 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust One Byte : A Note on Low-Bandwidth Decentralized Language Model Finetuning Using Shared Randomness
Paper and Code
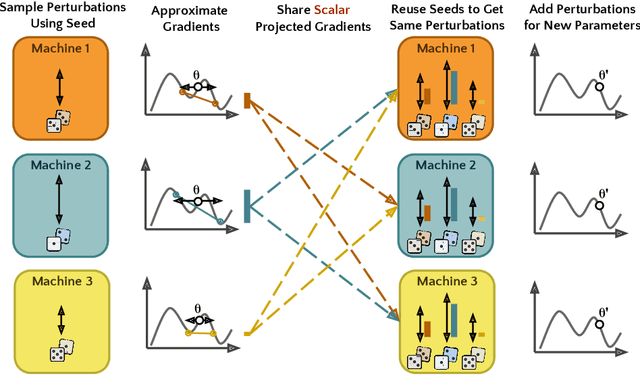
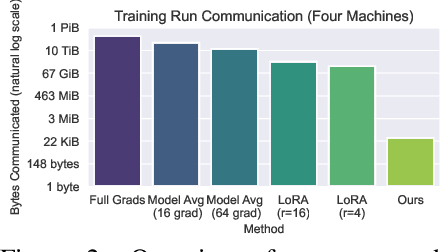
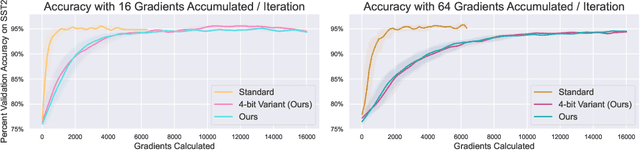
Language model training in distributed settings is limited by the communication cost of gradient exchanges. In this short note, we extend recent work from Malladi et al. (2023), using shared randomness to perform distributed fine-tuning with low bandwidth. The method is a natural decentralized extension of memory-efficient Simultaneous Perturbation Stochastic Approximation (SPSA). Each iteration, each machine seeds a Random Number Generator (RNG) to perform local reproducible perturbations on model weights and calculate and exchange scalar projected gradients, which are then used to update each model. By using a (machine, sample) identifier as the random seed, each model can regenerate one another's perturbations. As machines only exchange single-byte projected gradients, this is highly communication efficient. There are also potential privacy benefits, as projected gradients may be calculated on different training data, and models never access the other's data. Our approach not only drastically reduces communication bandwidth requirements but also accommodates dynamic addition or removal of machines during the training process and retains the memory-efficient and inference-only advantages of recent work. We perform proof-of-concept experiments to demonstrate the potential usefulness of this method, building off of rich literature on distributed optimization and memory-efficient training.