 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEEP: An Open-Source Platform for Human-Human Dialog Collection and End-to-End Agent Training
Oct 09, 2020
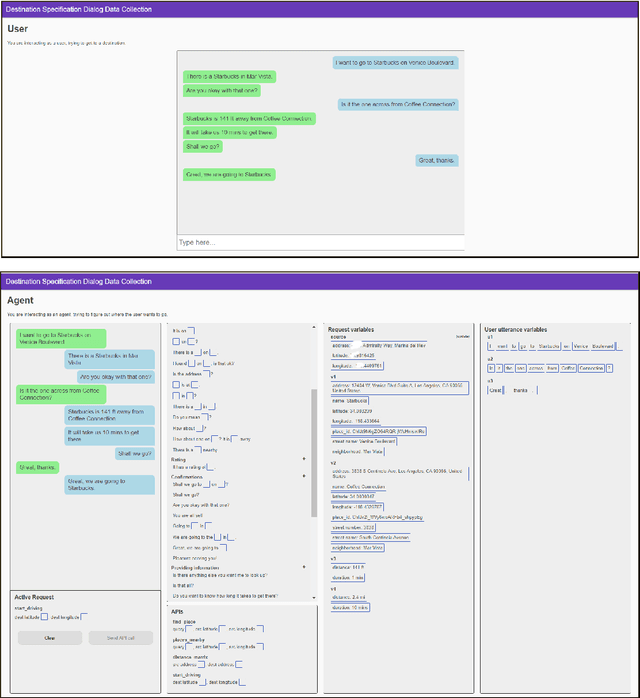


We create a new task-oriented dialog platform (MEEP) where agents are given considerable freedom in terms of utterances and API calls, but are constrained to work within a push-button environment. We include facilities for collecting human-human dialog corpora, and for training automatic agents in an end-to-end fashion. We demonstrate MEEP with a dialog assistant that lets users specify trip destinations.
Data Selection with Cluster-Based Language Difference Models and Cynical Selection
Apr 09, 2019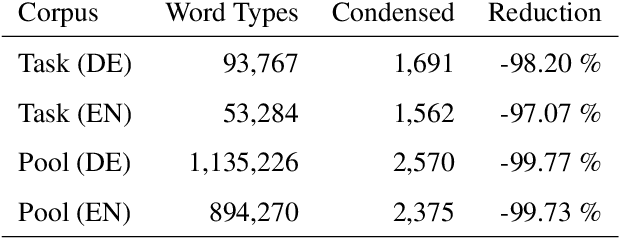
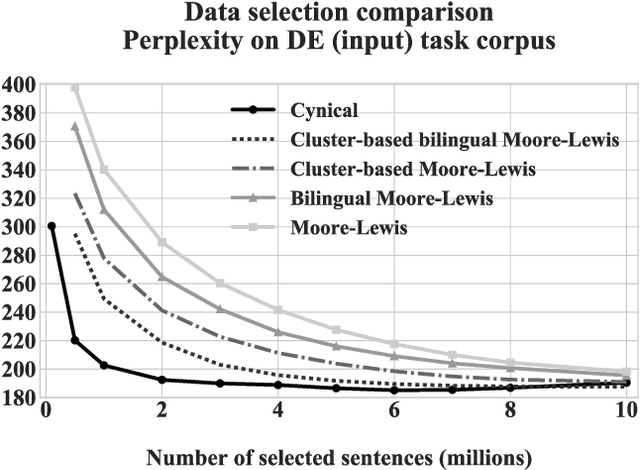
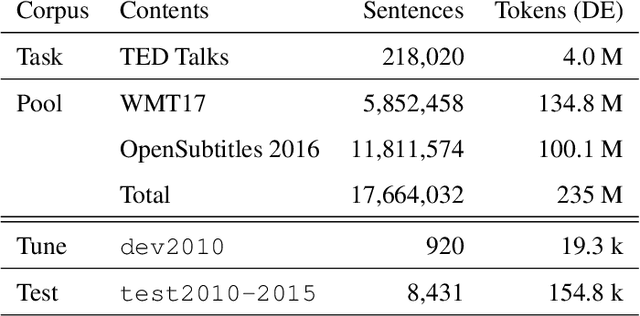
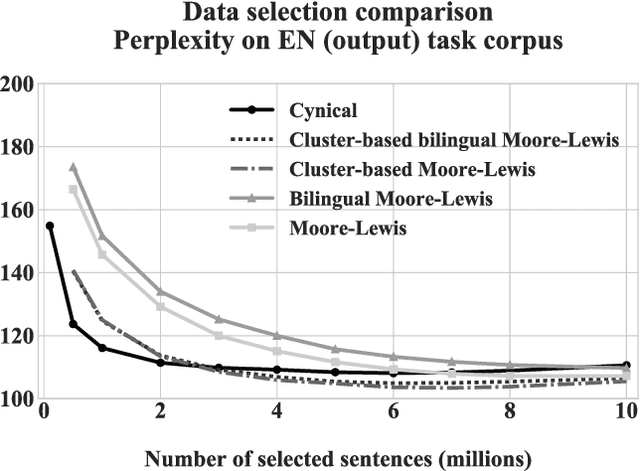
We present and apply two methods for addressing the problem of selecting relevant training data out of a general pool for use in tasks such as machine translation. Building on existing work on class-based language difference models, we first introduce a cluster-based method that uses Brown clusters to condense the vocabulary of the corpora. Secondly, we implement the cynical data selection method, which incrementally constructs a training corpus to efficiently model the task corpus. Both the cluster-based and the cynical data selection approaches are used for the first time within a machine translation system, and we perform a head-to-head comparison. Our intrinsic evaluations show that both new methods outperform the standard Moore-Lewis approach (cross-entropy difference), in terms of better perplexity and OOV rates on in-domain data. The cynical approach converges much quicker, covering nearly all of the in-domain vocabulary with 84% less data than the other methods. Furthermore, the new approaches can be used to select machine translation training data for training better systems. Our results confirm that class-based selection using Brown clusters is a viable alternative to POS-based