 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformed Correctors for Discrete Diffusion Models
Jul 30, 2024Discrete diffusion modeling is a promising framework for modeling and generating data in discrete spaces. To sample from these models, different strategies present trade-offs between computation and sample quality. A predominant sampling strategy is predictor-corrector $\tau$-leaping, which simulates the continuous time generative process with discretized predictor steps and counteracts the accumulation of discretization error via corrector steps. However, for absorbing state diffusion, an important class of discrete diffusion models, the standard forward-backward corrector can be ineffective in fixing such errors, resulting in subpar sample quality. To remedy this problem, we propose a family of informed correctors that more reliably counteracts discretization error by leveraging information learned by the model. For further efficiency gains, we also propose $k$-Gillespie's, a sampling algorithm that better utilizes each model evaluation, while still enjoying the speed and flexibility of $\tau$-leaping. Across several real and synthetic datasets, we show that $k$-Gillespie's with informed correctors reliably produces higher quality samples at lower computational cost.
Revisiting Structured Variational Autoencoders
May 25, 2023
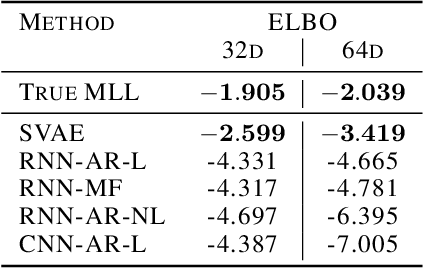
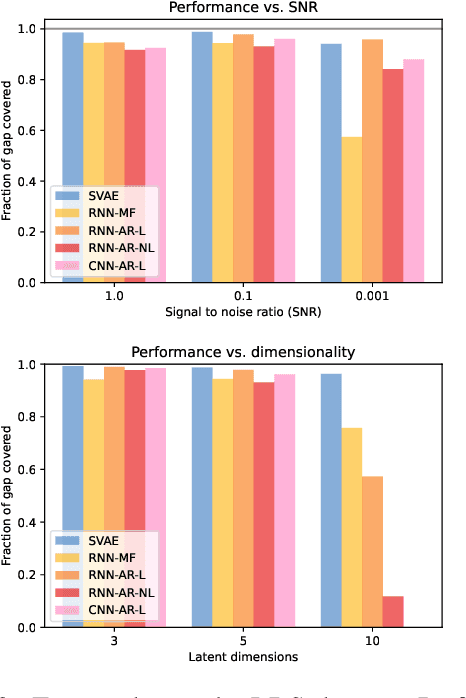
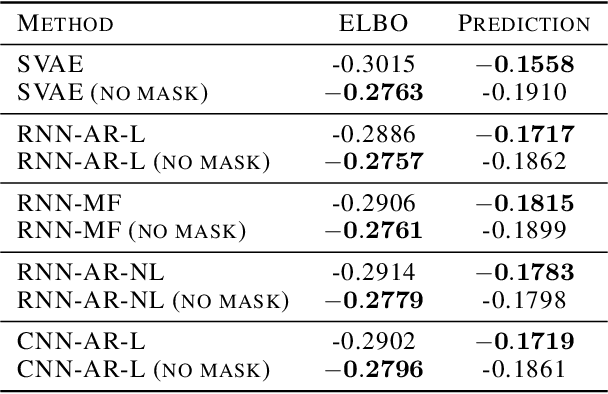
Structured variational autoencoders (SVAEs) combine probabilistic graphical model priors on latent variables, deep neural networks to link latent variables to observed data, and structure-exploiting algorithms for approximate posterior inference. These models are particularly appealing for sequential data, where the prior can capture temporal dependencies. However, despite their conceptual elegance, SVAEs have proven difficult to implement, and more general approaches have been favored in practice. Here, we revisit SVAEs using modern machine learning tools and demonstrate their advantages over more general alternatives in terms of both accuracy and efficiency. First, we develop a modern implementation for hardware acceleration, parallelization, and automatic differentiation of the message passing algorithms at the core of the SVAE. Second, we show that by exploiting structure in the prior, the SVAE learns more accurate models and posterior distributions, which translate into improved performance on prediction tasks. Third, we show how the SVAE can naturally handle missing data, and we leverage this ability to develop a novel, self-supervised training approach. Altogether, these results show that the time is ripe to revisit structured variational autoencoders.
BlockPuzzle - A Challenge in Physical Reasoning and Generalization for Robot Learning
Nov 30, 2018
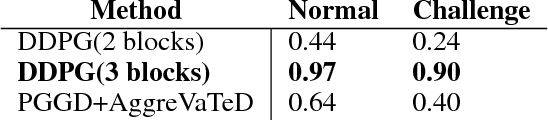
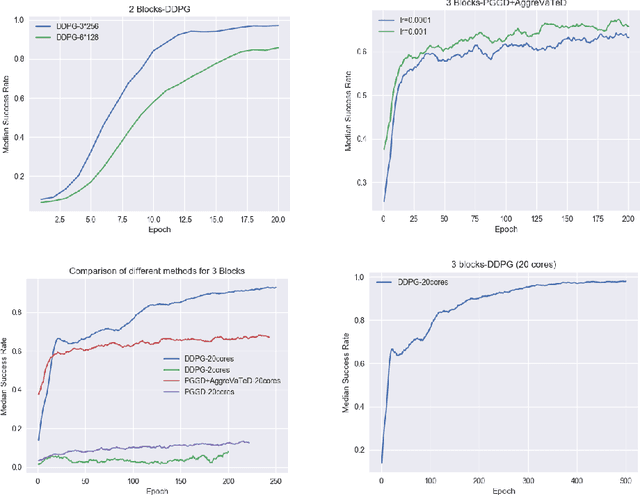

In this work we propose a novel task framework under which a variety of physical reasoning puzzles can be constructed using very simple rules. Under sparse reward settings, most of these tasks can be very challenging for a reinforcement learning agent to learn. We build several simple environments with this task framework in Mujoco and OpenAI gym and attempt to solve them. We are able to solve the environments by designing curricula to guide the agent in learning and using imitation learning methods to transfer knowledge from a simpler environment. This is only a first step for the task framework, and further research on how to solve the harder tasks and transfer knowledge between tasks is needed.
