 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReshaping Action Error Distributions for Reliable Vision-Language-Action Models
Feb 04, 2026In robotic manipulation, vision-language-action (VLA) models have emerged as a promising paradigm for learning generalizable and scalable robot policies. Most existing VLA frameworks rely on standard supervised objectives, typically cross-entropy for discrete actions and mean squared error (MSE) for continuous action regression, which impose strong pointwise constraints on individual predictions. In this work, we focus on continuous-action VLA models and move beyond conventional MSE-based regression by reshaping action error distributions during training. Drawing on information-theoretic principles, we introduce Minimum Error Entropy (MEE) into modern VLA architectures and propose a trajectory-level MEE objective, together with two weighted variants, combined with MSE for continuous-action VLA training. We evaluate our approaches across standard, few-shot, and noisy settings on multiple representative VLA architectures, using simulation benchmarks such as LIBERO and SimplerEnv as well as real-world robotic manipulation tasks. Experimental results demonstrate consistent improvements in success rates and robustness across these settings. Under imbalanced data regimes, the gains persist within a well-characterized operating range, while incurring negligible additional training cost and no impact on inference efficiency. We further provide theoretical analyses that explain why MEE-based supervision is effective and characterize its practical range. Project Page: https://cognition2actionlab.github.io/VLA-TMEE.github.io/
Latent Reasoning VLA: Latent Thinking and Prediction for Vision-Language-Action Models
Feb 01, 2026Vision-Language-Action (VLA) models benefit from chain-of-thought (CoT) reasoning, but existing approaches incur high inference overhead and rely on discrete reasoning representations that mismatch continuous perception and control. We propose Latent Reasoning VLA (\textbf{LaRA-VLA}), a unified VLA framework that internalizes multi-modal CoT reasoning into continuous latent representations for embodied action. LaRA-VLA performs unified reasoning and prediction in latent space, eliminating explicit CoT generation at inference time and enabling efficient, action-oriented control. To realize latent embodied reasoning, we introduce a curriculum-based training paradigm that progressively transitions from explicit textual and visual CoT supervision to latent reasoning, and finally adapts latent reasoning dynamics to condition action generation. We construct two structured CoT datasets and evaluate LaRA-VLA on both simulation benchmarks and long-horizon real-robot manipulation tasks. Experimental results show that LaRA-VLA consistently outperforms state-of-the-art VLA methods while reducing inference latency by up to 90\% compared to explicit CoT-based approaches, demonstrating latent reasoning as an effective and efficient paradigm for real-time embodied control. Project Page: \href{https://loveju1y.github.io/Latent-Reasoning-VLA/}{LaRA-VLA Website}.
SuperOcc: Toward Cohesive Temporal Modeling for Superquadric-based Occupancy Prediction
Jan 22, 20263D occupancy prediction plays a pivotal role in the realm of autonomous driving, as it provides a comprehensive understanding of the driving environment. Most existing methods construct dense scene representations for occupancy prediction, overlooking the inherent sparsity of real-world driving scenes. Recently, 3D superquadric representation has emerged as a promising sparse alternative to dense scene representations due to the strong geometric expressiveness of superquadrics. However, existing superquadric frameworks still suffer from insufficient temporal modeling, a challenging trade-off between query sparsity and geometric expressiveness, and inefficient superquadric-to-voxel splatting. To address these issues, we propose SuperOcc, a novel framework for superquadric-based 3D occupancy prediction. SuperOcc incorporates three key designs: (1) a cohesive temporal modeling mechanism to simultaneously exploit view-centric and object-centric temporal cues; (2) a multi-superquadric decoding strategy to enhance geometric expressiveness without sacrificing query sparsity; and (3) an efficient superquadric-to-voxel splatting scheme to improve computational efficiency. Extensive experiments on the SurroundOcc and Occ3D benchmarks demonstrate that SuperOcc achieves state-of-the-art performance while maintaining superior efficiency. The code is available at https://github.com/Yzichen/SuperOcc.