class-based methods, and removes the reliance on a part-of-speech tagger. Additionally, we are able to validate the recently proposed cynical data selection method, showing that its performance in SMT models surpasses that of traditional cross-entropy difference methods and more closely matches the sentence length of the task corpus.
* 9 pages, 7 figures, IWSLT 2017
Cynical Selection of Language Model Training Data
Sep 07, 2017The Moore-Lewis method of "intelligent selection of language model training data" is very effective, cheap, efficient... and also has structural problems. (1) The method defines relevance by playing language models trained on the in-domain and the out-of-domain (or data pool) corpora against each other. This powerful idea-- which we set out to preserve-- treats the two corpora as the opposing ends of a single spectrum. This lack of nuance does not allow for the two corpora to be very similar. In the extreme case where the come from the same distribution, all of the sentences have a Moore-Lewis score of zero, so there is no resulting ranking. (2) The selected sentences are not guaranteed to be able to model the in-domain data, nor to even cover the in-domain data. They are simply well-liked by the in-domain model; this is necessary, but not sufficient. (3) There is no way to tell what is the optimal number of sentences to select, short of picking various thresholds and building the systems. We present a greedy, lazy, approximate, and generally efficient information-theoretic method of accomplishing the same goal using only vocabulary counts. The method has the following properties: (1) Is responsive to the extent to which two corpora differ. (2) Quickly reaches near-optimal vocabulary coverage. (3) Takes into account what has already been selected. (4) Does not involve defining any kind of domain, nor any kind of classifier. (6) Knows approximately when to stop. This method can be used as an inherently-meaningful measure of similarity, as it measures the bits of information to be gained by adding one text to another.