 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety with Agency: Human-Centered Safety Filter with Application to AI-Assisted Motorsports
Apr 16, 2025We propose a human-centered safety filter (HCSF) for shared autonomy that significantly enhances system safety without compromising human agency. Our HCSF is built on a neural safety value function, which we first learn scalably through black-box interactions and then use at deployment to enforce a novel quality control barrier function (Q-CBF) safety constraint. Since this Q-CBF safety filter does not require any knowledge of the system dynamics for both synthesis and runtime safety monitoring and intervention, our method applies readily to complex, black-box shared autonomy systems. Notably, our HCSF's CBF-based interventions modify the human's actions minimally and smoothly, avoiding the abrupt, last-moment corrections delivered by many conventional safety filters. We validate our approach in a comprehensive in-person user study using Assetto Corsa-a high-fidelity car racing simulator with black-box dynamics-to assess robustness in "driving on the edge" scenarios. We compare both trajectory data and drivers' perceptions of our HCSF assistance against unassisted driving and a conventional safety filter. Experimental results show that 1) compared to having no assistance, our HCSF improves both safety and user satisfaction without compromising human agency or comfort, and 2) relative to a conventional safety filter, our proposed HCSF boosts human agency, comfort, and satisfaction while maintaining robustness.
The Beatbots: A Musician-Informed Multi-Robot Percussion Quartet
Feb 03, 2025Artistic creation is often seen as a uniquely human endeavor, yet robots bring distinct advantages to music-making, such as precise tempo control, unpredictable rhythmic complexities, and the ability to coordinate intricate human and robot performances. While many robotic music systems aim to mimic human musicianship, our work emphasizes the unique strengths of robots, resulting in a novel multi-robot performance instrument called the Beatbots, capable of producing music that is challenging for humans to replicate using current methods. The Beatbots were designed using an ``informed prototyping'' process, incorporating feedback from three musicians throughout development. We evaluated the Beatbots through a live public performance, surveying participants (N=28) to understand how they perceived and interacted with the robotic performance. Results show that participants valued the playfulness of the experience, the aesthetics of the robot system, and the unconventional robot-generated music. Expert musicians and non-expert roboticists demonstrated especially positive mindset shifts during the performance, although participants across all demographics had favorable responses. We propose design principles to guide the development of future robotic music systems and identify key robotic music affordances that our musician consultants considered particularly important for robotic music performance.
Think Deep and Fast: Learning Neural Nonlinear Opinion Dynamics from Inverse Dynamic Games for Split-Second Interactions
Jun 14, 2024



Non-cooperative interactions commonly occur in multi-agent scenarios such as car racing, where an ego vehicle can choose to overtake the rival, or stay behind it until a safe overtaking "corridor" opens. While an expert human can do well at making such time-sensitive decisions, the development of safe and efficient game-theoretic trajectory planners capable of rapidly reasoning discrete options is yet to be fully addressed. The recently developed nonlinear opinion dynamics (NOD) show promise in enabling fast opinion formation and avoiding safety-critical deadlocks. However, it remains an open challenge to determine the model parameters of NOD automatically and adaptively, accounting for the ever-changing environment of interaction. In this work, we propose for the first time a learning-based, game-theoretic approach to synthesize a Neural NOD model from expert demonstrations, given as a dataset containing (possibly incomplete) state and action trajectories of interacting agents. The learned NOD can be used by existing dynamic game solvers to plan decisively while accounting for the predicted change of other agents' intents, thus enabling situational awareness in planning. We demonstrate Neural NOD's ability to make fast and robust decisions in a simulated autonomous racing example, leading to tangible improvements in safety and overtaking performance over state-of-the-art data-driven game-theoretic planning methods.