StereoVLA: Enhancing Vision-Language-Action Models with Stereo Vision
Dec 26, 2025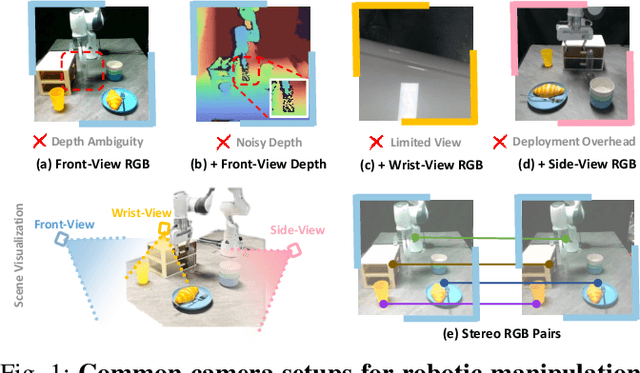
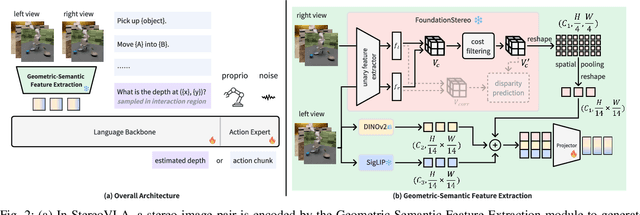
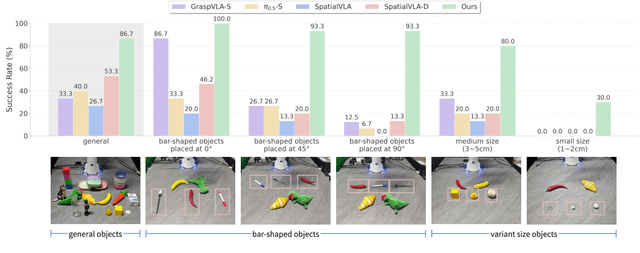
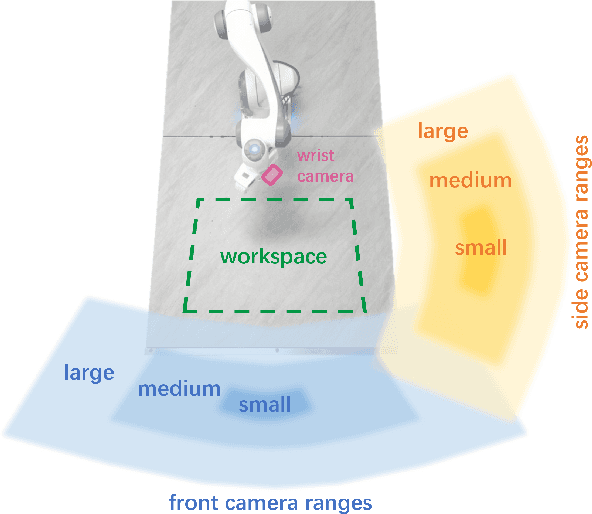
Stereo cameras closely mimic human binocular vision, providing rich spatial cues critical for precise robotic manipulation. Despite their advantage, the adoption of stereo vision in vision-language-action models (VLAs) remains underexplored. In this work, we present StereoVLA, a VLA model that leverages rich geometric cues from stereo vision. We propose a novel Geometric-Semantic Feature Extraction module that utilizes vision foundation models to extract and fuse two key features: 1) geometric features from subtle stereo-view differences for spatial perception; 2) semantic-rich features from the monocular view for instruction following. Additionally, we propose an auxiliary Interaction-Region Depth Estimation task to further enhance spatial perception and accelerate model convergence. Extensive experiments show that our approach outperforms baselines by a large margin in diverse tasks under the stereo setting and demonstrates strong robustness to camera pose variations.
