 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoFlowVLM: Geometry-Aware Joint Uncertainty for Frozen Vision-Language Embedding
May 13, 2026Standard dual-encoder vision-language models that map images and text to deterministic points on a shared unit hypersphere through $\ell_2$ normalization typically expose neither \emph{aleatoric} uncertainty (cross-modal ambiguity) nor \emph{epistemic} uncertainty (lack of training-distribution support). Existing post-hoc methods either recover at most one of the two uncertainty components, or ignore the hyperspherical geometry of these models' embeddings. We propose \textbf{GeoFlowVLM} as a post-hoc adapter that learns the joint distribution of paired $\ell_2$-normalised dual-encoder VLM embeddings on the product hypersphere $\mathbb{S}^{d-1} \times \mathbb{S}^{d-1}$ via Riemannian flow matching with a single masked velocity field. A consistency result shows that, in the population limit, the trained network exposes the joint flow and both cross-modal conditional flows as valid Riemannian flow-matching velocity fields on their respective domains. We derive two quantities from this single model: a conditional retrieval entropy that quantifies aleatoric ambiguity with a decision-theoretic interpretation via a Fano-type bound, and a marginal-typicality epistemic score justified by an exact chain-rule decomposition of the joint NLL. This decomposition isolates a cross-modal pointwise-mutual-information term that is structurally discriminative rather than epistemic, and is empirically the only consistently uninformative standalone component. Empirically, the entropy tracks Recall@1 with near-ideal monotonic calibration across three retrieval benchmarks in both directions, and the marginal-typicality sum yields consistently calibrated selective accuracy across four zero-shot classification benchmarks.
OneFlowSBI: One Model, Many Queries for Simulation-Based Inference
Jan 30, 2026We introduce \textit{OneFlowSBI}, a unified framework for simulation-based inference that learns a single flow-matching generative model over the joint distribution of parameters and observations. Leveraging a query-aware masking distribution during training, the same model supports multiple inference tasks, including posterior sampling, likelihood estimation, and arbitrary conditional distributions, without task-specific retraining. We evaluate \textit{OneFlowSBI} on ten benchmark inference problems and two high-dimensional real-world inverse problems across multiple simulation budgets. \textit{OneFlowSBI} is shown to deliver competitive performance against state-of-the-art generalized inference solvers and specialized posterior estimators, while enabling efficient sampling with few ODE integration steps and remaining robust under noisy and partially observed data.
From Research to Reality: Feasibility of Gradient Inversion Attacks in Federated Learning
Aug 27, 2025Gradient inversion attacks have garnered attention for their ability to compromise privacy in federated learning. However, many studies consider attacks with the model in inference mode, where training-time behaviors like dropout are disabled and batch normalization relies on fixed statistics. In this work, we systematically analyze how architecture and training behavior affect vulnerability, including the first in-depth study of inference-mode clients, which we show dramatically simplifies inversion. To assess attack feasibility under more realistic conditions, we turn to clients operating in standard training mode. In this setting, we find that successful attacks are only possible when several architectural conditions are met simultaneously: models must be shallow and wide, use skip connections, and, critically, employ pre-activation normalization. We introduce two novel attacks against models in training-mode with varying attacker knowledge, achieving state-of-the-art performance under realistic training conditions. We extend these efforts by presenting the first attack on a production-grade object-detection model. Here, to enable any visibly identifiable leakage, we revert to the lenient inference mode setting and make multiple architectural modifications to increase model vulnerability, with the extent of required changes highlighting the strong inherent robustness of such architectures. We conclude this work by offering the first comprehensive mapping of settings, clarifying which combinations of architectural choices and operational modes meaningfully impact privacy. Our analysis provides actionable insight into when models are likely vulnerable, when they appear robust, and where subtle leakage may persist. Together, these findings reframe how gradient inversion risk should be assessed in future research and deployment scenarios.
Exploiting the Asymmetric Uncertainty Structure of Pre-trained VLMs on the Unit Hypersphere
May 16, 2025Vision-language models (VLMs) as foundation models have significantly enhanced performance across a wide range of visual and textual tasks, without requiring large-scale training from scratch for downstream tasks. However, these deterministic VLMs fail to capture the inherent ambiguity and uncertainty in natural language and visual data. Recent probabilistic post-hoc adaptation methods address this by mapping deterministic embeddings onto probability distributions; however, existing approaches do not account for the asymmetric uncertainty structure of the modalities, and the constraint that meaningful deterministic embeddings reside on a unit hypersphere, potentially leading to suboptimal performance. In this paper, we address the asymmetric uncertainty structure inherent in textual and visual data, and propose AsymVLM to build probabilistic embeddings from pre-trained VLMs on the unit hypersphere, enabling uncertainty quantification. We validate the effectiveness of the probabilistic embeddings on established benchmarks, and present comprehensive ablation studies demonstrating the inherent nature of asymmetry in the uncertainty structure of textual and visual data.