Excitable crawling
May 31, 2024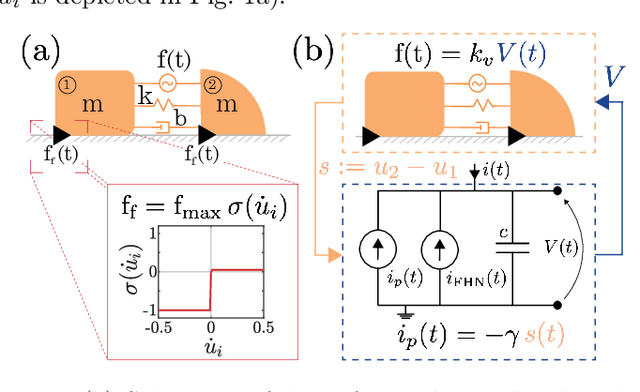
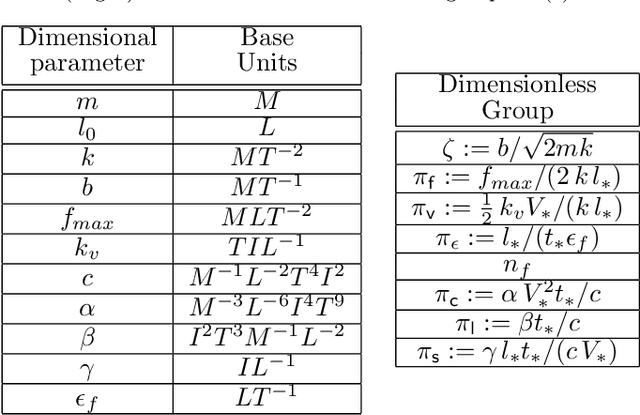
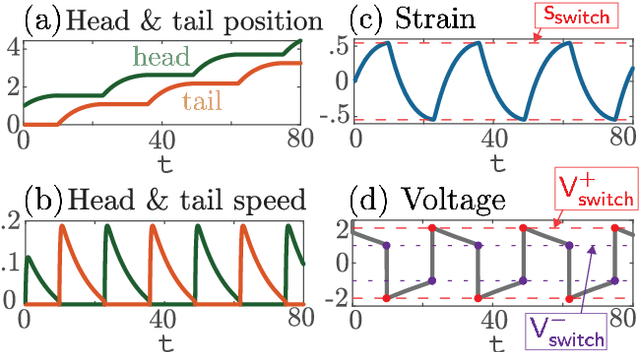
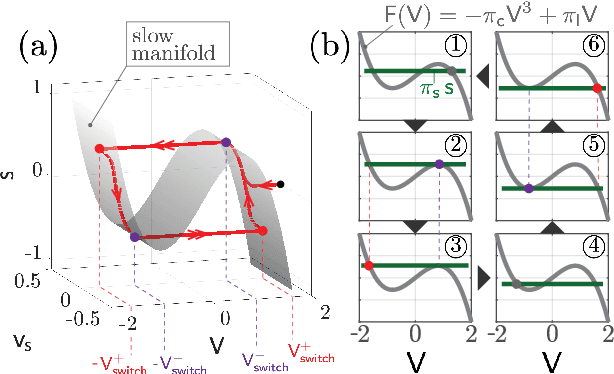
We propose and analyze the suitability of a spiking controller to engineer the locomotion of a soft robotic crawler. Inspired by the FitzHugh-Nagumo model of neural excitability, we design a bistable controller with an electrical flipflop circuit representation capable of generating spikes on-demand when coupled to the passive crawler mechanics. A proprioceptive sensory signal from the crawler mechanics turns bistability of the controller into a rhythmic spiking. The output voltage, in turn, activates the crawler's actuators to generate movement through peristaltic waves. We show through geometric analysis that this control strategy achieves endogenous crawling. The electro-mechanical sensorimotor interconnection provides embodied negative feedback regulation, facilitating locomotion. Dimensional analysis provides insights on the characteristic scales in the crawler's mechanical and electrical dynamics, and how they determine the crawling gait. Adaptive control of the electrical scales to optimally match the mechanical scales can be envisioned to achieve further efficiency, as in homeostatic regulation of neuronal circuits. Our approach can scale up to multiple sensorimotor loops inspired by biological central pattern generators.
Threshold Decision-Making Dynamics Adaptive to Physical Constraints and Changing Environment
Dec 11, 2023We propose a threshold decision-making framework for controlling the physical dynamics of an agent switching between two spatial tasks. Our framework couples a nonlinear opinion dynamics model that represents the evolution of an agent's preference for a particular task with the physical dynamics of the agent. We prove the bifurcation that governs the behavior of the coupled dynamics. We show by means of the bifurcation behavior how the coupled dynamics are adaptive to the physical constraints of the agent. We also show how the bifurcation can be modulated to allow the agent to switch tasks based on thresholds adaptive to environmental conditions. We illustrate the benefits of the approach through a decentralized multi-robot task allocation application for trash collection.
