 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrescriptive Scaling Reveals the Evolution of Language Model Capabilities
Feb 17, 2026For deploying foundation models, practitioners increasingly need prescriptive scaling laws: given a pre training compute budget, what downstream accuracy is attainable with contemporary post training practice, and how stable is that mapping as the field evolves? Using large scale observational evaluations with 5k observational and 2k newly sampled data on model performance, we estimate capability boundaries, high conditional quantiles of benchmark scores as a function of log pre training FLOPs, via smoothed quantile regression with a monotone, saturating sigmoid parameterization. We validate the temporal reliability by fitting on earlier model generations and evaluating on later releases. Across various tasks, the estimated boundaries are mostly stable, with the exception of math reasoning that exhibits a consistently advancing boundary over time. We then extend our approach to analyze task dependent saturation and to probe contamination related shifts on math reasoning tasks. Finally, we introduce an efficient algorithm that recovers near full data frontiers using roughly 20% of evaluation budget. Together, our work releases the Proteus 2k, the latest model performance evaluation dataset, and introduces a practical methodology for translating compute budgets into reliable performance expectations and for monitoring when capability boundaries shift across time.
Adaptive Exploration for Latent-State Bandits
Feb 04, 2026The multi-armed bandit problem is a core framework for sequential decision-making under uncertainty, but classical algorithms often fail in environments with hidden, time-varying states that confound reward estimation and optimal action selection. We address key challenges arising from unobserved confounders, such as biased reward estimates and limited state information, by introducing a family of state-model-free bandit algorithms that leverage lagged contextual features and coordinated probing strategies. These implicitly track latent states and disambiguate state-dependent reward patterns. Our methods and their adaptive variants can learn optimal policies without explicit state modeling, combining computational efficiency with robust adaptation to non-stationary rewards. Empirical results across diverse settings demonstrate superior performance over classical approaches, and we provide practical recommendations for algorithm selection in real-world applications.
Sharp Structure-Agnostic Lower Bounds for General Functional Estimation
Dec 19, 2025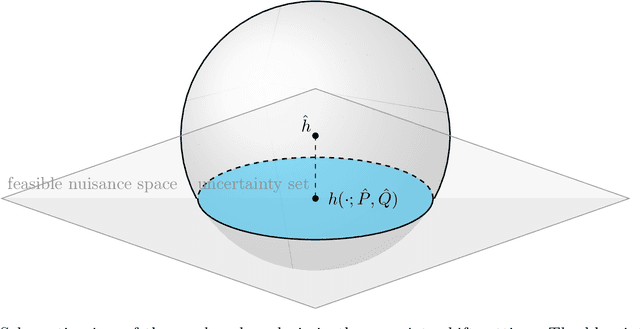
The design of efficient nonparametric estimators has long been a central problem in statistics, machine learning, and decision making. Classical optimal procedures often rely on strong structural assumptions, which can be misspecified in practice and complicate deployment. This limitation has sparked growing interest in structure-agnostic approaches -- methods that debias black-box nuisance estimates without imposing structural priors. Understanding the fundamental limits of these methods is therefore crucial. This paper provides a systematic investigation of the optimal error rates achievable by structure-agnostic estimators. We first show that, for estimating the average treatment effect (ATE), a central parameter in causal inference, doubly robust learning attains optimal structure-agnostic error rates. We then extend our analysis to a general class of functionals that depend on unknown nuisance functions and establish the structure-agnostic optimality of debiased/double machine learning (DML). We distinguish two regimes -- one where double robustness is attainable and one where it is not -- leading to different optimal rates for first-order debiasing, and show that DML is optimal in both regimes. Finally, we instantiate our general lower bounds by deriving explicit optimal rates that recover existing results and extend to additional estimands of interest. Our results provide theoretical validation for widely used first-order debiasing methods and guidance for practitioners seeking optimal approaches in the absence of structural assumptions. This paper generalizes and subsumes the ATE lower bound established in \citet{jin2024structure} by the same authors.
It's Hard to Be Normal: The Impact of Noise on Structure-agnostic Estimation
Jul 03, 2025Structure-agnostic causal inference studies how well one can estimate a treatment effect given black-box machine learning estimates of nuisance functions (like the impact of confounders on treatment and outcomes). Here, we find that the answer depends in a surprising way on the distribution of the treatment noise. Focusing on the partially linear model of \citet{robinson1988root}, we first show that the widely adopted double machine learning (DML) estimator is minimax rate-optimal for Gaussian treatment noise, resolving an open problem of \citet{mackey2018orthogonal}. Meanwhile, for independent non-Gaussian treatment noise, we show that DML is always suboptimal by constructing new practical procedures with higher-order robustness to nuisance errors. These \emph{ACE} procedures use structure-agnostic cumulant estimators to achieve $r$-th order insensitivity to nuisance errors whenever the $(r+1)$-st treatment cumulant is non-zero. We complement these core results with novel minimax guarantees for binary treatments in the partially linear model. Finally, using synthetic demand estimation experiments, we demonstrate the practical benefits of our higher-order robust estimators.
