 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Combinations: A Causal Inference Framework for Combinatorial Interventions
Paper and Code


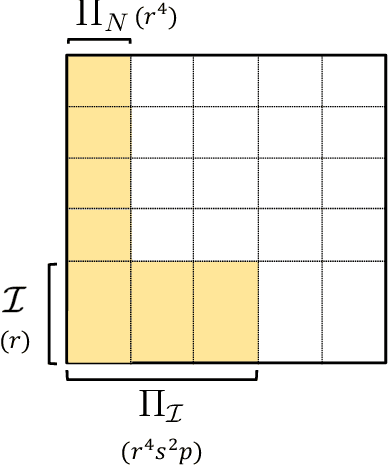

We consider a setting with $N$ heterogeneous units and $p$ interventions. Our goal is to learn unit-specific potential outcomes for any combination of these $p$ interventions, i.e., $N \times 2^p$ causal parameters. Choosing combinations of interventions is a problem that naturally arises in many applications such as factorial design experiments, recommendation engines (e.g., showing a set of movies that maximizes engagement for users), combination therapies in medicine, selecting important features for ML models, etc. Running $N \times 2^p$ experiments to estimate the various parameters is infeasible as $N$ and $p$ grow. Further, with observational data there is likely confounding, i.e., whether or not a unit is seen under a combination is correlated with its potential outcome under that combination. To address these challenges, we propose a novel model that imposes latent structure across both units and combinations. We assume latent similarity across units (i.e., the potential outcomes matrix is rank $r$) and regularity in how combinations interact (i.e., the coefficients in the Fourier expansion of the potential outcomes is $s$ sparse). We establish identification for all causal parameters despite unobserved confounding. We propose an estimation procedure, Synthetic Combinations, and establish finite-sample consistency under precise conditions on the observation pattern. Our results imply Synthetic Combinations consistently estimates unit-specific potential outcomes given $\text{poly}(r) \times (N + s^2p)$ observations. In comparison, previous methods that do not exploit structure across both units and combinations have sample complexity scaling as $\min(N \times s^2p, \ \ r \times (N + 2^p))$. We use Synthetic Combinations to propose a data-efficient experimental design mechanism for combinatorial causal inference. We corroborate our theoretical findings with numerical simulations.