 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperOcc: Toward Cohesive Temporal Modeling for Superquadric-based Occupancy Prediction
Jan 22, 20263D occupancy prediction plays a pivotal role in the realm of autonomous driving, as it provides a comprehensive understanding of the driving environment. Most existing methods construct dense scene representations for occupancy prediction, overlooking the inherent sparsity of real-world driving scenes. Recently, 3D superquadric representation has emerged as a promising sparse alternative to dense scene representations due to the strong geometric expressiveness of superquadrics. However, existing superquadric frameworks still suffer from insufficient temporal modeling, a challenging trade-off between query sparsity and geometric expressiveness, and inefficient superquadric-to-voxel splatting. To address these issues, we propose SuperOcc, a novel framework for superquadric-based 3D occupancy prediction. SuperOcc incorporates three key designs: (1) a cohesive temporal modeling mechanism to simultaneously exploit view-centric and object-centric temporal cues; (2) a multi-superquadric decoding strategy to enhance geometric expressiveness without sacrificing query sparsity; and (3) an efficient superquadric-to-voxel splatting scheme to improve computational efficiency. Extensive experiments on the SurroundOcc and Occ3D benchmarks demonstrate that SuperOcc achieves state-of-the-art performance while maintaining superior efficiency. The code is available at https://github.com/Yzichen/SuperOcc.
PolarBEVDet: Exploring Polar Representation for Multi-View 3D Object Detection in Bird's-Eye-View
Aug 29, 2024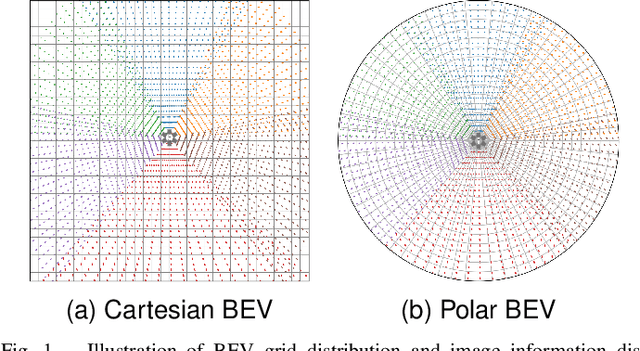
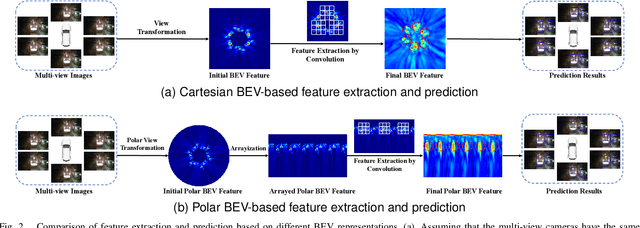
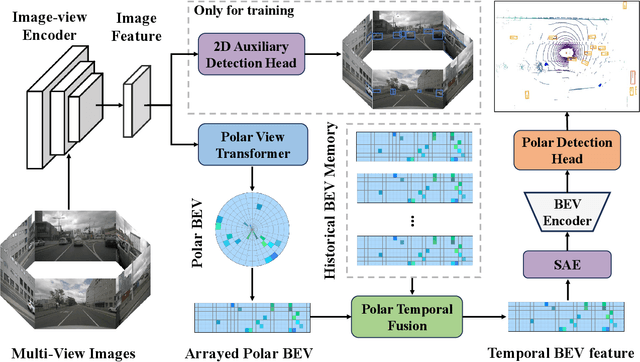
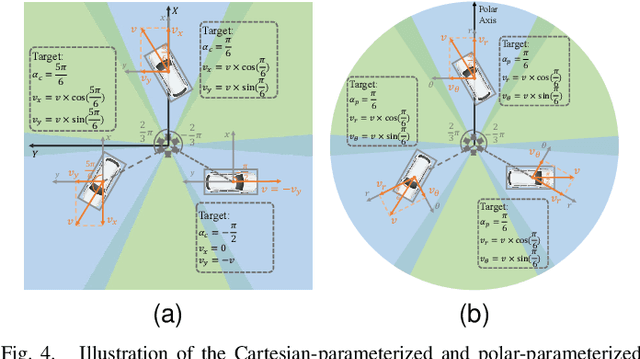
Recently, LSS-based multi-view 3D object detection provides an economical and deployment-friendly solution for autonomous driving. However, all the existing LSS-based methods transform multi-view image features into a Cartesian Bird's-Eye-View(BEV) representation, which does not take into account the non-uniform image information distribution and hardly exploits the view symmetry. In this paper, in order to adapt the image information distribution and preserve the view symmetry by regular convolution, we propose to employ the polar BEV representation to substitute the Cartesian BEV representation. To achieve this, we elaborately tailor three modules: a polar view transformer to generate the polar BEV representation, a polar temporal fusion module for fusing historical polar BEV features and a polar detection head to predict the polar-parameterized representation of the object. In addition, we design a 2D auxiliary detection head and a spatial attention enhancement module to improve the quality of feature extraction in perspective view and BEV, respectively. Finally, we integrate the above improvements into a novel multi-view 3D object detector, PolarBEVDet. Experiments on nuScenes show that PolarBEVDet achieves the superior performance. The code is available at https://github.com/Yzichen/PolarBEVDet.git.