Learning to predict 3D rotational dynamics from images of a rigid body with unknown mass distribution
Aug 24, 2023In many real-world settings, image observations of freely rotating 3D rigid bodies, may be available when low-dimensional measurements are not. However, the high-dimensionality of image data precludes the use of classical estimation techniques to learn the dynamics. The usefulness of standard deep learning methods is also limited because an image of a rigid body reveals nothing about the distribution of mass inside the body, which, together with initial angular velocity, is what determines how the body will rotate. We present a physics-informed neural network model to estimate and predict 3D rotational dynamics from image sequences. We achieve this using a multi-stage prediction pipeline that maps individual images to a latent representation homeomorphic to $\mathbf{SO}(3)$, computes angular velocities from latent pairs, and predicts future latent states using the Hamiltonian equations of motion. We demonstrate the efficacy of our approach on new rotating rigid-body datasets of sequences of synthetic images of rotating objects, including cubes, prisms and satellites, with unknown uniform and non-uniform mass distributions.
Emergent Coordination through Game-Induced Nonlinear Opinion Dynamics
Apr 05, 2023



We present a multi-agent decision-making framework for the emergent coordination of autonomous agents whose intents are initially undecided. Dynamic non-cooperative games have been used to encode multi-agent interaction, but ambiguity arising from factors such as goal preference or the presence of multiple equilibria may lead to coordination issues, ranging from the "freezing robot" problem to unsafe behavior in safety-critical events. The recently developed nonlinear opinion dynamics (NOD) provide guarantees for breaking deadlocks. However, choosing the appropriate model parameters automatically in general multi-agent settings remains a challenge. In this paper, we first propose a novel and principled procedure for synthesizing NOD based on the value functions of dynamic games conditioned on agents' intents. In particular, we provide