ProPy: Building Interactive Prompt Pyramids upon CLIP for Partially Relevant Video Retrieval
Aug 26, 2025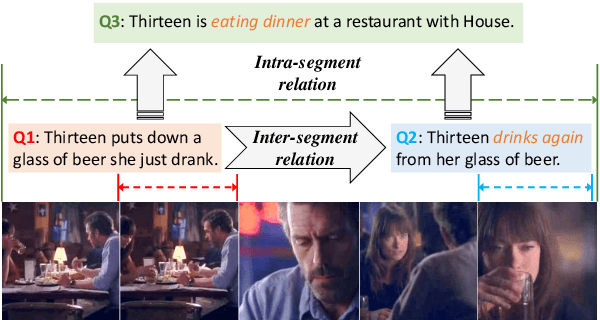

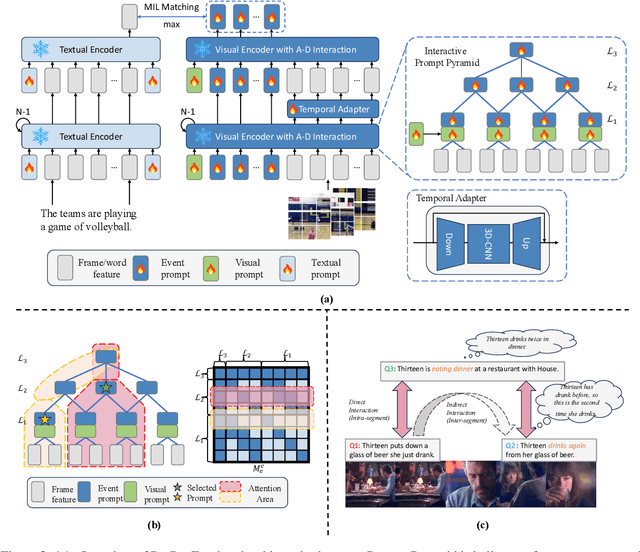
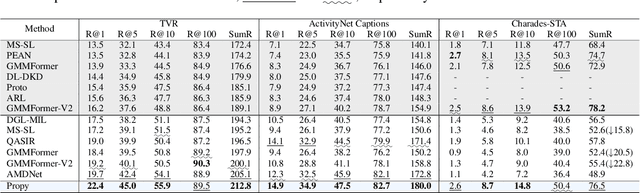
Partially Relevant Video Retrieval (PRVR) is a practical yet challenging task that involves retrieving videos based on queries relevant to only specific segments. While existing works follow the paradigm of developing models to process unimodal features, powerful pretrained vision-language models like CLIP remain underexplored in this field. To bridge this gap, we propose ProPy, a model with systematic architectural adaption of CLIP specifically designed for PRVR. Drawing insights from the semantic relevance of multi-granularity events, ProPy introduces two key innovations: (1) A Prompt Pyramid structure that organizes event prompts to capture semantics at multiple granularity levels, and (2) An Ancestor-Descendant Interaction Mechanism built on the pyramid that enables dynamic semantic interaction among events. With these designs, ProPy achieves SOTA performance on three public datasets, outperforming previous models by significant margins. Code is available at https://github.com/BUAAPY/ProPy.
A Reactive Framework for Whole-Body Motion Planning of Mobile Manipulators Combining Reinforcement Learning and SDF-Constrained Quadratic Programmi
Mar 31, 2025As an important branch of embodied artificial intelligence, mobile manipulators are increasingly applied in intelligent services, but their redundant degrees of freedom also limit efficient motion planning in cluttered environments. To address this issue, this paper proposes a hybrid learning and optimization framework for reactive whole-body motion planning of mobile manipulators. We develop the Bayesian distributional soft actor-critic (Bayes-DSAC) algorithm to improve the quality of value estimation and the convergence performance of the learning. Additionally, we introduce a quadratic programming method constrained by the signed distance field to enhance the safety of the obstacle avoidance motion. We conduct experiments and make comparison with standard benchmark. The experimental results verify that our proposed framework significantly improves the efficiency of reactive whole-body motion planning, reduces the planning time, and improves the success rate of motion planning. Additionally, the proposed reinforcement learning method ensures a rapid learning process in the whole-body planning task. The novel framework allows mobile manipulators to adapt to complex environments more safely and efficiently.