ConDiSim: Conditional Diffusion Models for Simulation Based Inference
May 13, 2025We present a conditional diffusion model - ConDiSim, for simulation-based inference of complex systems with intractable likelihoods. ConDiSim leverages denoising diffusion probabilistic models to approximate posterior distributions, consisting of a forward process that adds Gaussian noise to parameters, and a reverse process learning to denoise, conditioned on observed data. This approach effectively captures complex dependencies and multi-modalities within posteriors. ConDiSim is evaluated across ten benchmark problems and two real-world test problems, where it demonstrates effective posterior approximation accuracy while maintaining computational efficiency and stability in model training. ConDiSim offers a robust and extensible framework for simulation-based inference, particularly suitable for parameter inference workflows requiring fast inference methods.
Variational Autoencoders for Efficient Simulation-Based Inference
Nov 21, 2024



We present a generative modeling approach based on the variational inference framework for likelihood-free simulation-based inference. The method leverages latent variables within variational autoencoders to efficiently estimate complex posterior distributions arising from stochastic simulations. We explore two variations of this approach distinguished by their treatment of the prior distribution. The first model adapts the prior based on observed data using a multivariate prior network, enhancing generalization across various posterior queries. In contrast, the second model utilizes a standard Gaussian prior, offering simplicity while still effectively capturing complex posterior distributions. We demonstrate the efficacy of these models on well-established benchmark problems, achieving results comparable to flow-based approaches while maintaining computational efficiency and scalability.
Toward efficient resource utilization at edge nodes in federated learning
Sep 19, 2023Federated learning (FL) enables edge nodes to collaboratively contribute to constructing a global model without sharing their data. This is accomplished by devices computing local, private model updates that are then aggregated by a server. However, computational resource constraints and network communication can become a severe bottleneck for larger model sizes typical for deep learning applications. Edge nodes tend to have limited hardware resources (RAM, CPU), and the network bandwidth and reliability at the edge is a concern for scaling federated fleet applications. In this paper, we propose and evaluate a FL strategy inspired by transfer learning in order to reduce resource utilization on devices, as well as the load on the server and network in each global training round. For each local model update, we randomly select layers to train, freezing the remaining part of the model. In doing so, we can reduce both server load and communication costs per round by excluding all untrained layer weights from being transferred to the server. The goal of this study is to empirically explore the potential trade-off between resource utilization on devices and global model convergence under the proposed strategy. We implement the approach using the federated learning framework FEDn. A number of experiments were carried out over different datasets (CIFAR-10, CASA, and IMDB), performing different tasks using different deep-learning model architectures. Our results show that training the model partially can accelerate the training process, efficiently utilizes resources on-device, and reduce the data transmission by around 75% and 53% when we train 25%, and 50% of the model layers, respectively, without harming the resulting global model accuracy.
FedBot: Enhancing Privacy in Chatbots with Federated Learning
Apr 04, 2023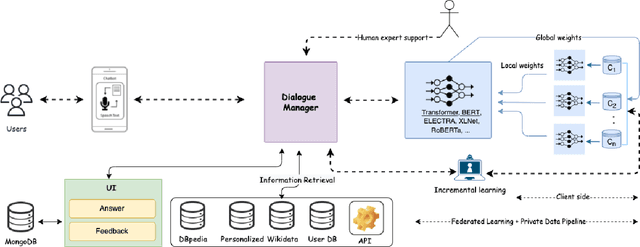

Chatbots are mainly data-driven and usually based on utterances that might be sensitive. However, training deep learning models on shared data can violate user privacy. Such issues have commonly existed in chatbots since their inception. In the literature, there have been many approaches to deal with privacy, such as differential privacy and secure multi-party computation, but most of them need to have access to users' data. In this context, Federated Learning (FL) aims to protect data privacy through distributed learning methods that keep the data in its location. This paper presents Fedbot, a proof-of-concept (POC) privacy-preserving chatbot that leverages large-scale customer support data. The POC combines Deep Bidirectional Transformer models and federated learning algorithms to protect customer data privacy during collaborative model training. The results of the proof-of-concept showcase the potential for privacy-preserving chatbots to transform the customer support industry by delivering personalized and efficient customer service that meets data privacy regulations and legal requirements. Furthermore, the system is specifically designed to improve its performance and accuracy over time by leveraging its ability to learn from previous interactions.
