 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeetDot: Videoconferencing with Live Translation Captions
Sep 20, 2021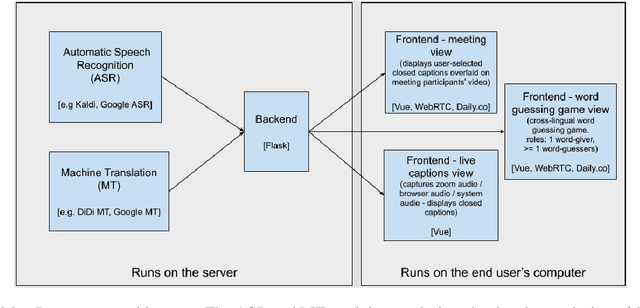

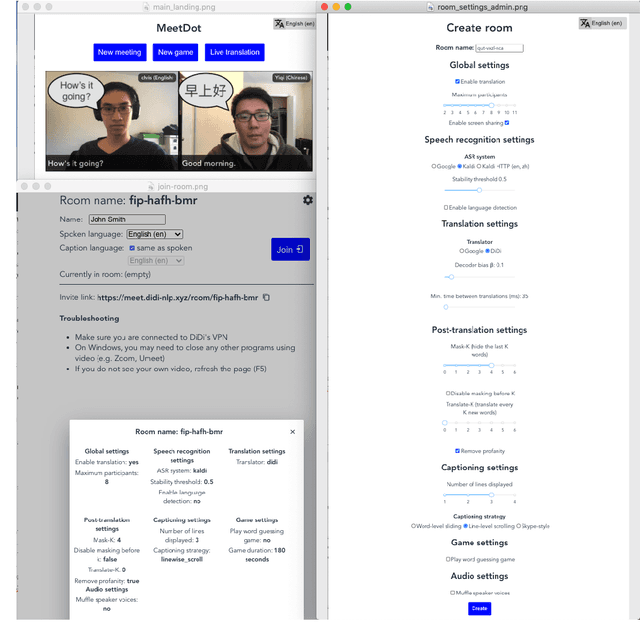
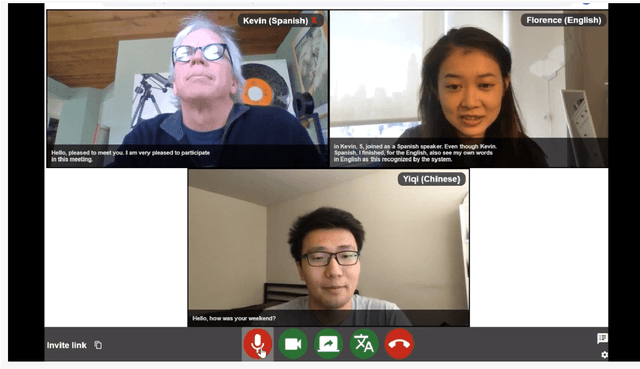
We present MeetDot, a videoconferencing system with live translation captions overlaid on screen. The system aims to facilitate conversation between people who speak different languages, thereby reducing communication barriers between multilingual participants. Currently, our system supports speech and captions in 4 languages and combines automatic speech recognition (ASR) and machine translation (MT) in a cascade. We use the re-translation strategy to translate the streamed speech, resulting in caption flicker. Additionally, our system has very strict latency requirements to have acceptable call quality. We implement several features to enhance user experience and reduce their cognitive load, such as smooth scrolling captions and reducing caption flicker. The modular architecture allows us to integrate different ASR and MT services in our backend. Our system provides an integrated evaluation suite to optimize key intrinsic evaluation metrics such as accuracy, latency and erasure. Finally, we present an innovative cross-lingual word-guessing game as an extrinsic evaluation metric to measure end-to-end system performance. We plan to make our system open-source for research purposes.
MEEP: An Open-Source Platform for Human-Human Dialog Collection and End-to-End Agent Training
Oct 09, 2020
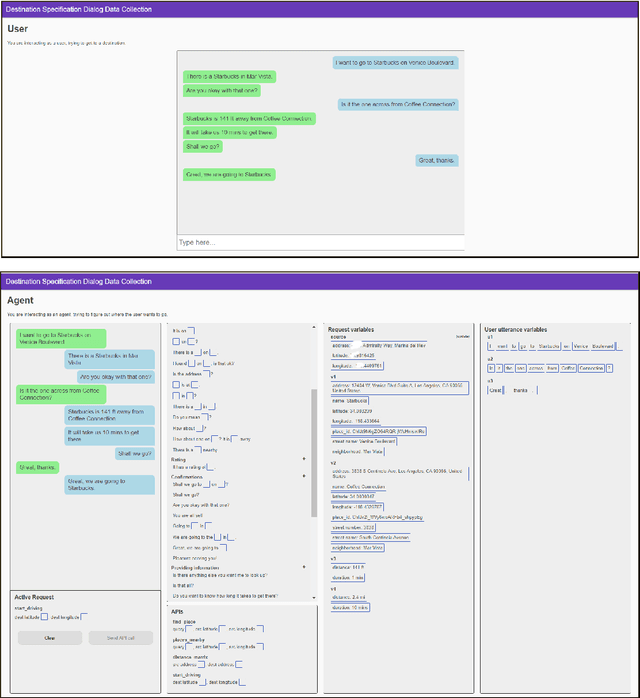


