Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecipherment of Historical Manuscript Images
Paper and Code

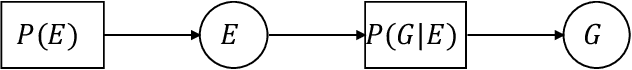
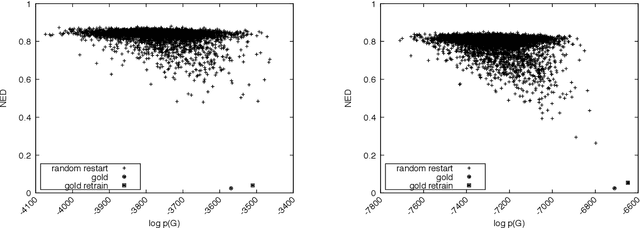
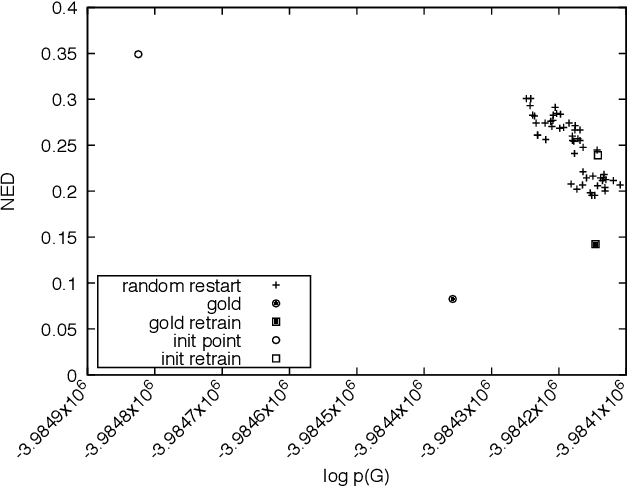
European libraries and archives are filled with enciphered manuscripts from the early modern period. These include military and diplomatic correspondence, records of secret societies, private letters, and so on. Although they are enciphered with classical cryptographic algorithms, their contents are unavailable to working historians. We therefore attack the problem of automatically converting cipher manuscript images into plaintext. We develop unsupervised models for character segmentation, character-image clustering, and decipherment of cluster sequences. We experiment with both pipelined and joint models, and we give empirical results for multiple ciphers.
* 10 pages
View paper on