 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHEDAD: SNN-Enhanced District Heating Anomaly Detection for Urban Substations
Aug 23, 2024District Heating (DH) systems are essential for energy-efficient urban heating. However, despite the advancements in automated fault detection and diagnosis (FDD), DH still faces challenges in operational faults that impact efficiency. This study introduces the Shared Nearest Neighbor Enhanced District Heating Anomaly Detection (SHEDAD) approach, designed to approximate the DH network topology and allow for local anomaly detection without disclosing sensitive information, such as substation locations. The approach leverages a multi-adaptive k-Nearest Neighbor (k-NN) graph to improve the initial neighborhood creation. Moreover, it introduces a merging technique that reduces noise and eliminates trivial edges. We use the Median Absolute Deviation (MAD) and modified z-scores to flag anomalous substations. The results reveal that SHEDAD outperforms traditional clustering methods, achieving significantly lower intra-cluster variance and distance. Additionally, SHEDAD effectively isolates and identifies two distinct categories of anomalies: supply temperatures and substation performance. We identified 30 anomalous substations and reached a sensitivity of approximately 65\% and specificity of approximately 97\%. By focusing on this subset of poor-performing substations in the network, SHEDAD enables more targeted and effective maintenance interventions, which can reduce energy usage while optimizing network performance.
Beyond Random Noise: Insights on Anonymization Strategies from a Latent Bandit Study
Sep 30, 2023This paper investigates the issue of privacy in a learning scenario where users share knowledge for a recommendation task. Our study contributes to the growing body of research on privacy-preserving machine learning and underscores the need for tailored privacy techniques that address specific attack patterns rather than relying on one-size-fits-all solutions. We use the latent bandit setting to evaluate the trade-off between privacy and recommender performance by employing various aggregation strategies, such as averaging, nearest neighbor, and clustering combined with noise injection. More specifically, we simulate a linkage attack scenario leveraging publicly available auxiliary information acquired by the adversary. Our results on three open real-world datasets reveal that adding noise using the Laplace mechanism to an individual user's data record is a poor choice. It provides the highest regret for any noise level, relative to de-anonymization probability and the ADS metric. Instead, one should combine noise with appropriate aggregation strategies. For example, using averages from clusters of different sizes provides flexibility not achievable by varying the amount of noise alone. Generally, no single aggregation strategy can consistently achieve the optimum regret for a given desired level of privacy.
Toward efficient resource utilization at edge nodes in federated learning
Sep 19, 2023Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
FedCSD: A Federated Learning Based Approach for Code-Smell Detection
May 31, 2023



This paper proposes a Federated Learning Code Smell Detection (FedCSD) approach that allows organizations to collaboratively train federated ML models while preserving their data privacy. These assertions have been supported by three experiments that have significantly leveraged three manually validated datasets aimed at detecting and examining different code smell scenarios. In experiment 1, which was concerned with a centralized training experiment, dataset two achieved the lowest accuracy (92.30%) with fewer smells, while datasets one and three achieved the highest accuracy with a slight difference (98.90% and 99.5%, respectively). This was followed by experiment 2, which was concerned with cross-evaluation, where each ML model was trained using one dataset, which was then evaluated over the other two datasets. Results from this experiment show a significant drop in the model's accuracy (lowest accuracy: 63.80\%) where fewer smells exist in the training dataset, which has a noticeable reflection (technical debt) on the model's performance. Finally, the last and third experiments evaluate our approach by splitting the dataset into 10 companies. The ML model was trained on the company's site, then all model-updated weights were transferred to the server. Ultimately, an accuracy of 98.34% was achieved by the global model that has been trained using 10 companies for 100 training rounds. The results reveal a slight difference in the global model's accuracy compared to the highest accuracy of the centralized model, which can be ignored in favour of the global model's comprehensive knowledge, lower training cost, preservation of data privacy, and avoidance of the technical debt problem.
