 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamsung Research China-Beijing at SemEval-2024 Task 3: A multi-stage framework for Emotion-Cause Pair Extraction in Conversations
Apr 25, 2024



In human-computer interaction, it is crucial for agents to respond to human by understanding their emotions. Unraveling the causes of emotions is more challenging. A new task named Multimodal Emotion-Cause Pair Extraction in Conversations is responsible for recognizing emotion and identifying causal expressions. In this study, we propose a multi-stage framework to generate emotion and extract the emotion causal pairs given the target emotion. In the first stage, Llama-2-based InstructERC is utilized to extract the emotion category of each utterance in a conversation. After emotion recognition, a two-stream attention model is employed to extract the emotion causal pairs given the target emotion for subtask 2 while MuTEC is employed to extract causal span for subtask 1. Our approach achieved first place for both of the two subtasks in the competition.
A Generalized Zero-Shot Framework for Emotion Recognition from Body Gestures
Oct 20, 2020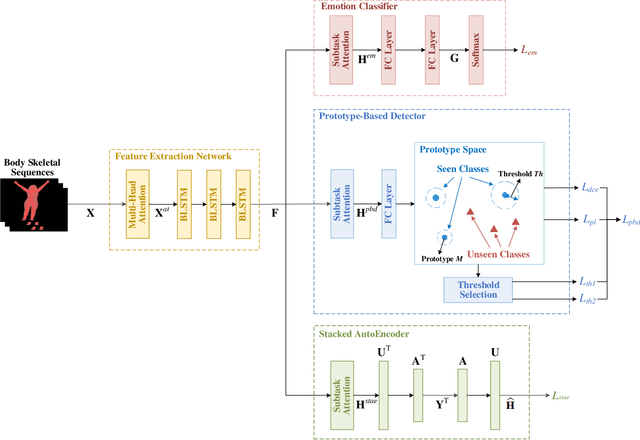

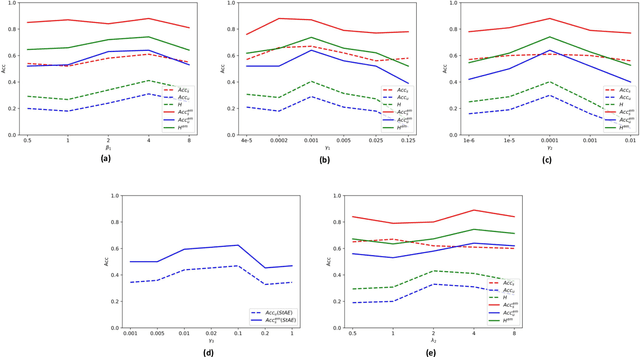
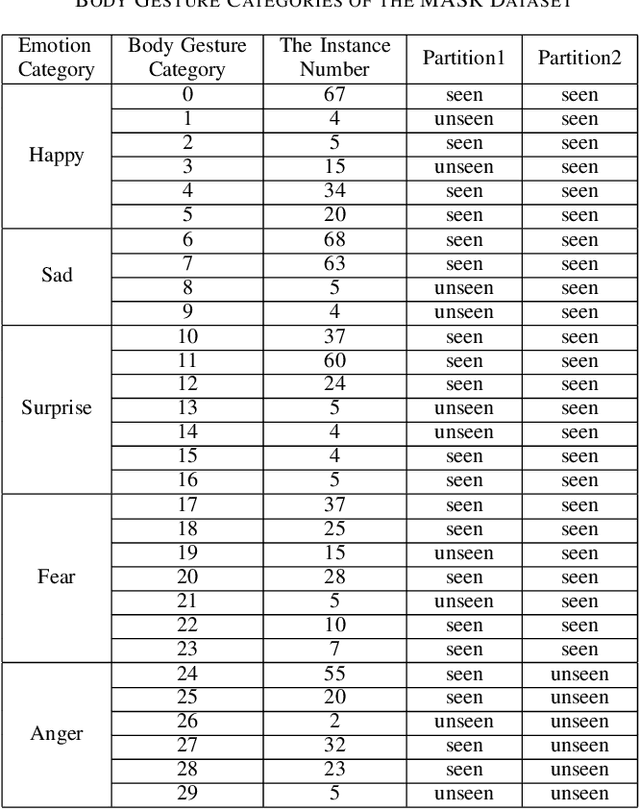
Although automatic emotion recognition from facial expressions and speech has made remarkable progress, emotion recognition from body gestures has not been thoroughly explored. People often use a variety of body language to express emotions, and it is difficult to enumerate all emotional body gestures and collect enough samples for each category. Therefore, recognizing new emotional body gestures is critical for better understanding human emotions. However, the existing methods fail to accurately determine which emotional state a new body gesture belongs to. In order to solve this problem, we introduce a Generalized Zero-Shot Learning (GZSL) framework, which consists of three branches to infer the emotional state of the new body gestures with only their semantic descriptions. The first branch is a Prototype-Based Detector (PBD) which is used to determine whether an sample belongs to a seen body gesture category and obtain the prediction results of the samples from the seen categories. The second branch is a Stacked AutoEncoder (StAE) with manifold regularization, which utilizes semantic representations to predict samples from unseen categories. Note that both of the above branches are for body gesture recognition. We further add an emotion classifier with a softmax layer as the third branch in order to better learn the feature representations for this emotion classification task. The input features for these three branches are learned by a shared feature extraction network, i.e., a Bidirectional Long Short-Term Memory Networks (BLSTM) with a self-attention module. We treat these three branches as subtasks and use multi-task learning strategies for joint training. The performance of our framework on an emotion recognition dataset is significantly superior to the traditional method of emotion classification and state-of-the-art zero-shot learning methods.