PolarBEVDet: Exploring Polar Representation for Multi-View 3D Object Detection in Bird's-Eye-View
Aug 29, 2024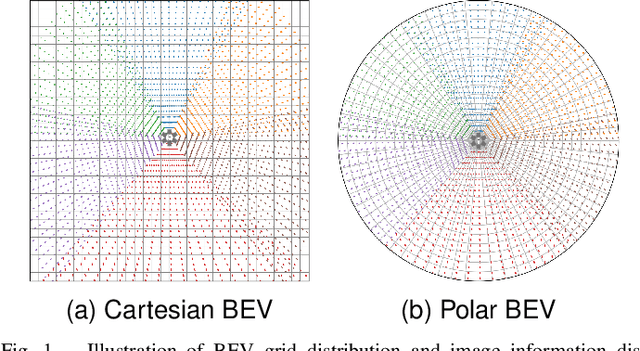
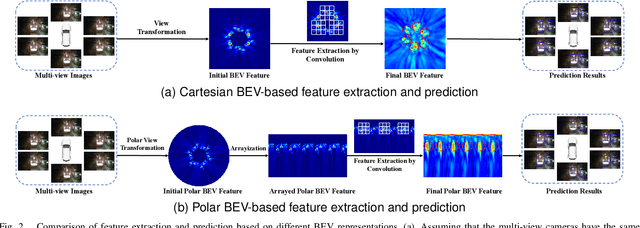
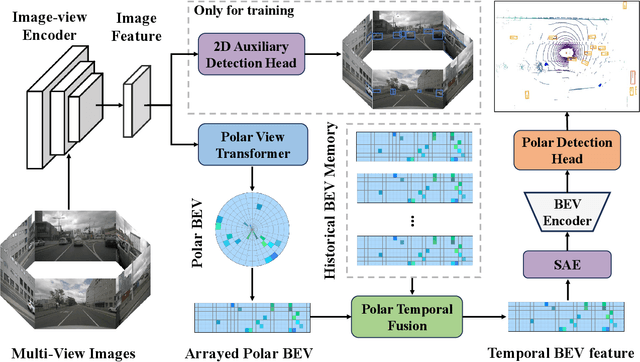
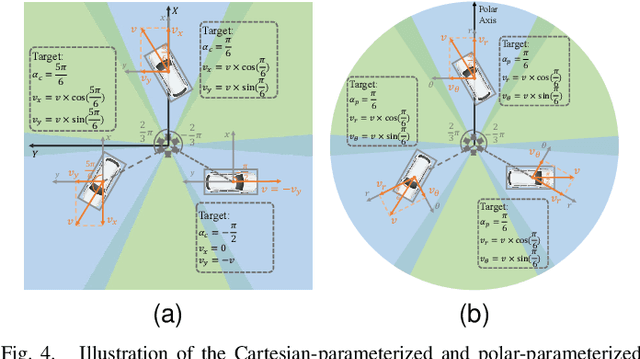
Recently, LSS-based multi-view 3D object detection provides an economical and deployment-friendly solution for autonomous driving. However, all the existing LSS-based methods transform multi-view image features into a Cartesian Bird's-Eye-View(BEV) representation, which does not take into account the non-uniform image information distribution and hardly exploits the view symmetry. In this paper, in order to adapt the image information distribution and preserve the view symmetry by regular convolution, we propose to employ the polar BEV representation to substitute the Cartesian BEV representation. To achieve this, we elaborately tailor three modules: a polar view transformer to generate the polar BEV representation, a polar temporal fusion module for fusing historical polar BEV features and a polar detection head to predict the polar-parameterized representation of the object. In addition, we design a 2D auxiliary detection head and a spatial attention enhancement module to improve the quality of feature extraction in perspective view and BEV, respectively. Finally, we integrate the above improvements into a novel multi-view 3D object detector, PolarBEVDet. Experiments on nuScenes show that PolarBEVDet achieves the superior performance. The code is available at https://github.com/Yzichen/PolarBEVDet.git.
