 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward efficient resource utilization at edge nodes in federated learning
Sep 19, 2023Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
FedBot: Enhancing Privacy in Chatbots with Federated Learning
Apr 04, 2023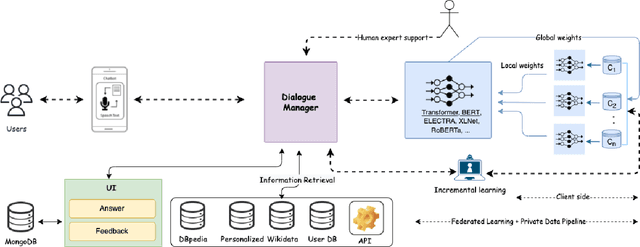

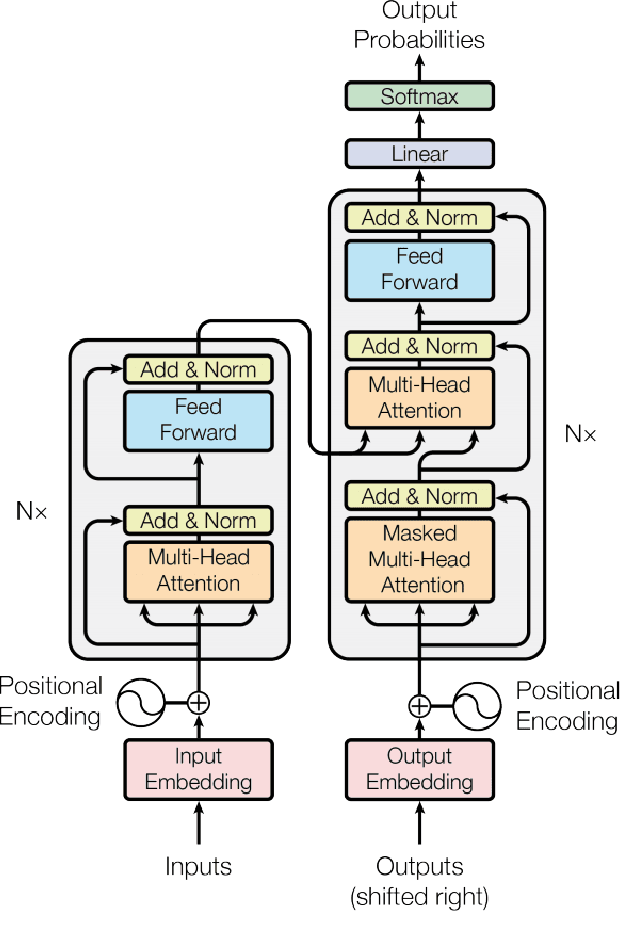
Chatbots are mainly data-driven and usually based on utterances that might be sensitive. However, training deep learning models on shared data can violate user privacy. Such issues have commonly existed in chatbots since their inception. In the literature, there have been many approaches to deal with privacy, such as differential privacy and secure multi-party computation, but most of them need to have access to users' data. In this context, Federated Learning (FL) aims to protect data privacy through distributed learning methods that keep the data in its location. This paper presents Fedbot, a proof-of-concept (POC) privacy-preserving chatbot that leverages large-scale customer support data. The POC combines Deep Bidirectional Transformer models and federated learning algorithms to protect customer data privacy during collaborative model training. The results of the proof-of-concept showcase the potential for privacy-preserving chatbots to transform the customer support industry by delivering personalized and efficient customer service that meets data privacy regulations and legal requirements. Furthermore, the system is specifically designed to improve its performance and accuracy over time by leveraging its ability to learn from previous interactions.