A Prototype-Based Generalized Zero-Shot Learning Framework for Hand Gesture Recognition
Sep 29, 2020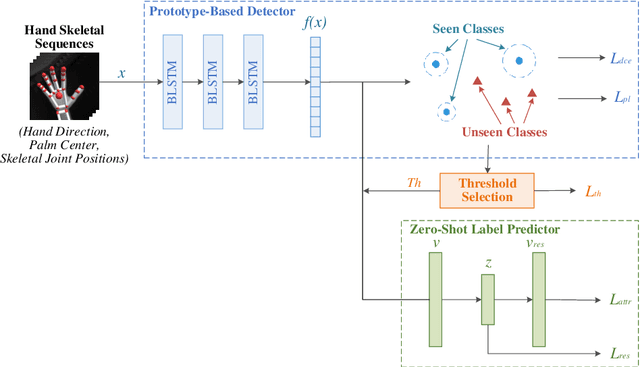
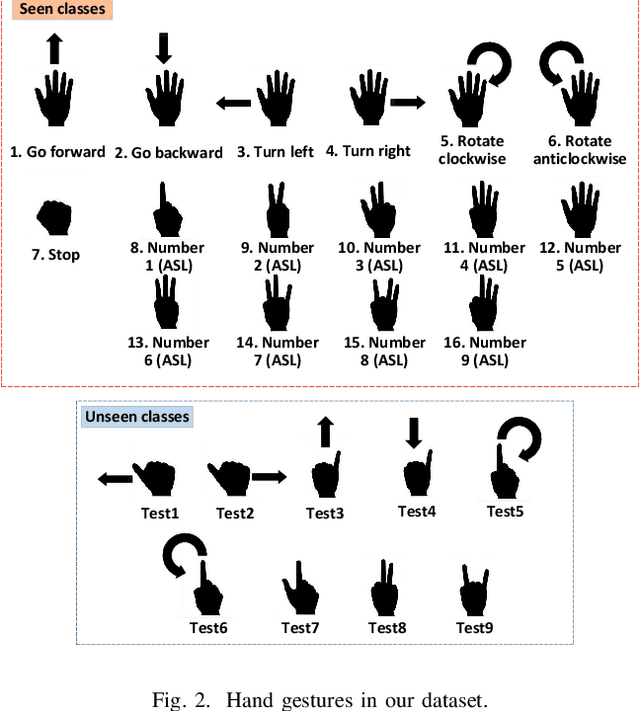
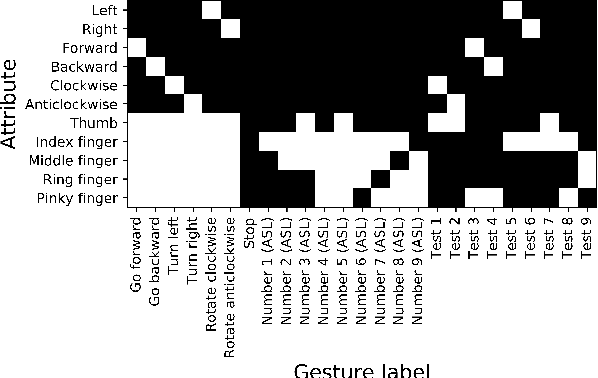
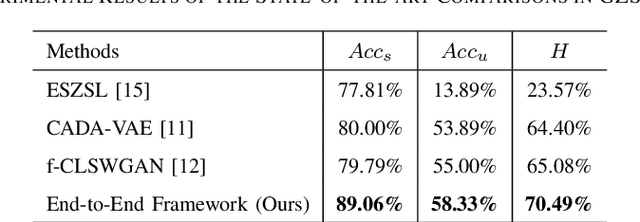
Hand gesture recognition plays a significant role in human-computer interaction for understanding various human gestures and their intent. However, most prior works can only recognize gestures of limited labeled classes and fail to adapt to new categories. The task of Generalized Zero-Shot Learning (GZSL) for hand gesture recognition aims to address the above issue by leveraging semantic representations and detecting both seen and unseen class samples. In this paper, we propose an end-to-end prototype-based GZSL framework for hand gesture recognition which consists of two branches. The first branch is a prototype-based detector that learns gesture representations and determines whether an input sample belongs to a seen or unseen category. The second branch is a zero-shot label predictor which takes the features of unseen classes as input and outputs predictions through a learned mapping mechanism between the feature and the semantic space. We further establish a hand gesture dataset that specifically targets this GZSL task, and comprehensive experiments on this dataset demonstrate the effectiveness of our proposed approach on recognizing both seen and unseen gestures.
