 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEBT-Policy: Energy Unlocks Emergent Physical Reasoning Capabilities
Oct 31, 2025Implicit policies parameterized by generative models, such as Diffusion Policy, have become the standard for policy learning and Vision-Language-Action (VLA) models in robotics. However, these approaches often suffer from high computational cost, exposure bias, and unstable inference dynamics, which lead to divergence under distribution shifts. Energy-Based Models (EBMs) address these issues by learning energy landscapes end-to-end and modeling equilibrium dynamics, offering improved robustness and reduced exposure bias. Yet, policies parameterized by EBMs have historically struggled to scale effectively. Recent work on Energy-Based Transformers (EBTs) demonstrates the scalability of EBMs to high-dimensional spaces, but their potential for solving core challenges in physically embodied models remains underexplored. We introduce a new energy-based architecture, EBT-Policy, that solves core issues in robotic and real-world settings. Across simulated and real-world tasks, EBT-Policy consistently outperforms diffusion-based policies, while requiring less training and inference computation. Remarkably, on some tasks it converges within just two inference steps, a 50x reduction compared to Diffusion Policy's 100. Moreover, EBT-Policy exhibits emergent capabilities not seen in prior models, such as zero-shot recovery from failed action sequences using only behavior cloning and without explicit retry training. By leveraging its scalar energy for uncertainty-aware inference and dynamic compute allocation, EBT-Policy offers a promising path toward robust, generalizable robot behavior under distribution shifts.
Spatial RoboGrasp: Generalized Robotic Grasping Control Policy
May 27, 2025



Achieving generalizable and precise robotic manipulation across diverse environments remains a critical challenge, largely due to limitations in spatial perception. While prior imitation-learning approaches have made progress, their reliance on raw RGB inputs and handcrafted features often leads to overfitting and poor 3D reasoning under varied lighting, occlusion, and object conditions. In this paper, we propose a unified framework that couples robust multimodal perception with reliable grasp prediction. Our architecture fuses domain-randomized augmentation, monocular depth estimation, and a depth-aware 6-DoF Grasp Prompt into a single spatial representation for downstream action planning. Conditioned on this encoding and a high-level task prompt, our diffusion-based policy yields precise action sequences, achieving up to 40% improvement in grasp success and 45% higher task success rates under environmental variation. These results demonstrate that spatially grounded perception, paired with diffusion-based imitation learning, offers a scalable and robust solution for general-purpose robotic grasping.
RoboGrasp: A Universal Grasping Policy for Robust Robotic Control
Feb 05, 2025



Imitation learning and world models have shown significant promise in advancing generalizable robotic learning, with robotic grasping remaining a critical challenge for achieving precise manipulation. Existing methods often rely heavily on robot arm state data and RGB images, leading to overfitting to specific object shapes or positions. To address these limitations, we propose RoboGrasp, a universal grasping policy framework that integrates pretrained grasp detection models with robotic learning. By leveraging robust visual guidance from object detection and segmentation tasks, RoboGrasp significantly enhances grasp precision, stability, and generalizability, achieving up to 34% higher success rates in few-shot learning and grasping box prompt tasks. Built on diffusion-based methods, RoboGrasp is adaptable to various robotic learning paradigms, enabling precise and reliable manipulation across diverse and complex scenarios. This framework represents a scalable and versatile solution for tackling real-world challenges in robotic grasping.
Spatially Visual Perception for End-to-End Robotic Learning
Nov 26, 2024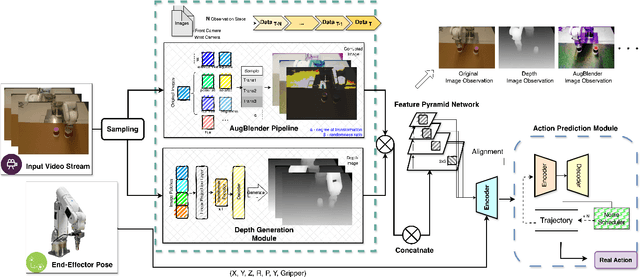
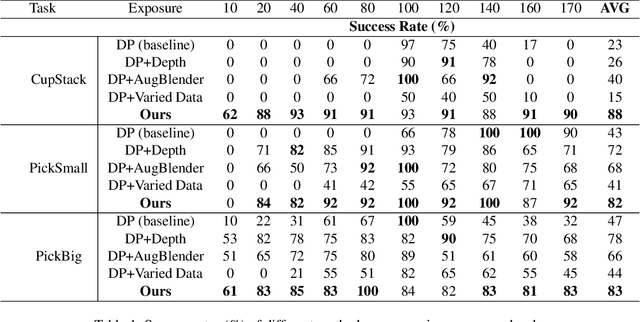