Discovering Hierarchical Latent Capabilities of Language Models via Causal Representation Learning
Jun 12, 2025Faithful evaluation of language model capabilities is crucial for deriving actionable insights that can inform model development. However, rigorous causal evaluations in this domain face significant methodological challenges, including complex confounding effects and prohibitive computational costs associated with extensive retraining. To tackle these challenges, we propose a causal representation learning framework wherein observed benchmark performance is modeled as a linear transformation of a few latent capability factors. Crucially, these latent factors are identified as causally interrelated after appropriately controlling for the base model as a common confounder. Applying this approach to a comprehensive dataset encompassing over 1500 models evaluated across six benchmarks from the Open LLM Leaderboard, we identify a concise three-node linear causal structure that reliably explains the observed performance variations. Further interpretation of this causal structure provides substantial scientific insights beyond simple numerical rankings: specifically, we reveal a clear causal direction starting from general problem-solving capabilities, advancing through instruction-following proficiency, and culminating in mathematical reasoning ability. Our results underscore the essential role of carefully controlling base model variations during evaluation, a step critical to accurately uncovering the underlying causal relationships among latent model capabilities.
Solving Inequality Proofs with Large Language Models
Jun 09, 2025Inequality proving, crucial across diverse scientific and mathematical fields, tests advanced reasoning skills such as discovering tight bounds and strategic theorem application. This makes it a distinct, demanding frontier for large language models (LLMs), offering insights beyond general mathematical problem-solving. Progress in this area is hampered by existing datasets that are often scarce, synthetic, or rigidly formal. We address this by proposing an informal yet verifiable task formulation, recasting inequality proving into two automatically checkable subtasks: bound estimation and relation prediction. Building on this, we release IneqMath, an expert-curated dataset of Olympiad-level inequalities, including a test set and training corpus enriched with step-wise solutions and theorem annotations. We also develop a novel LLM-as-judge evaluation framework, combining a final-answer judge with four step-wise judges designed to detect common reasoning flaws. A systematic evaluation of 29 leading LLMs on IneqMath reveals a surprising reality: even top models like o1 achieve less than 10% overall accuracy under step-wise scrutiny; this is a drop of up to 65.5% from their accuracy considering only final answer equivalence. This discrepancy exposes fragile deductive chains and a critical gap for current LLMs between merely finding an answer and constructing a rigorous proof. Scaling model size and increasing test-time computation yield limited gains in overall proof correctness. Instead, our findings highlight promising research directions such as theorem-guided reasoning and self-refinement. Code and data are available at https://ineqmath.github.io/.
Structure-agnostic Optimality of Doubly Robust Learning for Treatment Effect Estimation
Mar 02, 2024Average treatment effect estimation is the most central problem in causal inference with application to numerous disciplines. While many estimation strategies have been proposed in the literature, the statistical optimality of these methods has still remained an open area of investigation, especially in regimes where these methods do not achieve parametric rates. In this paper, we adopt the recently introduced structure-agnostic framework of statistical lower bounds, which poses no structural properties on the nuisance functions other than access to black-box estimators that achieve some statistical estimation rate. This framework is particularly appealing when one is only willing to consider estimation strategies that use non-parametric regression and classification oracles as black-box sub-processes. Within this framework, we prove the statistical optimality of the celebrated and widely used doubly robust estimators for both the Average Treatment Effect (ATE) and the Average Treatment Effect on the Treated (ATT), as well as weighted variants of the former, which arise in policy evaluation.
Dichotomy of Early and Late Phase Implicit Biases Can Provably Induce Grokking
Nov 30, 2023
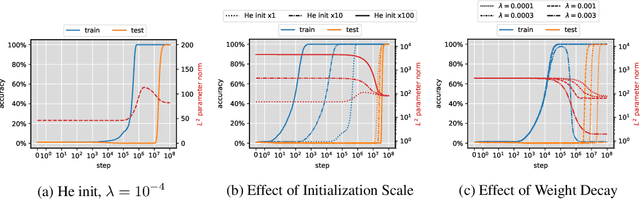


Recent work by Power et al. (2022) highlighted a surprising "grokking" phenomenon in learning arithmetic tasks: a neural net first "memorizes" the training set, resulting in perfect training accuracy but near-random test accuracy, and after training for sufficiently longer, it suddenly transitions to perfect test accuracy. This paper studies the grokking phenomenon in theoretical setups and shows that it can be induced by a dichotomy of early and late phase implicit biases. Specifically, when training homogeneous neural nets with large initialization and small weight decay on both classification and regression tasks, we prove that the training process gets trapped at a solution corresponding to a kernel predictor for a long time, and then a very sharp transition to min-norm/max-margin predictors occurs, leading to a dramatic change in test accuracy.