FedQAS: Privacy-aware machine reading comprehension with federated learning
Feb 09, 2022
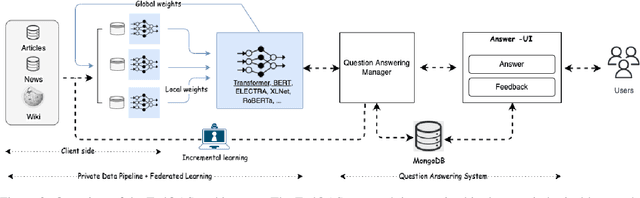
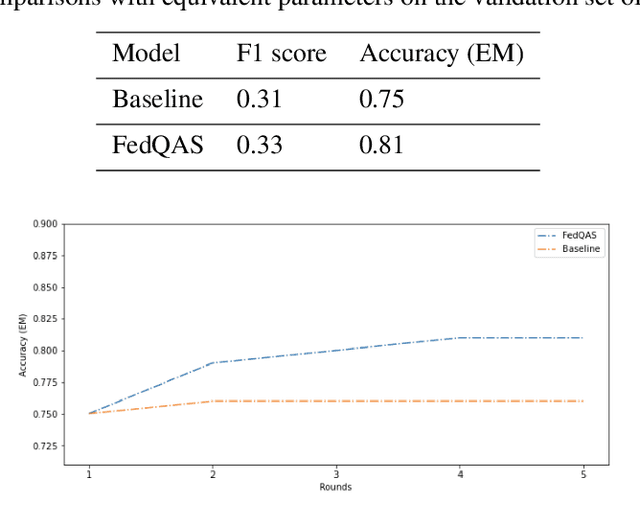
Machine reading comprehension (MRC) of text data is one important task in Natural Language Understanding. It is a complex NLP problem with a lot of ongoing research fueled by the release of the Stanford Question Answering Dataset (SQuAD) and Conversational Question Answering (CoQA). It is considered to be an effort to teach computers how to "understand" a text, and then to be able to answer questions about it using deep learning. However, until now large-scale training on private text data and knowledge sharing has been missing for this NLP task. Hence, we present FedQAS, a privacy-preserving machine reading system capable of leveraging large-scale private data without the need to pool those datasets in a central location. The proposed approach combines transformer models and federated learning technologies. The system is developed using the FEDn framework and deployed as a proof-of-concept alliance initiative. FedQAS is flexible, language-agnostic, and allows intuitive participation and execution of local model training. In addition, we present the architecture and implementation of the system, as well as provide a reference evaluation based on the SQUAD dataset, to showcase how it overcomes data privacy issues and enables knowledge sharing between alliance members in a Federated learning setting.
Scalable federated machine learning with FEDn
Feb 27, 2021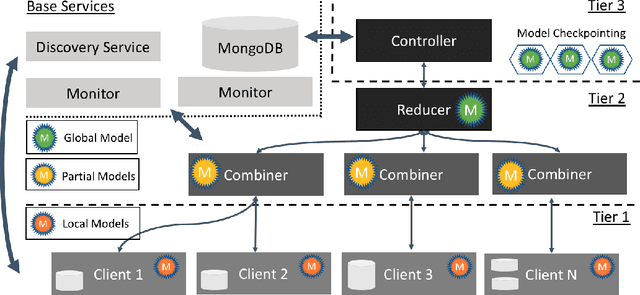

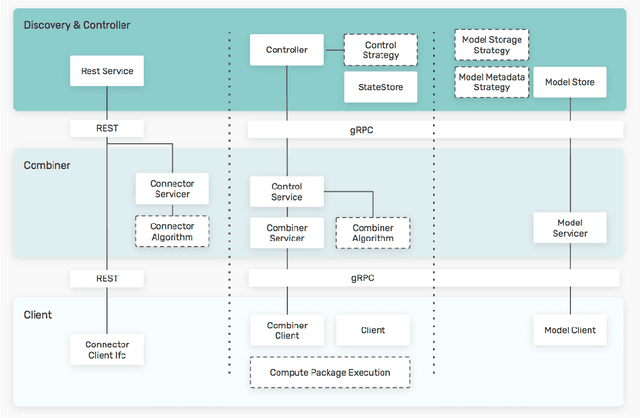
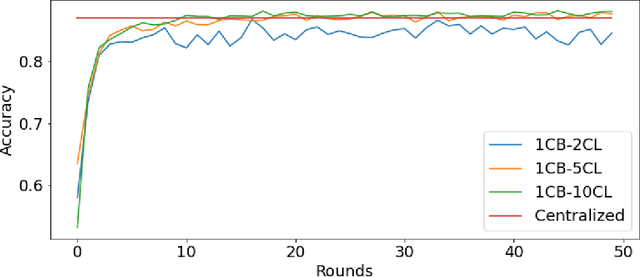
Federated machine learning has great promise to overcome the input privacy challenge in machine learning. The appearance of several projects capable of simulating federated learning has led to a corresponding rapid progress on algorithmic aspects of the problem. However, there is still a lack of federated machine learning frameworks that focus on fundamental aspects such as scalability, robustness, security, and performance in a geographically distributed setting. To bridge this gap we have designed and developed the FEDn framework. A main feature of FEDn is to support both cross-device and cross-silo training settings. This makes FEDn a powerful tool for researching a wide range of machine learning applications in a realistic setting.