 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCFormer: A 5M-Parameter Transformer with Density-Guided Aggregation for Weakly-Supervised Crowd Counting
Dec 21, 2025Crowd counting typically relies on labor-intensive point-level annotations and computationally intensive backbones, restricting its scalability and deployment in resource-constrained environments. To address these challenges, this paper proposes the TCFormer, a tiny, ultra-lightweight, weakly-supervised transformer-based crowd counting framework with only 5 million parameters that achieves competitive performance. Firstly, a powerful yet efficient vision transformer is adopted as the feature extractor, the global context-aware capabilities of which provides semantic meaningful crowd features with a minimal memory footprint. Secondly, to compensate for the lack of spatial supervision, we design a feature aggregation mechanism termed the Learnable Density-Weighted Averaging module. This module dynamically re-weights local tokens according to predicted density scores, enabling the network to adaptively modulate regional features based on their specific density characteristics without the need for additional annotations. Furthermore, this paper introduces a density-level classification loss, which discretizes crowd density into distinct grades, thereby regularizing the training process and enhancing the model's classification power across varying levels of crowd density. Therefore, although TCformer is trained under a weakly-supervised paradigm utilizing only image-level global counts, the joint optimization of count and density-level losses enables the framework to achieve high estimation accuracy. Extensive experiments on four benchmarks including ShanghaiTech A/B, UCF-QNRF, and NWPU datasets demonstrate that our approach strikes a superior trade-off between parameter efficiency and counting accuracy and can be a good solution for crowd counting tasks in edge devices.
Cryptographic transformations over polyadic rings
Dec 14, 2025This article introduces a novel cryptographic paradigm based on nonderived polyadic algebraic structures. Traditional cryptosystems rely on binary operations within groups, rings, or fields, whose well-understood properties can be exploited in cryptanalysis. To overcome these vulnerabilities, we propose a shift to polyadic rings, which generalize classical rings by allowing operations of higher arity: an $m$-ary addition and an $n$-ary multiplication. The foundation of our approach is the construction of polyadic integers -- congruence classes of ordinary integers endowed with such $m$-ary and $n$-ary operations. A key innovation is the parameter-to-arity mapping $Φ(a,b)=(m,n)$, which links the parameters $(a,b)$ defining a congruence class to the specific arities required for algebraic closure. This mapping is mathematically intricate: it is non-injective, non-surjective, and multivalued. This complex, non-unique relationship forms the core of the proposed cryptosystem's security. We present two concrete encryption procedures that leverage this structure by encoding plaintext within the parameters of polyadic rings and transmitting information via polyadically quantized analog signals. In one method, plaintext is linked to the additive arity $m_{i}$ and secured using the summation of such signals; in the other, it is linked to a ring parameter $a_{i}$ and secured using their multiplication. In both cases, the "quantized" nature of polyadic operations generates systems of equations that are straightforward for a legitimate recipient with the correct key but exceptionally difficult for an attacker without it. The resulting framework promises a substantial increase in cryptographic security. This work establishes the theoretical foundation for this new class of encryption schemes and highlights their potential for constructing robust, next-generation cryptographic protocols.
Double Low-Rank 4D Tensor Decomposition for Circular RIS-Aided mmWave MIMO-NOMA System Channel Estimation in Mobility Scenarios
Jun 09, 2025Channel estimation is not only essential to highly reliable data transmission and massive device access but also an important component of the integrated sensing and communication (ISAC) in the sixth-generation (6G) mobile communication systems. In this paper, we consider a downlink channel estimation problem for circular reconfigurable intelligent surface (RIS)-aided millimeter-wave (mmWave) multiple-input multiple-output non-orthogonal multiple access (MIMO-NOMA) system in mobility scenarios. First, we propose a subframe partitioning scheme to facilitate the modeling of the received signal as a fourth-order tensor satisfying a canonical polyadic decomposition (CPD) form, thereby formulating the channel estimation problem as tensor decomposition and parameter extraction problems. Then, by exploiting both the global and local low-rank properties of the received signal, we propose a double low-rank 4D tensor decomposition model to decompose the received signal into four factor matrices, which is efficiently solved via alternating direction method of multipliers (ADMM). Subsequently, we propose a two-stage parameter estimation method based on the Jacobi-Anger expansion and the special structure of circular RIS to uniquely decouple the angle parameters. Furthermore, the time delay, Doppler shift, and channel gain parameters can also be estimated without ambiguities, and their estimation accuracy can be efficiently improved, especially at low signal-to-noise ratio (SNR). Finally, a concise closed-form expression for the Cram\'er-Rao bound (CRB) is derived as a performance benchmark. Numerical experiments are conducted to demonstrate the effectiveness of the proposed method compared with the other discussed methods.