FedBot: Enhancing Privacy in Chatbots with Federated Learning
Apr 04, 2023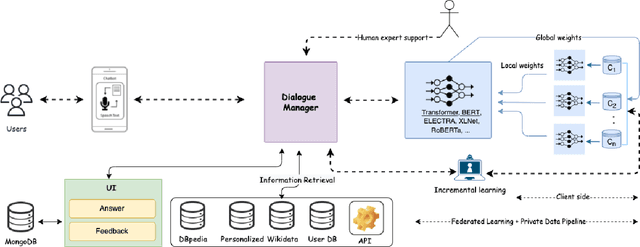

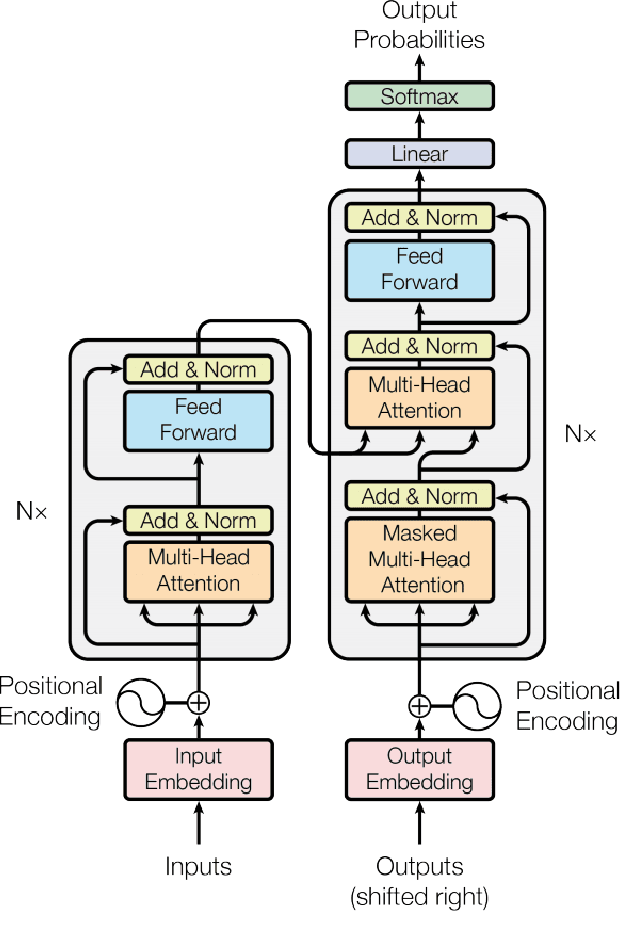
Chatbots are mainly data-driven and usually based on utterances that might be sensitive. However, training deep learning models on shared data can violate user privacy. Such issues have commonly existed in chatbots since their inception. In the literature, there have been many approaches to deal with privacy, such as differential privacy and secure multi-party computation, but most of them need to have access to users' data. In this context, Federated Learning (FL) aims to protect data privacy through distributed learning methods that keep the data in its location. This paper presents Fedbot, a proof-of-concept (POC) privacy-preserving chatbot that leverages large-scale customer support data. The POC combines Deep Bidirectional Transformer models and federated learning algorithms to protect customer data privacy during collaborative model training. The results of the proof-of-concept showcase the potential for privacy-preserving chatbots to transform the customer support industry by delivering personalized and efficient customer service that meets data privacy regulations and legal requirements. Furthermore, the system is specifically designed to improve its performance and accuracy over time by leveraging its ability to learn from previous interactions.
FedQAS: Privacy-aware machine reading comprehension with federated learning
Feb 09, 2022
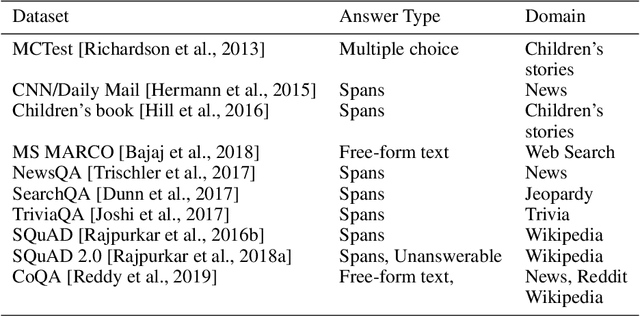
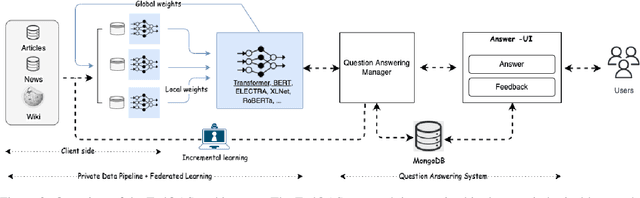
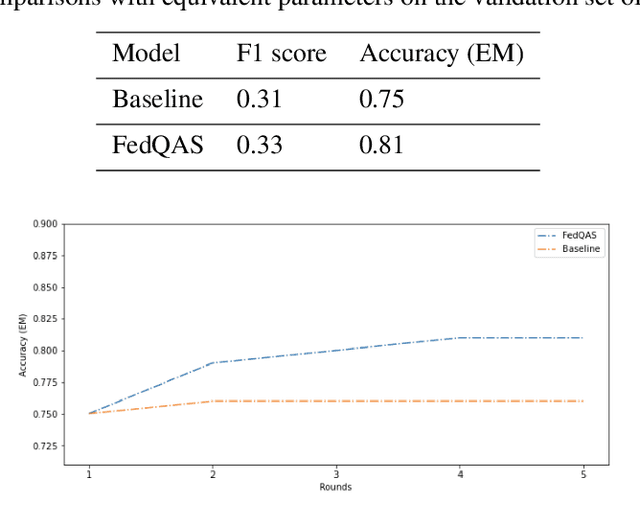
Machine reading comprehension (MRC) of text data is one important task in Natural Language Understanding. It is a complex NLP problem with a lot of ongoing research fueled by the release of the Stanford Question Answering Dataset (SQuAD) and Conversational Question Answering (CoQA). It is considered