DALNet: A Rail Detection Network Based on Dynamic Anchor Line
Aug 24, 2023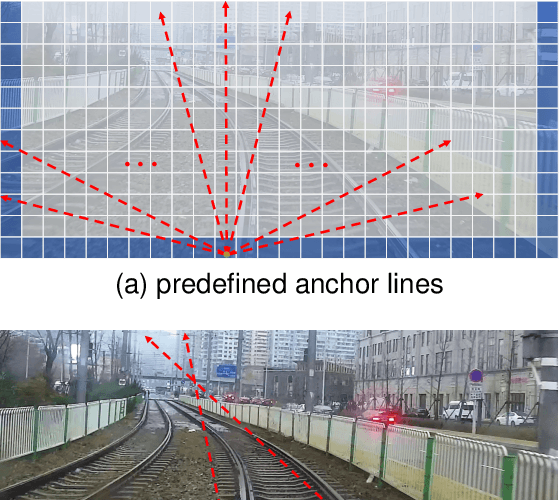
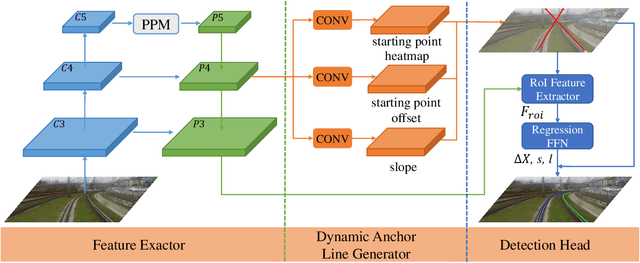
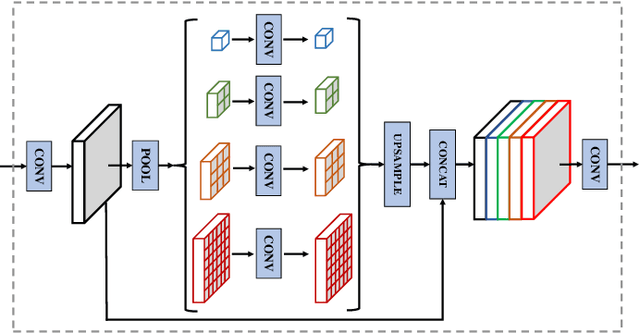

Rail detection is one of the key factors for intelligent train. In the paper, motivated by the anchor line-based lane detection methods, we propose a rail detection network called DALNet based on dynamic anchor line. Aiming to solve the problem that the predefined anchor line is image agnostic, we design a novel dynamic anchor line mechanism. It utilizes a dynamic anchor line generator to dynamically generate an appropriate anchor line for each rail instance based on the position and shape of the rails in the input image. These dynamically generated anchor lines can be considered as better position references to accurately localize the rails than the predefined anchor lines. In addition, we present a challenging urban rail detection dataset DL-Rail with high-quality annotations and scenario diversity. DL-Rail contains 7000 pairs of images and annotations along with scene tags, and it is expected to encourage the development of rail detection. We extensively compare DALNet with many competitive lane methods. The results show that our DALNet achieves state-of-the-art performance on our DL-Rail rail detection dataset and the popular Tusimple and LLAMAS lane detection benchmarks. The code will be released at https://github.com/Yzichen/mmLaneDet.