We create a new task-oriented dialog platform (MEEP) where agents are given considerable freedom in terms of utterances and API calls, but are constrained to work within a push-button environment. We include facilities for collecting human-human dialog corpora, and for training automatic agents in an end-to-end fashion. We demonstrate MEEP with a dialog assistant that lets users specify trip destinations.
Solving Historical Dictionary Codes with a Neural Language Model
Oct 09, 2020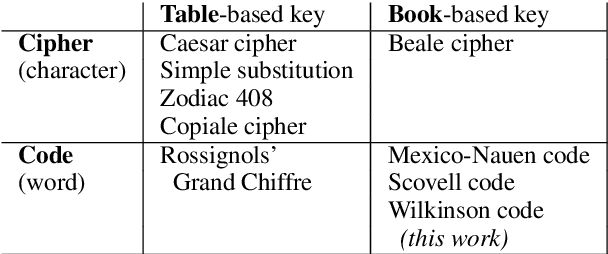



We solve difficult word-based substitution codes by constructing a decoding lattice and searching that lattice with a neural language model. We apply our method to a set of enciphered letters exchanged between US Army General James Wilkinson and agents of the Spanish Crown in the late 1700s and early 1800s, obtained from the US Library of Congress. We are able to decipher 75.1% of the cipher-word tokens correctly.
Learning to Pronounce Chinese Without a Pronunciation Dictionary
Oct 09, 2020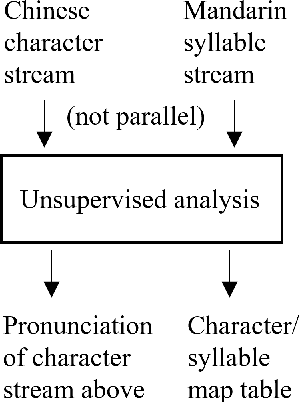
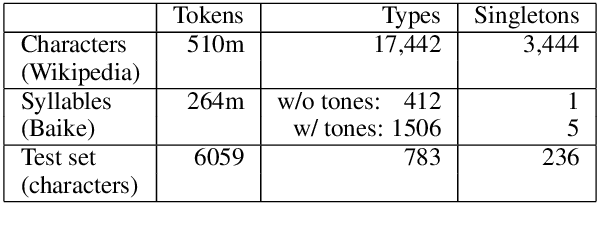

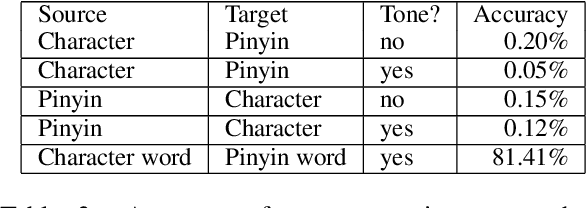
We demonstrate a program that learns to pronounce Chinese text in Mandarin, without a pronunciation dictionary. From non-parallel streams of Chinese characters and Chinese pinyin syllables, it establishes a many-to-many mapping between characters and pronunciations. Using unsupervised methods, the program effectively deciphers writing into speech. Its token-level character-to-syllable accuracy is 89%, which significantly exceeds the 22% accuracy of prior work.