 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Structural Non-Preservation of Epistemic Behaviour under Policy Transformation
Feb 24, 2026Reinforcement learning (RL) agents under partial observability often condition actions on internally accumulated information such as memory or inferred latent context. We formalise such information-conditioned interaction patterns as behavioural dependency: variation in action selection with respect to internal information under fixed observations. This induces a probe-relative notion of $ε$-behavioural equivalence and a within-policy behavioural distance that quantifies probe sensitivity. We establish three structural results. First, the set of policies exhibiting non-trivial behavioural dependency is not closed under convex aggregation. Second, behavioural distance contracts under convex combination. Third, we prove a sufficient local condition under which gradient ascent on a skewed mixture objective decreases behavioural distance when a dominant-mode gradient aligns with the direction of steepest contraction. Minimal bandit and partially observable gridworld experiments provide controlled witnesses of these mechanisms. In the examined settings, behavioural distance decreases under convex aggregation and under continued optimisation with skewed latent priors, and in these experiments it precedes degradation under latent prior shift. These results identify structural conditions under which probe-conditioned behavioural separation is not preserved under common policy transformations.
Beyond Random Noise: Insights on Anonymization Strategies from a Latent Bandit Study
Sep 30, 2023This paper investigates the issue of privacy in a learning scenario where users share knowledge for a recommendation task. Our study contributes to the growing body of research on privacy-preserving machine learning and underscores the need for tailored privacy techniques that address specific attack patterns rather than relying on one-size-fits-all solutions. We use the latent bandit setting to evaluate the trade-off between privacy and recommender performance by employing various aggregation strategies, such as averaging, nearest neighbor, and clustering combined with noise injection. More specifically, we simulate a linkage attack scenario leveraging publicly available auxiliary information acquired by the adversary. Our results on three open real-world datasets reveal that adding noise using the Laplace mechanism to an individual user's data record is a poor choice. It provides the highest regret for any noise level, relative to de-anonymization probability and the ADS metric. Instead, one should combine noise with appropriate aggregation strategies. For example, using averages from clusters of different sizes provides flexibility not achievable by varying the amount of noise alone. Generally, no single aggregation strategy can consistently achieve the optimum regret for a given desired level of privacy.
Information-Gathering in Latent Bandits
Jul 08, 2022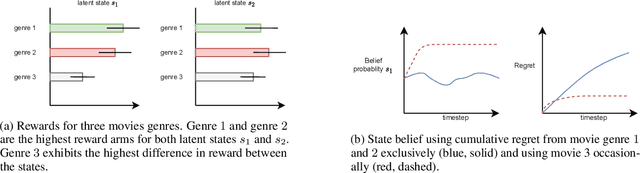
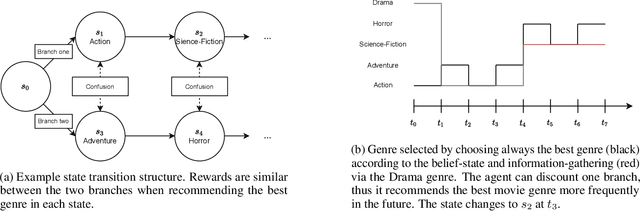
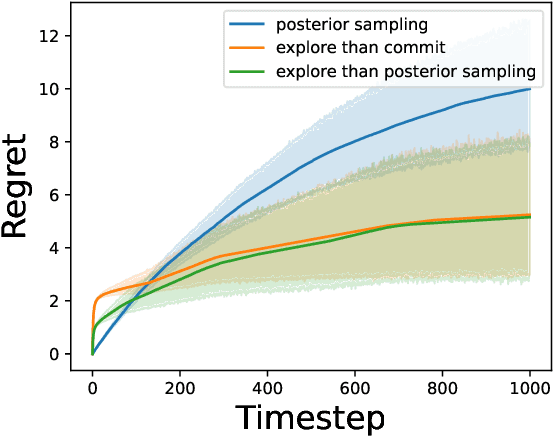
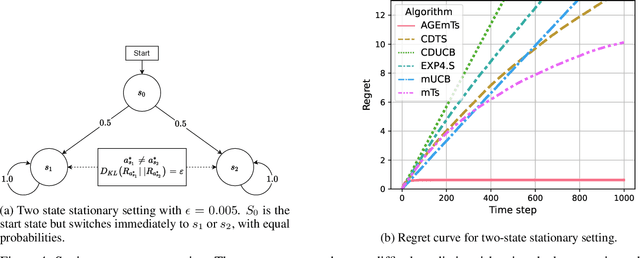
In the latent bandit problem, the learner has access to reward distributions and -- for the non-stationary variant -- transition models of the environment. The reward distributions are conditioned on the arm and unknown latent states. The goal is to use the reward history to identify the latent state, allowing for the optimal choice of arms in the future. The latent bandit setting lends itself to many practical applications, such as recommender and decision support systems, where rich data allows the offline estimation of environment models with online learning remaining a critical component. Previous solutions in this setting always choose the highest reward arm according to the agent's beliefs about the state, not explicitly considering the value of information-gathering arms. Such information-gathering arms do not necessarily provide the highest reward, thus may never be chosen by an agent that chooses the highest reward arms at all times. In this paper, we present a method for information-gathering in latent bandits. Given particular reward structures and transition matrices, we show that choosing the best arm given the agent's beliefs about the states incurs higher regret. Furthermore, we show that by choosing arms carefully, we obtain an improved estimation of the state distribution, and thus lower the cumulative regret through better arm choices in the future. We evaluate our method on both synthetic and real-world data sets, showing significant improvement in regret over state-of-the-art methods.
