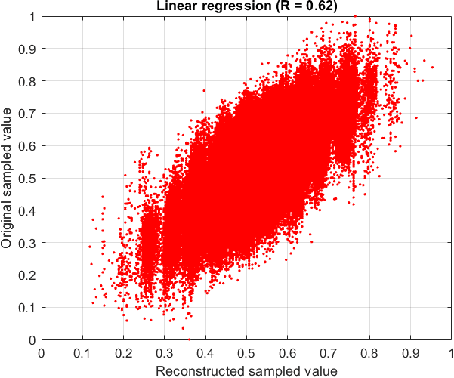
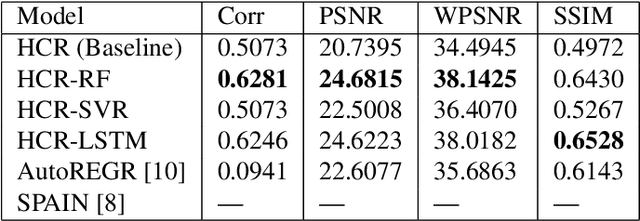
Digital audio signal reconstruction of lost or corrupt segment using deep learning algorithms has been explored intensively in the recent years. Nevertheless, prior traditional methods with linear interpolation, phase coding and tone insertion techniques are still in vogue. However, we found no research work on the reconstruction of audio signals with the fusion of dithering, steganography, and machine learning regressors. Therefore, this paper proposes the combination of steganography, halftoning (dithering), and state-of-the-art shallow (RF- Random Forest and SVR- Support Vector Regression) and deep learning (LSTM- Long Short-Term Memory) methods. The results (including comparison to the SPAIN and Autoregressive methods) are evaluated with four different metrics. The observations from the results show that the proposed solution is effective and can enhance the reconstruction of audio signals performed by the side information (noisy-latent representation) steganography provides. This work may trigger interest in the optimization of this approach and/or in transferring it to different domains (i.e., image reconstruction).