Accelerating Fair Federated Learning: Adaptive Federated Adam
Jan 23, 2023



Federated learning is a distributed and privacy-preserving approach to train a statistical model collaboratively from decentralized data of different parties. However, when datasets of participants are not independent and identically distributed (non-IID), models trained by naive federated algorithms may be biased towards certain participants, and model performance across participants is non-uniform. This is known as the fairness problem in federated learning. In this paper, we formulate fairness-controlled federated learning as a dynamical multi-objective optimization problem to ensure fair performance across all participants. To solve the problem efficiently, we study the convergence and bias of Adam as the server optimizer in federated learning, and propose Adaptive Federated Adam (AdaFedAdam) to accelerate fair federated learning with alleviated bias. We validated the effectiveness, Pareto optimality and robustness of AdaFedAdam in numerical experiments and show that AdaFedAdam outperforms existing algorithms, providing better convergence and fairness properties of the federated scheme.
FedQAS: Privacy-aware machine reading comprehension with federated learning
Feb 09, 2022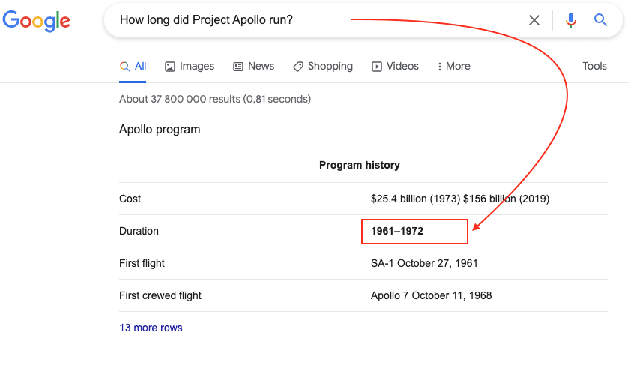
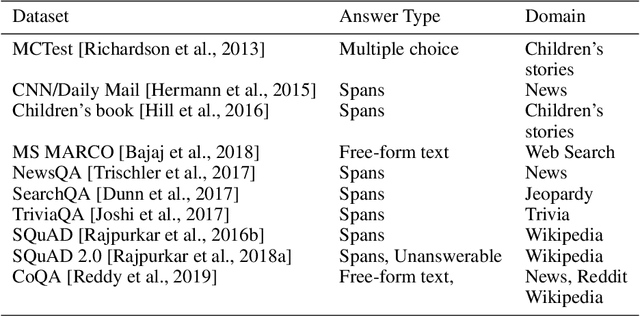
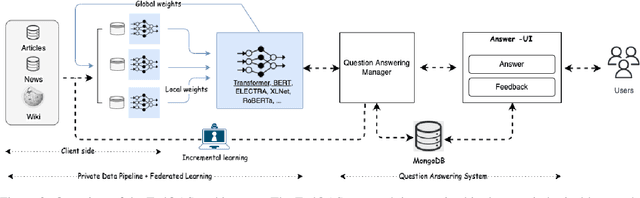
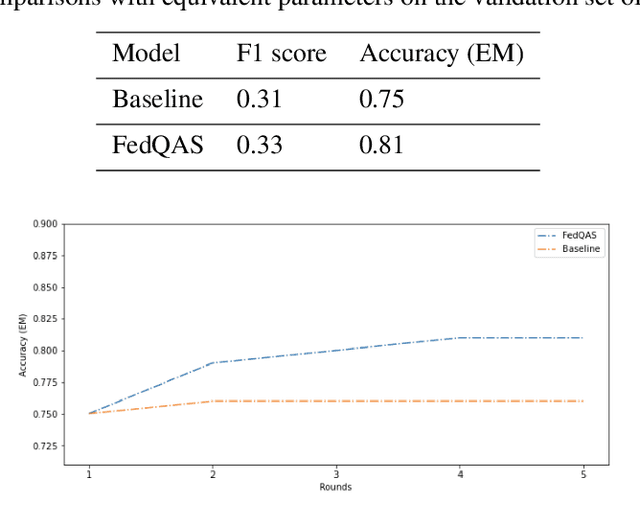
Machine reading comprehension (MRC) of text data is one important task in Natural Language Understanding. It is a complex NLP problem with a lot of ongoing research fueled by the release of the Stanford Question Answering Dataset (SQuAD) and Conversational Question Answering (CoQA). It is considered to be an effort to teach computers how to "understand" a text, and then to be able to answer questions about it using deep learning. However, until now large-scale training on private text data and knowledge sharing has been missing for this NLP task. Hence, we present FedQAS, a privacy-preserving machine reading system capable of leveraging large-scale private data without the need to pool those datasets in a central location. The proposed approach combines transformer models and federated learning technologies. The system is developed using the FEDn framework and deployed as a proof-of-concept alliance initiative. FedQAS is flexible, language-agnostic, and allows intuitive participation and execution of local model training. In addition, we present the architecture and implementation of the system, as well as provide a reference evaluation based on the SQUAD dataset, to showcase how it overcomes data privacy issues and enables knowledge sharing between alliance members in a Federated learning setting.