Recent advances in imitation learning have shown significant promise for robotic control and embodied intelligence. However, achieving robust generalization across diverse mounted camera observations remains a critical challenge. In this paper, we introduce a video-based spatial perception framework that leverages 3D spatial representations to address environmental variability, with a focus on handling lighting changes. Our approach integrates a novel image augmentation technique, AugBlender, with a state-of-the-art monocular depth estimation model trained on internet-scale data. Together, these components form a cohesive system designed to enhance robustness and adaptability in dynamic scenarios. Our results demonstrate that our approach significantly boosts the success rate across diverse camera exposures, where previous models experience performance collapse. Our findings highlight the potential of video-based spatial perception models in advancing robustness for end-to-end robotic learning, paving the way for scalable, low-cost solutions in embodied intelligence.
Physics-guided Noise Neural Proxy for Low-light Raw Image Denoising
Oct 13, 2023



Low-light raw image denoising plays a crucial role in mobile photography, and learning-based methods have become the mainstream approach. Training the learning-based methods with synthetic data emerges as an efficient and practical alternative to paired real data. However, the quality of synthetic data is inherently limited by the low accuracy of the noise model, which decreases the performance of low-light raw image denoising. In this paper, we develop a novel framework for accurate noise modeling that learns a physics-guided noise neural proxy (PNNP) from dark frames. PNNP integrates three efficient techniques: physics-guided noise decoupling (PND), physics-guided proxy model (PPM), and differentiable distribution-oriented loss (DDL). The PND decouples the dark frame into different components and handles different levels of noise in a flexible manner, which reduces the complexity of the noise neural proxy. The PPM incorporates physical priors to effectively constrain the generated noise, which promotes the accuracy of the noise neural proxy. The DDL provides explicit and reliable supervision for noise modeling, which promotes the precision of the noise neural proxy. Extensive experiments on public low-light raw image denoising datasets and real low-light imaging scenarios demonstrate the superior performance of our PNNP framework.
MeetDot: Videoconferencing with Live Translation Captions
Sep 20, 2021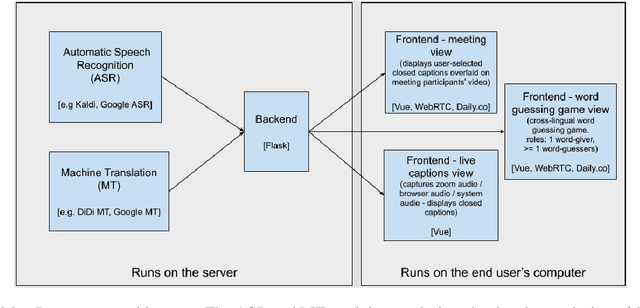