TSDM: Tracking by SiamRPN++ with a Depth-refiner and a Mask-generator
May 08, 2020
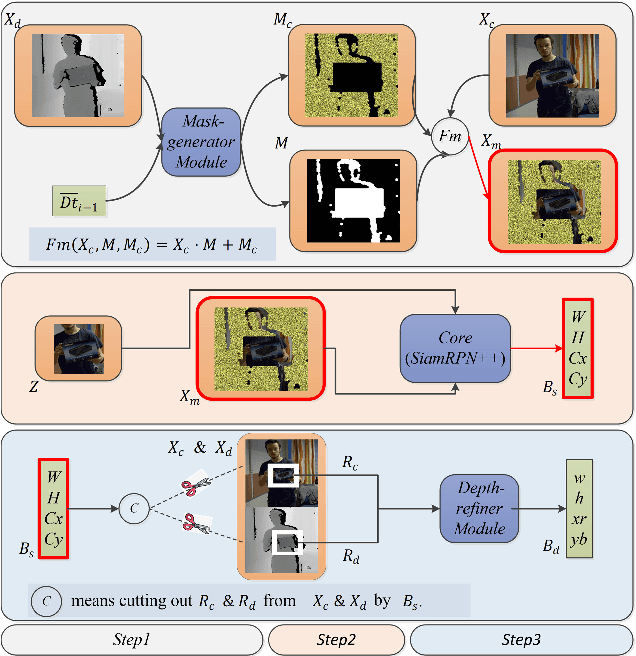
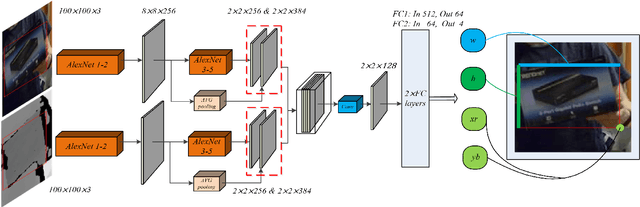
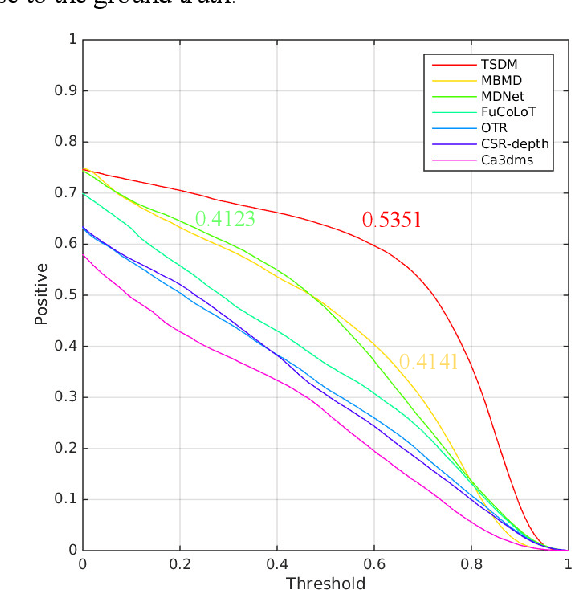
In a generic object tracking, depth (D) information provides informative cues for foreground-background separation and target bounding box regression. However, so far, few trackers have used depth information to play the important role aforementioned due to the lack of a suitable model. In this paper, a RGB-D tracker named TSDM is proposed, which is composed of a Mask-generator (M-g), SiamRPN++ and a Depth-refiner (D-r). The M-g generates the background masks, and updates them as the target 3D position changes. The D-r optimizes the target bounding box estimated by SiamRPN++, based on the spatial depth distribution difference between the target and the surrounding background. Extensive evaluation on the Princeton Tracking Benchmark and the Visual Object Tracking challenge shows that our tracker outperforms the state-of-the-art by a large margin while achieving 23 FPS. In addition, a light-weight variant can run at 31 FPS and thus it is practical for real world applications. Code and models of TSDM are available at https://github.com/lql-team/TSDM.