Real-Time Human-Robot Interaction for a Service Robot Based on 3D Human Activity Recognition and Human-mimicking Decision Mechanism
Jan 11, 2019
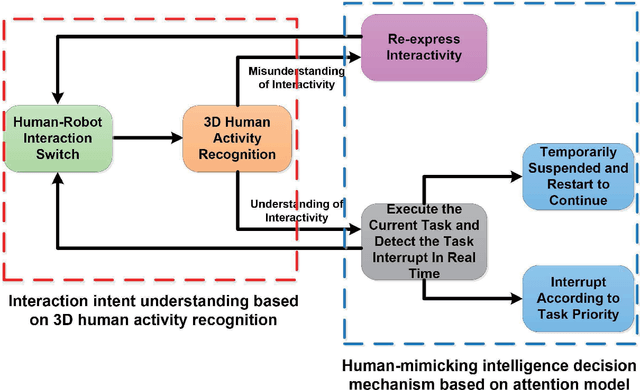
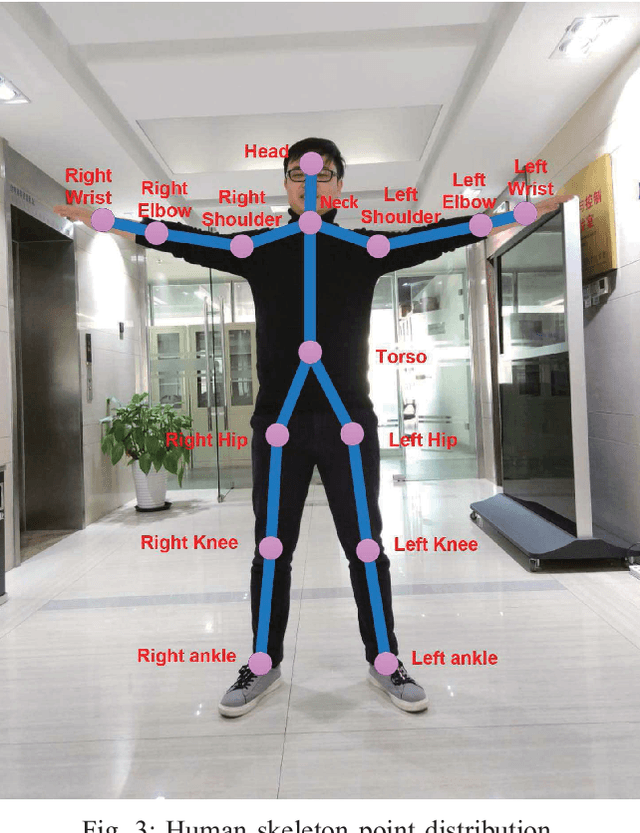
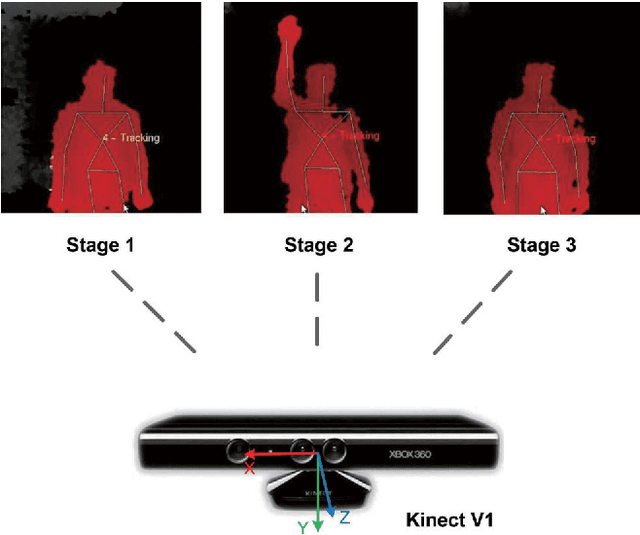
This paper describes the development of a real-time Human-Robot Interaction (HRI) system for a service robot based on 3D human activity recognition and human-like decision mechanism. The Human-Robot Interactive (HRI) system, which allows one person to interact with a service robot using natural body language, collects sequences of 3D skeleton joints comprising rich human movement information about the user via Microsoft Kinect. This information is used to train a three-layer Long-Short-Term Memory (LSTM) network for human action recognition. The robot understands user intent based on an online LSTM network test, and responds to the user via movements of the robotic arm or chassis. Furthermore, the human-like decision mechanism is also fused into this process, which allows the robot to instinctively decide whether to interrupt the current task according to task priority. The framework of the overall system is established on the Robot Operating System (ROS) platform. The real-life activity interaction between our service robot and the user was conducted to demonstrate the effectiveness of developed HRI system.