Soar: Design and Deployment of A Smart Roadside Infrastructure System for Autonomous Driving
Apr 21, 2024
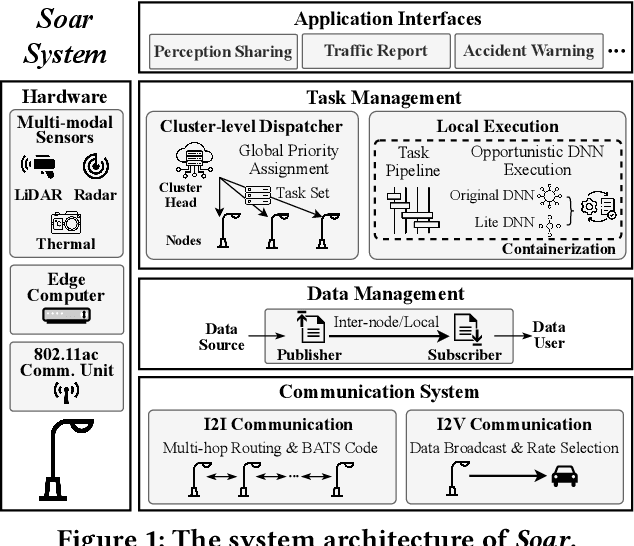
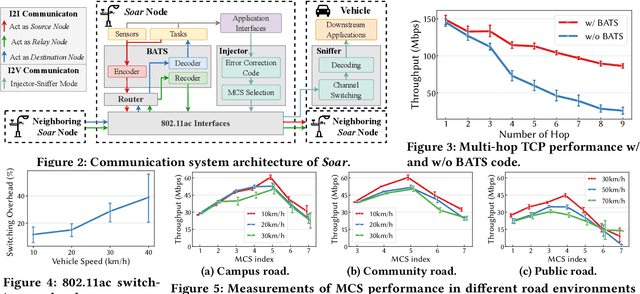
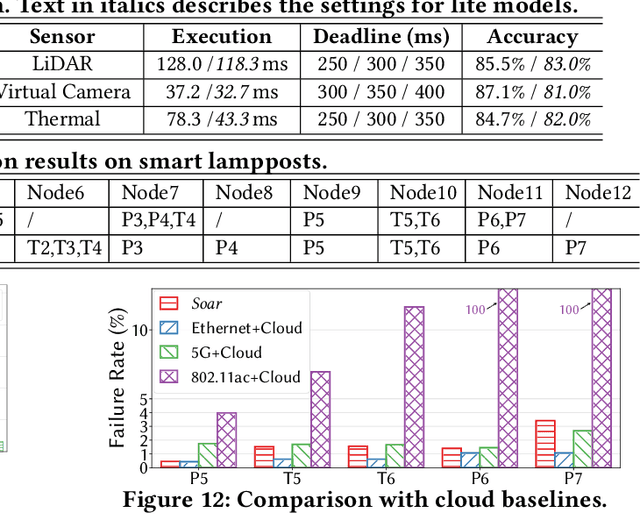
Recently,smart roadside infrastructure (SRI) has demonstrated the potential of achieving fully autonomous driving systems. To explore the potential of infrastructure-assisted autonomous driving, this paper presents the design and deployment of Soar, the first end-to-end SRI system specifically designed to support autonomous driving systems. Soar consists of both software and hardware components carefully designed to overcome various system and physical challenges. Soar can leverage the existing operational infrastructure like street lampposts for a lower barrier of adoption. Soar adopts a new communication architecture that comprises a bi-directional multi-hop I2I network and a downlink I2V broadcast service, which are designed based on off-the-shelf 802.11ac interfaces in an integrated manner. Soar also features a hierarchical DL task management framework to achieve desirable load balancing among nodes and enable them to collaborate efficiently to run multiple data-intensive autonomous driving applications. We deployed a total of 18 Soar nodes on existing lampposts on campus, which have been operational for over two years. Our real-world evaluation shows that Soar can support a diverse set of autonomous driving applications and achieve desirable real-time performance and high communication reliability. Our findings and experiences in this work offer key insights into the development and deployment of next-generation smart roadside infrastructure and autonomous driving systems.
