 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFATURA: A Multi-Layout Invoice Image Dataset for Document Analysis and Understanding
Nov 20, 2023Document analysis and understanding models often require extensive annotated data to be trained. However, various document-related tasks extend beyond mere text transcription, requiring both textual content and precise bounding-box annotations to identify different document elements. Collecting such data becomes particularly challenging, especially in the context of invoices, where privacy concerns add an additional layer of complexity. In this paper, we introduce FATURA, a pivotal resource for researchers in the field of document analysis and understanding. FATURA is a highly diverse dataset featuring multi-layout, annotated invoice document images. Comprising $10,000$ invoices with $50$ distinct layouts, it represents the largest openly accessible image dataset of invoice documents known to date. We also provide comprehensive benchmarks for various document analysis and understanding tasks and conduct experiments under diverse training and evaluation scenarios. The dataset is freely accessible at https://zenodo.org/record/8261508, empowering researchers to advance the field of document analysis and understanding.
MSdocTr-Lite: A Lite Transformer for Full Page Multi-script Handwriting Recognition
Mar 24, 2023The Transformer has quickly become the dominant architecture for various pattern recognition tasks due to its capacity for long-range representation. However, transformers are data-hungry models and need large datasets for training. In Handwritten Text Recognition (HTR), collecting a massive amount of labeled data is a complicated and expensive task. In this paper, we propose a lite transformer architecture for full-page multi-script handwriting recognition. The proposed model comes with three advantages: First, to solve the common problem of data scarcity, we propose a lite transformer model that can be trained on a reasonable amount of data, which is the case of most HTR public datasets, without the need for external data. Second, it can learn the reading order at page-level thanks to a curriculum learning strategy, allowing it to avoid line segmentation errors, exploit a larger context and reduce the need for costly segmentation annotations. Third, it can be easily adapted to other scripts by applying a simple transfer-learning process using only page-level labeled images. Extensive experiments on different datasets with different scripts (French, English, Spanish, and Arabic) show the effectiveness of the proposed model.
CSSL-MHTR: Continual Self-Supervised Learning for Scalable Multi-script Handwritten Text Recognition
Mar 16, 2023Self-supervised learning has recently emerged as a strong alternative in document analysis. These approaches are now capable of learning high-quality image representations and overcoming the limitations of supervised methods, which require a large amount of labeled data. However, these methods are unable to capture new knowledge in an incremental fashion, where data is presented to the model sequentially, which is closer to the realistic scenario. In this paper, we explore the potential of continual self-supervised learning to alleviate the catastrophic forgetting problem in handwritten text recognition, as an example of sequence recognition. Our method consists in adding intermediate layers called adapters for each task, and efficiently distilling knowledge from the previous model while learning the current task. Our proposed framework is efficient in both computation and memory complexity. To demonstrate its effectiveness, we evaluate our method by transferring the learned model to diverse text recognition downstream tasks, including Latin and non-Latin scripts. As far as we know, this is the first application of continual self-supervised learning for handwritten text recognition. We attain state-of-the-art performance on English, Italian and Russian scripts, whilst adding only a few parameters per task. The code and trained models will be publicly available.
Transformer-Based Approach for Joint Handwriting and Named Entity Recognition in Historical documents
Dec 08, 2021
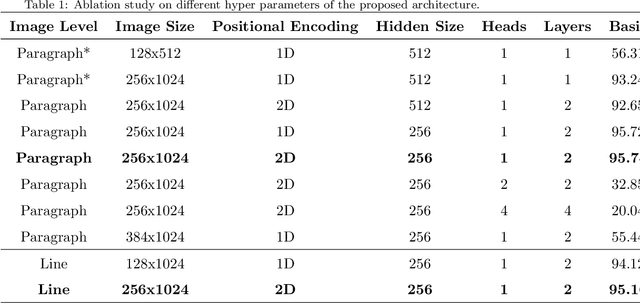

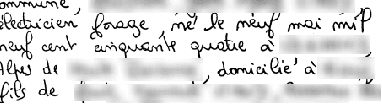
The extraction of relevant information carried out by named entities in handwriting documents is still a challenging task. Unlike traditional information extraction approaches that usually face text transcription and named entity recognition as separate subsequent tasks, we propose in this paper an end-to-end transformer-based approach to jointly perform these two tasks. The proposed approach operates at the paragraph level, which brings two main benefits. First, it allows the model to avoid unrecoverable early errors due to line segmentation. Second, it allows the model to exploit larger bi-dimensional context information to identify the semantic categories, reaching a higher final prediction accuracy. We also explore different training scenarios to show their effect on the performance and we demonstrate that a two-stage learning strategy can make the model reach a higher final prediction accuracy. As far as we know, this work presents the first approach that adopts the transformer networks for named entity recognition in handwritten documents. We achieve the new state-of-the-art performance in the ICDAR 2017 Information Extraction competition using the Esposalles database, for the complete task, even though the proposed technique does not use any dictionaries, language modeling, or post-processing.