1-Tb/s/λ Transmission over Record 10714-km AR-HCF
Apr 02, 2025We present the first single-channel 1.001-Tb/s DP-36QAM-PCS recirculating transmission over 73 loops of 146.77-km ultra-low-loss & low-IMI DNANF-5 fiber, achieving a record transmission distance of 10,714.28 km.
Medical Image Segmentation via Single-Source Domain Generalization with Random Amplitude Spectrum Synthesis
Sep 07, 2024



The field of medical image segmentation is challenged by domain generalization (DG) due to domain shifts in clinical datasets. The DG challenge is exacerbated by the scarcity of medical data and privacy concerns. Traditional single-source domain generalization (SSDG) methods primarily rely on stacking data augmentation techniques to minimize domain discrepancies. In this paper, we propose Random Amplitude Spectrum Synthesis (RASS) as a training augmentation for medical images. RASS enhances model generalization by simulating distribution changes from a frequency perspective. This strategy introduces variability by applying amplitude-dependent perturbations to ensure broad coverage of potential domain variations. Furthermore, we propose random mask shuffle and reconstruction components, which can enhance the ability of the backbone to process structural information and increase resilience intra- and cross-domain changes. The proposed Random Amplitude Spectrum Synthesis for Single-Source Domain Generalization (RAS^4DG) is validated on 3D fetal brain images and 2D fundus photography, and achieves an improved DG segmentation performance compared to other SSDG models.
Rethinking Video Segmentation with Masked Video Consistency: Did the Model Learn as Intended?
Aug 20, 2024Video segmentation aims at partitioning video sequences into meaningful segments based on objects or regions of interest within frames. Current video segmentation models are often derived from image segmentation techniques, which struggle to cope with small-scale or class-imbalanced video datasets. This leads to inconsistent segmentation results across frames. To address these issues, we propose a training strategy Masked Video Consistency, which enhances spatial and temporal feature aggregation. MVC introduces a training strategy that randomly masks image patches, compelling the network to predict the entire semantic segmentation, thus improving contextual information integration. Additionally, we introduce Object Masked Attention (OMA) to optimize the cross-attention mechanism by reducing the impact of irrelevant queries, thereby enhancing temporal modeling capabilities. Our approach, integrated into the latest decoupled universal video segmentation framework, achieves state-of-the-art performance across five datasets for three video segmentation tasks, demonstrating significant improvements over previous methods without increasing model parameters.
MCNet: A crowd denstity estimation network based on integrating multiscale attention module
Mar 29, 2024



Aiming at the metro video surveillance system has not been able to effectively solve the metro crowd density estimation problem, a Metro Crowd density estimation Network (called MCNet) is proposed to automatically classify crowd density level of passengers. Firstly, an Integrating Multi-scale Attention (IMA) module is proposed to enhance the ability of the plain classifiers to extract semantic crowd texture features to accommodate to the characteristics of the crowd texture feature. The innovation of the IMA module is to fuse the dilation convolution, multiscale feature extraction and attention mechanism to obtain multi-scale crowd feature activation from a larger receptive field with lower computational cost, and to strengthen the crowds activation state of convolutional features in top layers. Secondly, a novel lightweight crowd texture feature extraction network is proposed, which can directly process video frames and automatically extract texture features for crowd density estimation, while its faster image processing speed and fewer network parameters make it flexible to be deployed on embedded platforms with limited hardware resources. Finally, this paper integrates IMA module and the lightweight crowd texture feature extraction network to construct the MCNet, and validate the feasibility of this network on image classification dataset: Cifar10 and four crowd density datasets: PETS2009, Mall, QUT and SH_METRO to validate the MCNet whether can be a suitable solution for crowd density estimation in metro video surveillance where there are image processing challenges such as high density, high occlusion, perspective distortion and limited hardware resources.