Conformal Metamaterials with Active Tunability and Self-adaptivity for Magnetic Resonance Imaging
Sep 29, 2023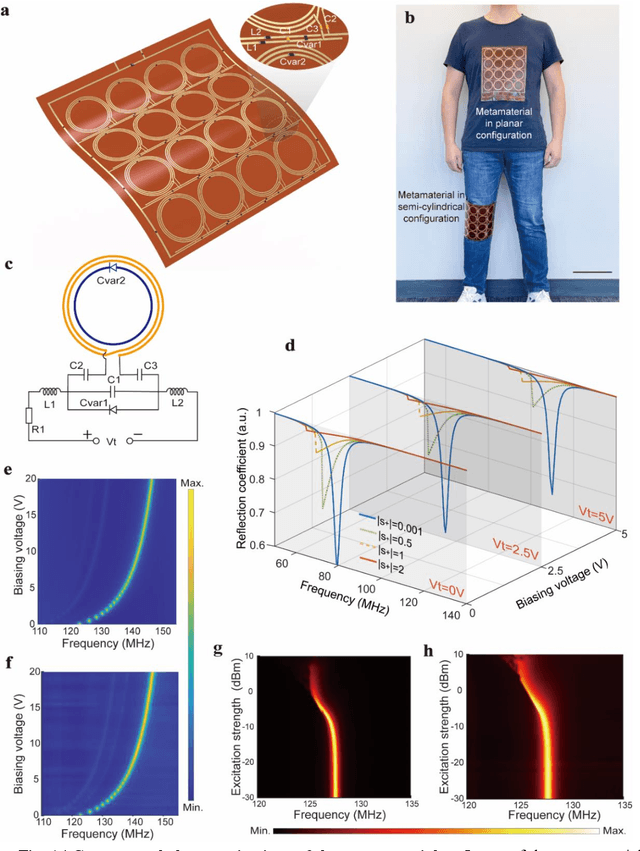
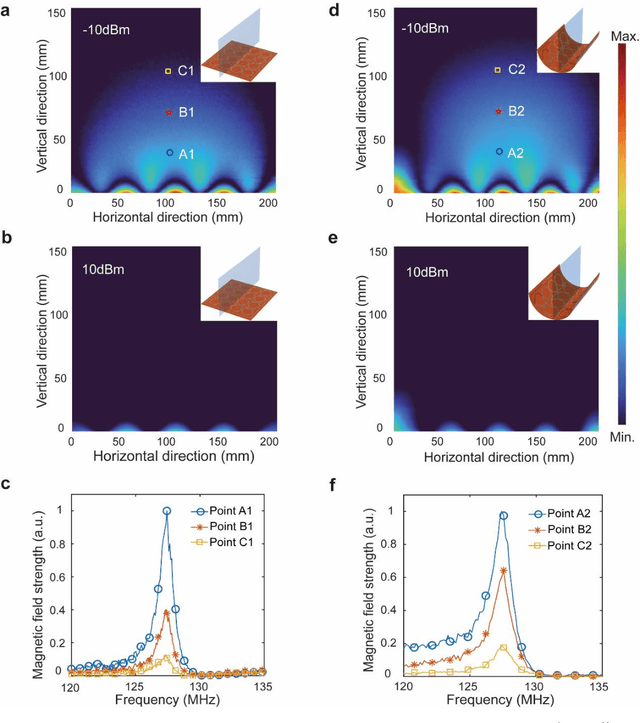
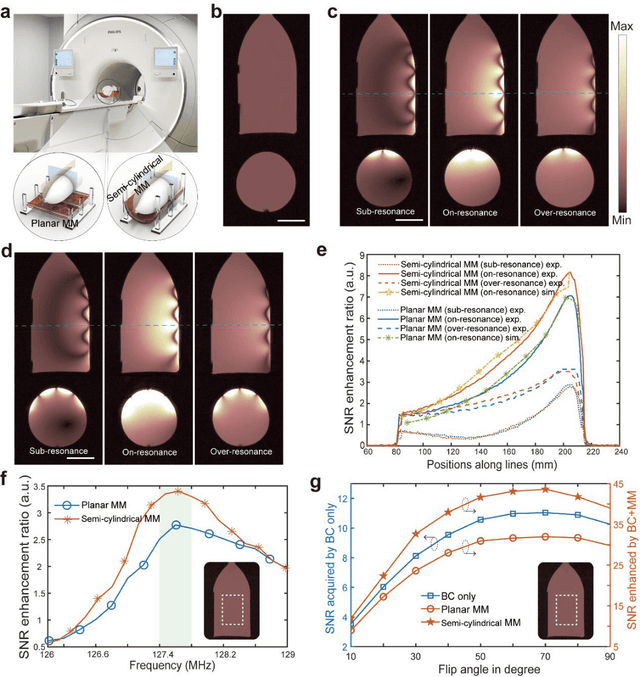
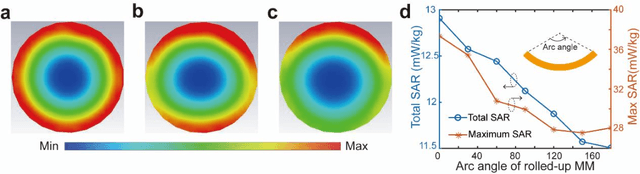
Ongoing effort has been devoted to applying metamaterials to boost the imaging performance of magnetic resonance imaging owing to their unique capacity for electromagnetic field confinement and enhancement. However, there are still major obstacles to widespread clinical adoption of conventional metamaterials due to several notable restrictions, namely: their typically bulky and rigid structures, deviations in their optimal resonance frequency, and their inevitable interference with the transmission RF field in MRI. Herein, we address these restrictions and report a conformal, smart metamaterial, which may not only be readily tuned to achieve the desired, precise frequency match with MRI by a controlling circuit, but is also capable of selectively amplifying the magnetic field during the RF reception phase by sensing the excitation signal strength passively, thereby remaining off during the RF transmission phase and thereby ensuring its optimal performance when applied to MRI as an additive technology. By addressing a host of current technological challenges, the metamaterial presented herein paves the way toward the wide-ranging utilization of metamaterials in clinical MRI, thereby translating this promising technology to the MRI bedside.