Learning Causal Representations from General Environments: Identifiability and Intrinsic Ambiguity
Nov 21, 2023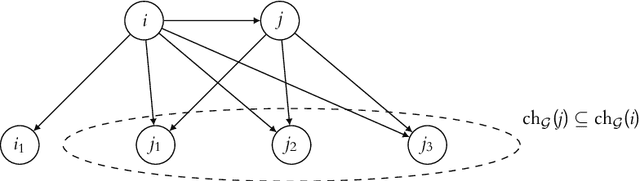
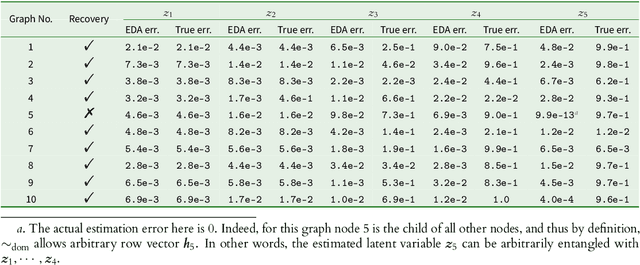

This paper studies causal representation learning, the task of recovering high-level latent variables and their causal relationships from low-level data that we observe, assuming access to observations generated from multiple environments. While existing works are able to prove full identifiability of the underlying data generating process, they typically assume access to single-node, hard interventions which is rather unrealistic in practice. The main contribution of this paper is characterize a notion of identifiability which is provably the best one can achieve when hard interventions are not available. First, for linear causal models, we provide identifiability guarantee for data observed from general environments without assuming any similarities between them. While the causal graph is shown to be fully recovered, the latent variables are only identified up to an effect-domination ambiguity (EDA). We then propose an algorithm, LiNGCReL which is guaranteed to recover the ground-truth model up to EDA, and we demonstrate its effectiveness via numerical experiments. Moving on to general non-parametric causal models, we prove the same idenfifiability guarantee assuming access to groups of soft interventions. Finally, we provide counterparts of our identifiability results, indicating that EDA is basically inevitable in our setting.
Understanding Incremental Learning of Gradient Descent: A Fine-grained Analysis of Matrix Sensing
Jan 27, 2023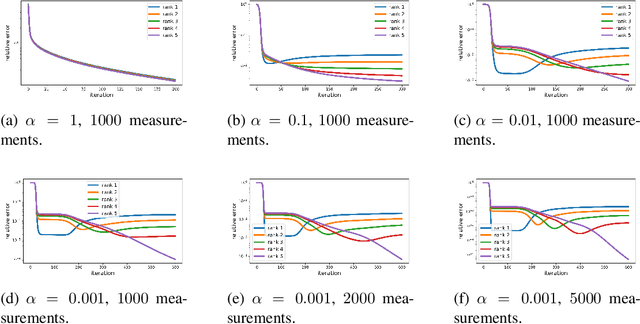
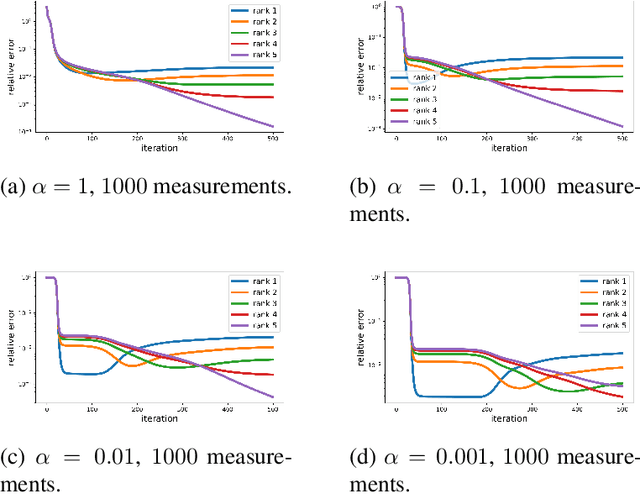
It is believed that Gradient Descent (GD) induces an implicit bias towards good generalization in training machine learning models. This paper provides a fine-grained analysis of the dynamics of GD for the matrix sensing problem, whose goal is to recover a low-rank ground-truth matrix from near-isotropic linear measurements. It is shown that GD with small initialization behaves similarly to the greedy low-rank learning heuristics (Li et al., 2020) and follows an incremental learning procedure (Gissin et al., 2019): GD sequentially learns solutions with increasing ranks until it recovers the ground truth matrix. Compared to existing works which only analyze the first learning phase for rank-1 solutions, our result provides characterizations for the whole learning process. Moreover, besides the over-parameterized regime that many prior works focused on, our analysis of the incremental learning procedure also applies to the under-parameterized regime. Finally, we conduct numerical experiments to confirm our theoretical findings.