An integration of fast alignment and maximum-likelihood methods for electron subtomogram averaging and classification
Apr 04, 2018
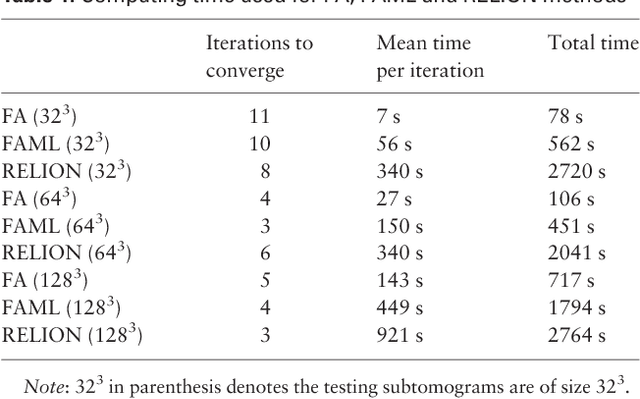
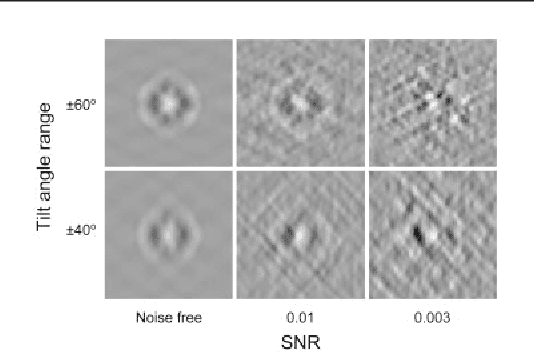
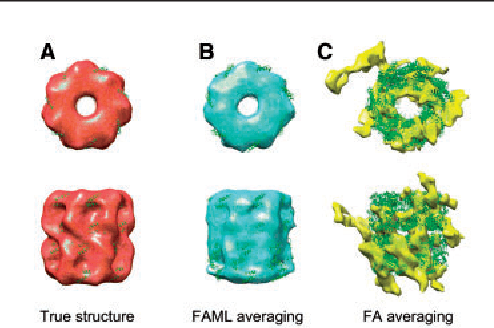
Motivation: Cellular Electron CryoTomography (CECT) is an emerging 3D imaging technique that visualizes subcellular organization of single cells at submolecular resolution and in near-native state. CECT captures large numbers of macromolecular complexes of highly diverse structures and abundances. However, the structural complexity and imaging limits complicate the systematic de novo structural recovery and recognition of these macromolecular complexes. Efficient and accurate reference-free subtomogram averaging and classification represent the most critical tasks for such analysis. Existing subtomogram alignment based methods are prone to the missing wedge effects and low signal-to-noise ratio (SNR). Moreover, existing maximum-likelihood based methods rely on integration operations, which are in principle computationally infeasible for accurate calculation. Results: Built on existing works, we propose an integrated method, Fast Alignment Maximum Likelihood method (FAML), which uses fast subtomogram alignment to sample sub-optimal rigid transformations. The transformations are then used to approximate integrals for maximum-likelihood update of subtomogram averages through expectation-maximization algorithm. Our tests on simulated and experimental subtomograms showed that, compared to our previously developed fast alignment method (FA), FAML is significantly more robust to noise and missing wedge effects with moderate increases of computation cost.Besides, FAML performs well with significantly fewer input subtomograms when the FA method fails. Therefore, FAML can serve as a key component for improved construction of initial structural models from macromolecules captured by CECT.
* 17 pages
"Dependency Bottleneck" in Auto-encoding Architectures: an Empirical Study
Feb 15, 2018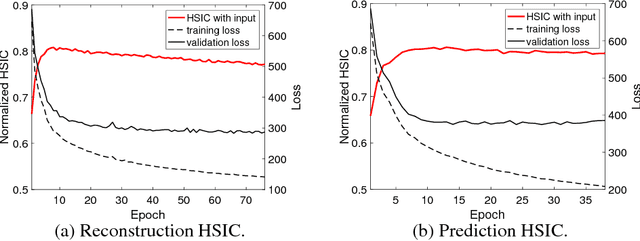
Recent works investigated the generalization properties in deep neural networks (DNNs) by studying the Information Bottleneck in DNNs. However, the mea- surement of the mutual information (MI) is often inaccurate due to the density estimation. To address this issue, we propose to measure the dependency instead of MI between layers in DNNs. Specifically, we propose to use Hilbert-Schmidt Independence Criterion (HSIC) as the dependency measure, which can measure the dependence of two random variables without estimating probability densities. Moreover, HSIC is a special case of the Squared-loss Mutual Information (SMI). In the experiment, we empirically evaluate the generalization property using HSIC in both the reconstruction and prediction auto-encoding (AE) architectures.