 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatially Visual Perception for End-to-End Robotic Learning
Paper and Code
Nov 26, 2024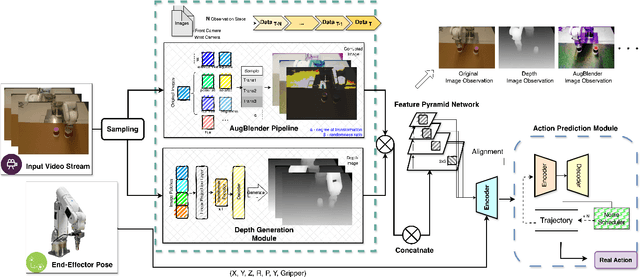
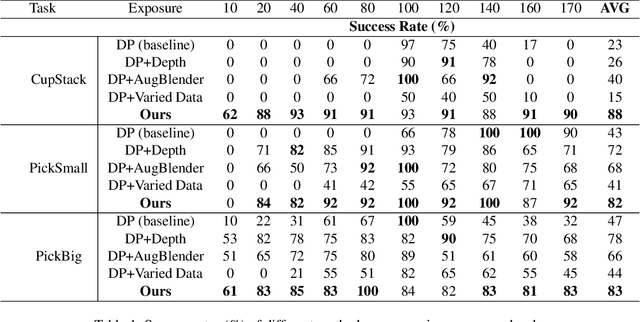


Recent advances in imitation learning have shown significant promise for robotic control and embodied intelligence. However, achieving robust generalization across diverse mounted camera observations remains a critical challenge. In this paper, we introduce a video-based spatial perception framework that leverages 3D spatial representations to address environmental variability, with a focus on handling lighting changes. Our approach integrates a novel image augmentation technique, AugBlender, with a state-of-the-art monocular depth estimation model trained on internet-scale data. Together, these components form a cohesive system designed to enhance robustness and adaptability in dynamic scenarios. Our results demonstrate that our approach significantly boosts the success rate across diverse camera exposures, where previous models experience performance collapse. Our findings highlight the potential of video-based spatial perception models in advancing robustness for end-to-end robotic learning, paving the way for scalable, low-cost solutions in embodied intelligence.