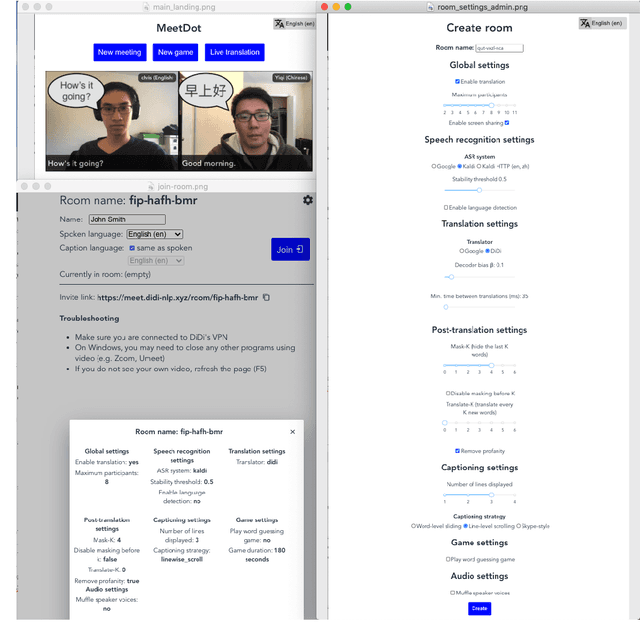
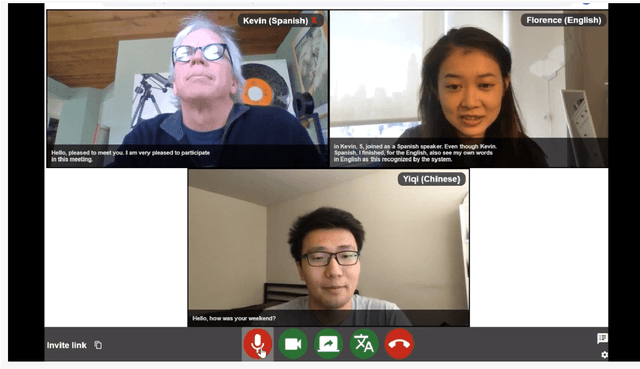
We present MeetDot, a videoconferencing system with live translation captions overlaid on screen. The system aims to facilitate conversation between people who speak different languages, thereby reducing communication barriers between multilingual participants. Currently, our system supports speech and captions in 4 languages and combines automatic speech recognition (ASR) and machine translation (MT) in a cascade. We use the re-translation strategy to translate the streamed speech, resulting in caption flicker. Additionally, our system has very strict latency requirements to have acceptable call quality. We implement several features to enhance user experience and reduce their cognitive load, such as smooth scrolling captions and reducing caption flicker. The modular architecture allows us to integrate different ASR and MT services in our backend. Our system provides an integrated evaluation suite to optimize key intrinsic evaluation metrics such as accuracy, latency and erasure. Finally, we present an innovative cross-lingual word-guessing game as an extrinsic evaluation metric to measure end-to-end system performance. We plan to make our system open-source for research purposes.
MEEP: An Open-Source Platform for Human-Human Dialog Collection and End-to-End Agent Training
Oct 09, 2020
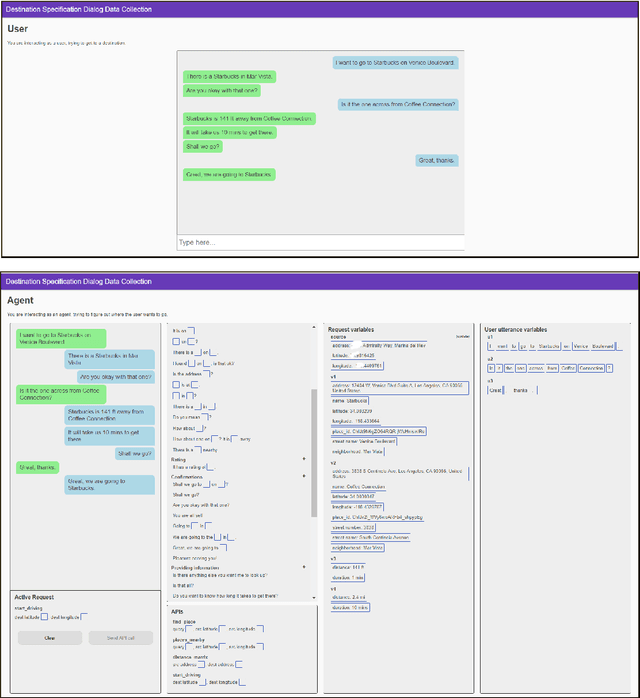


We create a new task-oriented dialog platform (MEEP) where agents are given considerable freedom in terms of utterances and API calls, but are constrained to work within a push-button environment. We include facilities for collecting human-human dialog corpora, and for training automatic agents in an end-to-end fashion. We demonstrate MEEP with a dialog assistant that lets users specify trip destinations.