Tensor Robust PCA with Nonconvex and Nonlocal Regularization
Nov 04, 2022Tensor robust principal component analysis (TRPCA) is a promising way for low-rank tensor recovery, which minimizes the convex surrogate of tensor rank by shrinking each tensor singular values equally. However, for real-world visual data, large singular values represent more signifiant information than small singular values. In this paper, we propose a nonconvex TRPCA (N-TRPCA) model based on the tensor adjustable logarithmic norm. Unlike TRPCA, our N-TRPCA can adaptively shrink small singular values more and shrink large singular values less. In addition, TRPCA assumes that the whole data tensor is of low rank. This assumption is hardly satisfied in practice for natural visual data, restricting the capability of TRPCA to recover the edges and texture details from noisy images and videos. To this end, we integrate nonlocal self-similarity into N-TRPCA, and further develop a nonconvex and nonlocal TRPCA (NN-TRPCA) model. Specifically, similar nonlocal patches are grouped as a tensor and then each group tensor is recovered by our N-TRPCA. Since the patches in one group are highly correlated, all group tensors have strong low-rank property, leading to an improvement of recovery performance. Experimental results demonstrate that the proposed NN-TRPCA outperforms some existing TRPCA methods in visual data recovery. The demo code is available at https://github.com/qguo2010/NN-TRPCA.
NTIRE 2021 Challenge on Quality Enhancement of Compressed Video: Methods and Results
May 02, 2021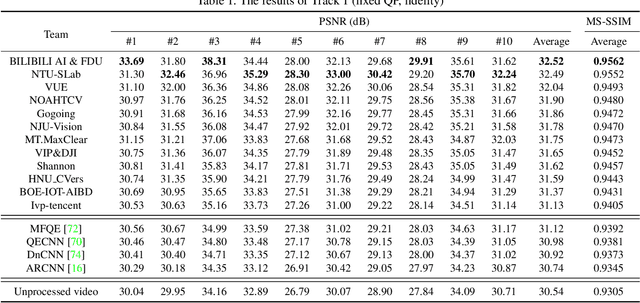
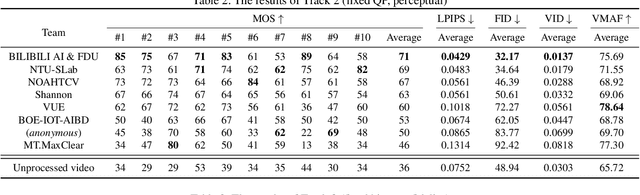