DALNet: A Rail Detection Network Based on Dynamic Anchor Line
Aug 24, 2023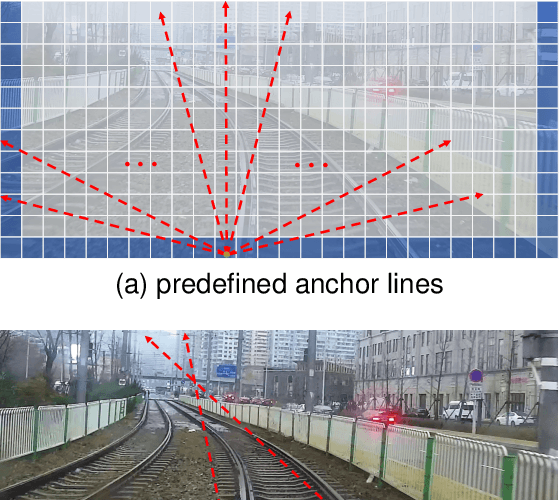
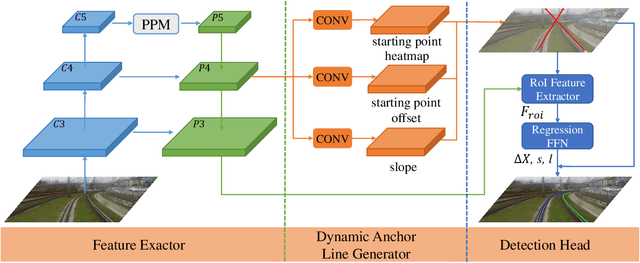
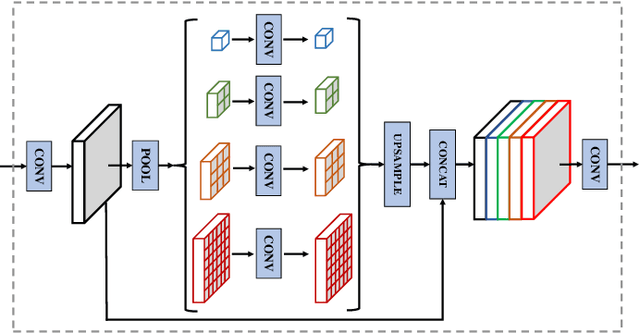

Rail detection is one of the key factors for intelligent train. In the paper, motivated by the anchor line-based lane detection methods, we propose a rail detection network called DALNet based on dynamic anchor line. Aiming to solve the problem that the predefined anchor line is image agnostic, we design a novel dynamic anchor line mechanism. It utilizes a dynamic anchor line generator to dynamically generate an appropriate anchor line for each rail instance based on the position and shape of the rails in the input image. These dynamically generated anchor lines can be considered as better position references to accurately localize the rails than the predefined anchor lines. In addition, we present a challenging urban rail detection dataset DL-Rail with high-quality annotations and scenario diversity. DL-Rail contains 7000 pairs of images and annotations along with scene tags, and it is expected to encourage the development of rail detection. We extensively compare DALNet with many competitive lane methods. The results show that our DALNet achieves state-of-the-art performance on our DL-Rail rail detection dataset and the popular Tusimple and LLAMAS lane detection benchmarks. The code will be released at https://github.com/Yzichen/mmLaneDet.