 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures
Oct 17, 2024



Perceiving and generating diverse modalities are crucial for AI models to effectively learn from and engage with real-world signals, necessitating reliable evaluations for their development. We identify two major issues in current evaluations: (1) inconsistent standards, shaped by different communities with varying protocols and maturity levels; and (2) significant query, grading, and generalization biases. To address these, we introduce MixEval-X, the first any-to-any real-world benchmark designed to optimize and standardize evaluations across input and output modalities. We propose multi-modal benchmark mixture and adaptation-rectification pipelines to reconstruct real-world task distributions, ensuring evaluations generalize effectively to real-world use cases. Extensive meta-evaluations show our approach effectively aligns benchmark samples with real-world task distributions and the model rankings correlate strongly with that of crowd-sourced real-world evaluations (up to 0.98). We provide comprehensive leaderboards to rerank existing models and organizations and offer insights to enhance understanding of multi-modal evaluations and inform future research.
MixEval: Deriving Wisdom of the Crowd from LLM Benchmark Mixtures
Jun 03, 2024



Evaluating large language models (LLMs) is challenging. Traditional ground-truth-based benchmarks fail to capture the comprehensiveness and nuance of real-world queries, while LLM-as-judge benchmarks suffer from grading biases and limited query quantity. Both of them may also become contaminated over time. User-facing evaluation, such as Chatbot Arena, provides reliable signals but is costly and slow. In this work, we propose MixEval, a new paradigm for establishing efficient, gold-standard LLM evaluation by strategically mixing off-the-shelf benchmarks. It bridges (1) comprehensive and well-distributed real-world user queries and (2) efficient and fairly-graded ground-truth-based benchmarks, by matching queries mined from the web with similar queries from existing benchmarks. Based on MixEval, we further build MixEval-Hard, which offers more room for model improvement. Our benchmarks' advantages lie in (1) a 0.96 model ranking correlation with Chatbot Arena arising from the highly impartial query distribution and grading mechanism, (2) fast, cheap, and reproducible execution (6% of the time and cost of MMLU), and (3) dynamic evaluation enabled by the rapid and stable data update pipeline. We provide extensive meta-evaluation and analysis for our and existing LLM benchmarks to deepen the community's understanding of LLM evaluation and guide future research directions.
S2cGAN: Semi-Supervised Training of Conditional GANs with Fewer Labels
Oct 23, 2020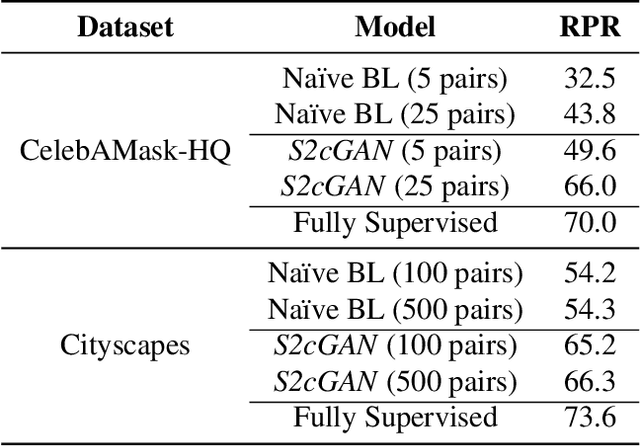
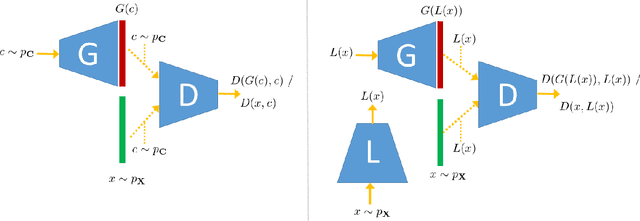
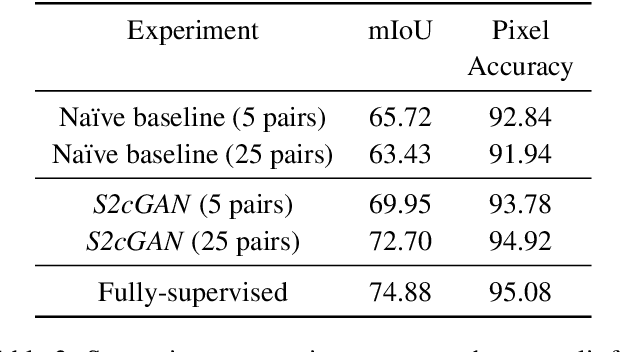

Generative adversarial networks (GANs) have been remarkably successful in learning complex high dimensional real word distributions and generating realistic samples. However, they provide limited control over the generation process. Conditional GANs (cGANs) provide a mechanism to control the generation process by conditioning the output on a user defined input. Although training GANs requires only unsupervised data, training cGANs requires labelled data which can be very expensive to obtain. We propose a framework for semi-supervised training of cGANs which utilizes sparse labels to learn the conditional mapping, and at the same time leverages a large amount of unsupervised data to learn the unconditional distribution. We demonstrate effectiveness of our method on multiple datasets and different conditional tasks.