This paper reviews the first NTIRE challenge on quality enhancement of compressed video, with a focus on the proposed methods and results. In this challenge, the new Large-scale Diverse Video (LDV) dataset is employed. The challenge has three tracks. Tracks 1 and 2 aim at enhancing the videos compressed by HEVC at a fixed QP, while Track 3 is designed for enhancing the videos compressed by x265 at a fixed bit-rate. Besides, the quality enhancement of Tracks 1 and 3 targets at improving the fidelity (PSNR), and Track 2 targets at enhancing the perceptual quality. The three tracks totally attract 482 registrations. In the test phase, 12 teams, 8 teams and 11 teams submitted the final results of Tracks 1, 2 and 3, respectively. The proposed methods and solutions gauge the state-of-the-art of video quality enhancement. The homepage of the challenge: https://github.com/RenYang-home/NTIRE21_VEnh
TSDM: Tracking by SiamRPN++ with a Depth-refiner and a Mask-generator
May 08, 2020
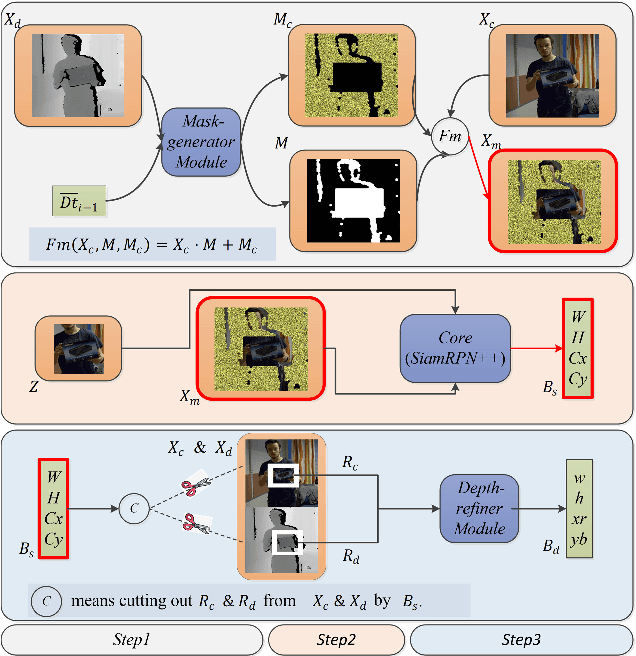
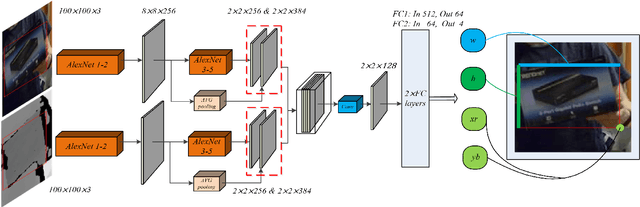
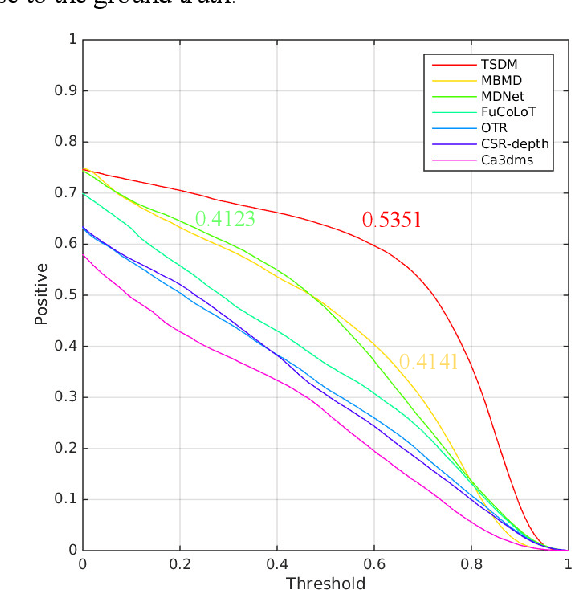
In a generic object tracking, depth (D) information provides informative cues for foreground-background separation and target bounding box regression. However, so far, few trackers have used depth information to play the important role aforementioned due to the lack of a suitable model. In this paper, a RGB-D tracker named TSDM is proposed, which is composed of a Mask-generator (M-g), SiamRPN++ and a Depth-refiner (D-r). The M-g generates the background masks, and updates them as the target 3D position changes. The D-r optimizes the target bounding box estimated by SiamRPN++, based on the spatial depth distribution difference between the target and the surrounding background. Extensive evaluation on the Princeton Tracking Benchmark and the Visual Object Tracking challenge shows that our tracker outperforms the state-of-the-art by a large margin while achieving 23 FPS. In addition, a light-weight variant can run at 31 FPS and thus it is practical for real world applications. Code and models of TSDM are available at https://github.com/lql-team/TSDM.