Corrupted Contextual Bandits with Action Order Constraints
Nov 16, 2020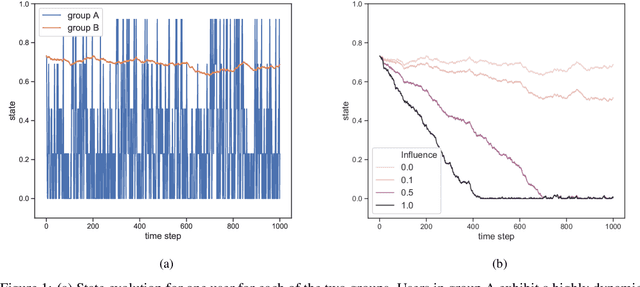
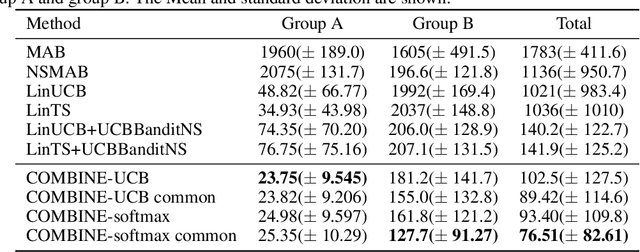
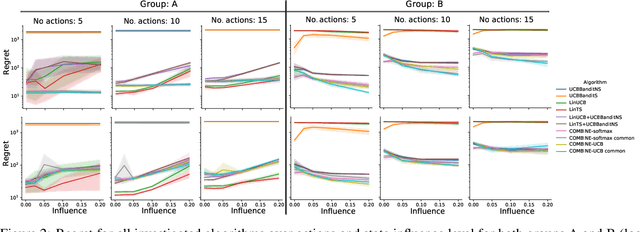
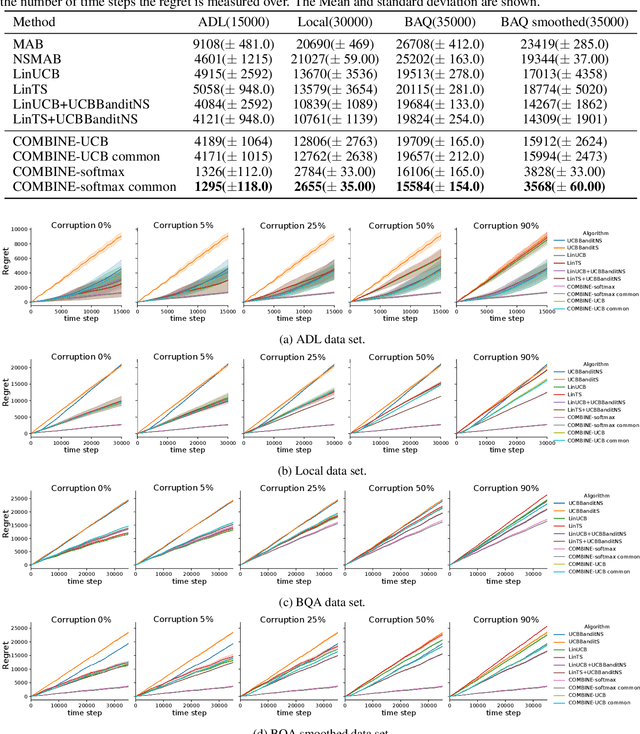
We consider a variant of the novel contextual bandit problem with corrupted context, which we call the contextual bandit problem with corrupted context and action correlation, where actions exhibit a relationship structure that can be exploited to guide the exploration of viable next decisions. Our setting is primarily motivated by adaptive mobile health interventions and related applications, where users might transitions through different stages requiring more targeted action selection approaches. In such settings, keeping user engagement is paramount for the success of interventions and therefore it is vital to provide relevant recommendations in a timely manner. The context provided by users might not always be informative at every decision point and standard contextual approaches to action selection will incur high regret. We propose a meta-algorithm using a referee that dynamically combines the policies of a contextual bandit and multi-armed bandit, similar to previous work, as wells as a simple correlation mechanism that captures action to action transition probabilities allowing for more efficient exploration of time-correlated actions. We evaluate empirically the performance of said algorithm on a simulation where the sequence of best actions is determined by a hidden state that evolves in a Markovian manner. We show that the proposed meta-algorithm improves upon regret in situations where the performance of both policies varies such that one is strictly superior to the other for a given time period. To demonstrate that our setting has relevant practical applicability, we evaluate our method on several real world data sets, clearly showing better empirical performance compared to a set of simple algorithms.