to be an effort to teach computers how to "understand" a text, and then to be able to answer questions about it using deep learning. However, until now large-scale training on private text data and knowledge sharing has been missing for this NLP task. Hence, we present FedQAS, a privacy-preserving machine reading system capable of leveraging large-scale private data without the need to pool those datasets in a central location. The proposed approach combines transformer models and federated learning technologies. The system is developed using the FEDn framework and deployed as a proof-of-concept alliance initiative. FedQAS is flexible, language-agnostic, and allows intuitive participation and execution of local model training. In addition, we present the architecture and implementation of the system, as well as provide a reference evaluation based on the SQUAD dataset, to showcase how it overcomes data privacy issues and enables knowledge sharing between alliance members in a Federated learning setting.
Scalable federated machine learning with FEDn
Feb 27, 2021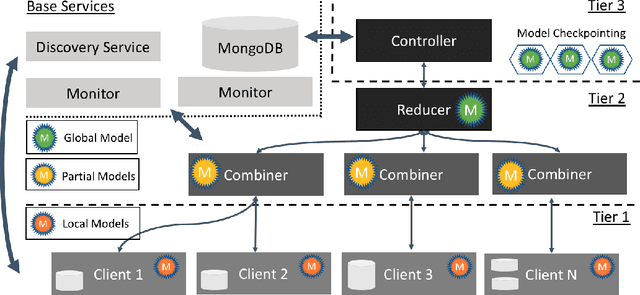

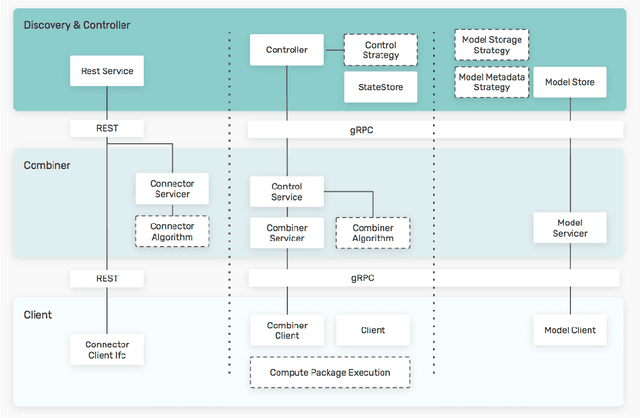
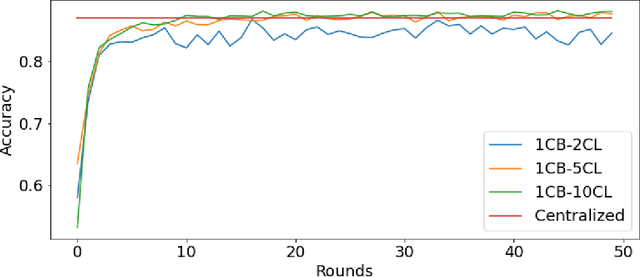
Federated machine learning has great promise to overcome the input privacy challenge in machine learning. The appearance of several projects capable of simulating federated learning has led to a corresponding rapid progress on algorithmic aspects of the problem. However, there is still a lack of federated machine learning frameworks that focus on fundamental aspects such as scalability, robustness, security, and performance in a geographically distributed setting. To bridge this gap we have designed and developed the FEDn framework. A main feature of FEDn is to support both cross-device and cross-silo training settings. This makes FEDn a powerful tool for researching a wide range of machine learning applications in a realistic setting.