 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Maximizing the Benefits of Back-End Noise Adaption on Attention-Based Speech Recognition Models
Paper and Code
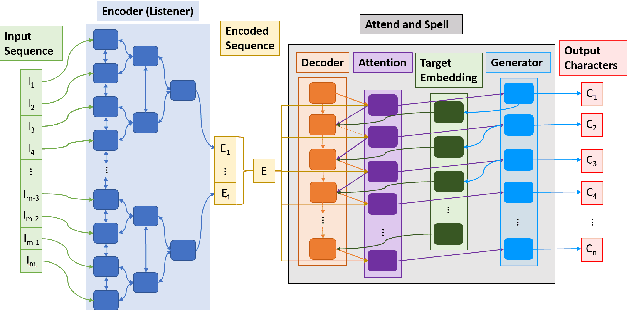

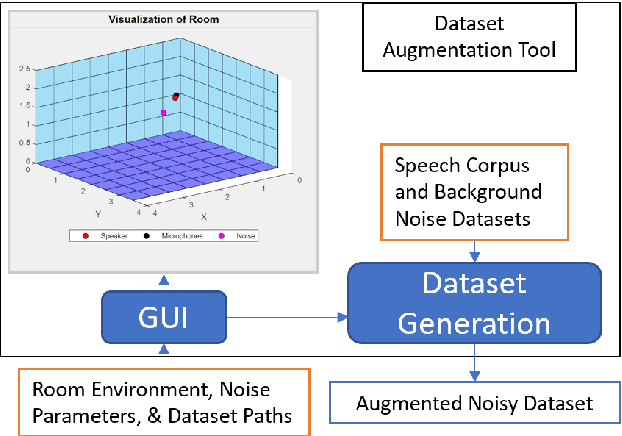
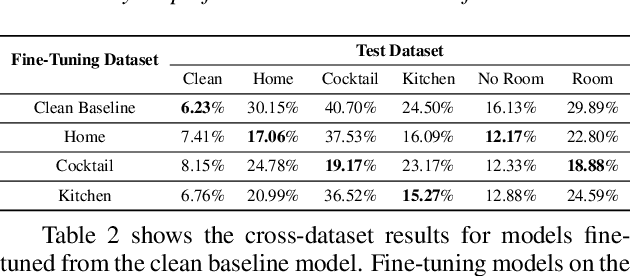
This work analyzes how attention-based Bidirectional Long Short-Term Memory (BLSTM) models adapt to noise-augmented speech. We identify crucial components for noise adaptation in BLSTM models by freezing model components during fine-tuning. We first freeze larger model subnetworks and then pursue a fine-grained freezing approach in the encoder after identifying its importance for noise adaptation. The first encoder layer is shown to be crucial for noise adaptation, and the weights are shown to be more important than the other layers. Appreciable accuracy benefits are identified when fine-tuning on a target noisy environment from a model pretrained with noisy speech relative to fine-tuning from a model pretrained with only clean speech when tested on the target noisy environment. For this analysis, we produce our own dataset augmentation tool and it is open-sourced to encourage future efforts in exploring noise adaptation in ASR.