for the two-player two-option case precise stability conditions for equilibria of the game-induced NOD based on the mismatch between agents' opinions and their game values. We then propose an optimization-based trajectory optimization algorithm that computes agents' policies guided by the evolution of opinions. The efficacy of our method is illustrated with a simulated toll station coordination example.
Opinion-Driven Robot Navigation: Human-Robot Corridor Passing
Oct 04, 2022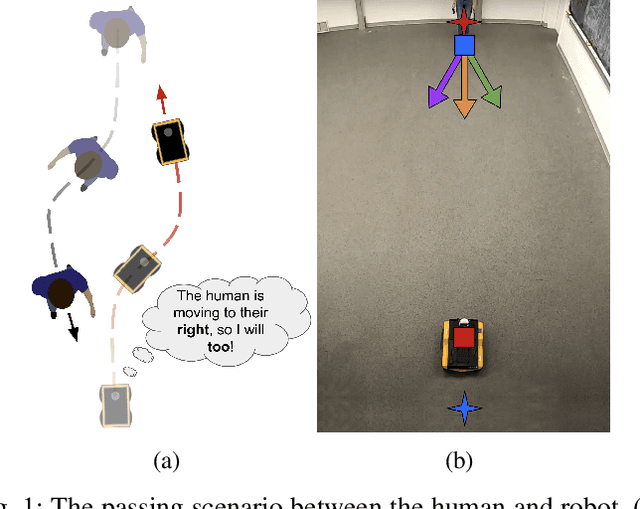
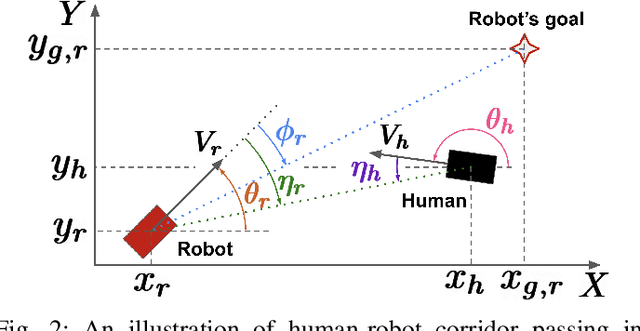
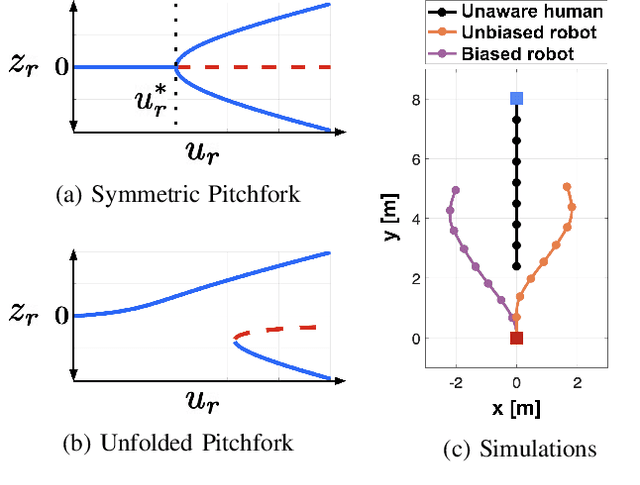
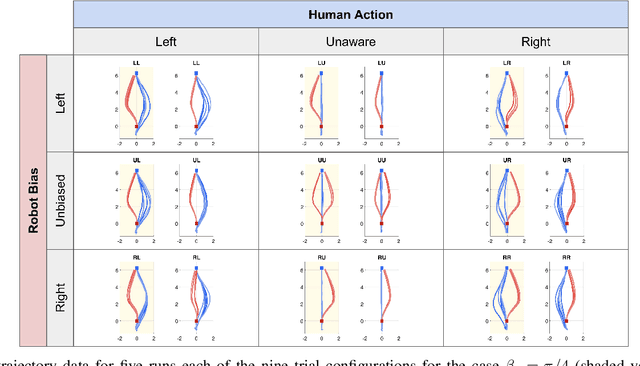
We propose, analyze, and experimentally verify a new approach for robot social navigation in human-robot corridor passing that is driven by nonlinear opinion dynamics. The robot forms an opinion over time in response to its observations, and its opinion drives its motion control. The algorithm inherits a key feature of the opinion dynamics: deadlock, also known as the "freezing robot" problem, is guaranteed to be broken even if the robot has no bias or evidence for whether it is better off passing on the right or the left. The robot can also overcome a bias that is in conflict with the passage choice the human makes. The approach enables rapid and reliable opinion formation, which makes for rapid and reliable navigation. We verify our analytical results on deadlock breaking and rapid and reliable passage with human-robot experiments. We further verify through experiments that a single design parameter can tune the trade-off between efficiency and reliability in human-robot corridor passing. The new approach has the additional advantage that it does not rely on a predictive model of human behavior.
Decentralized Learning With Limited Communications for Multi-robot Coverage of Unknown Spatial Fields
Aug 03, 2022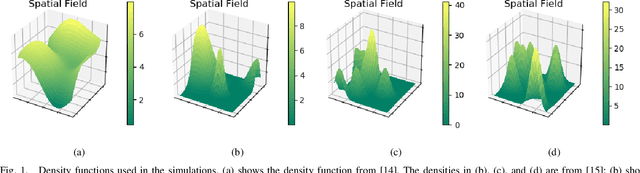

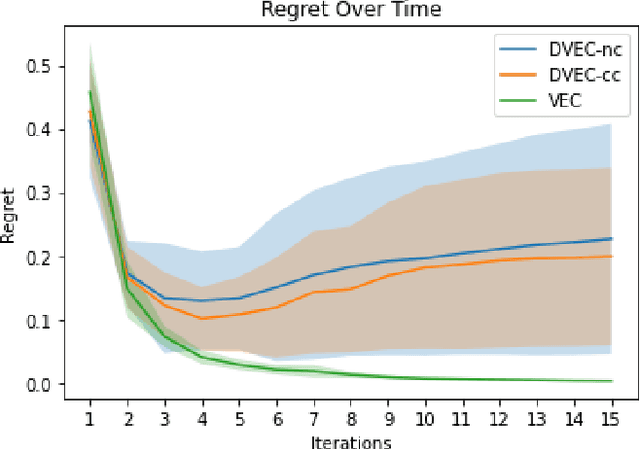
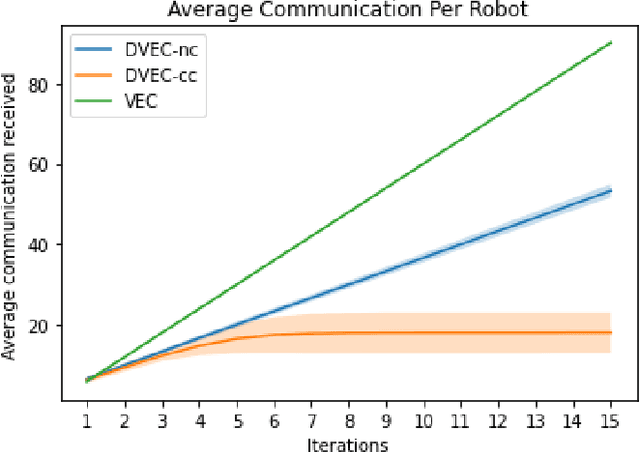
This paper presents an algorithm for a team of mobile robots to simultaneously learn a spatial field over a domain and spatially distribute themselves to optimally cover it. Drawing from previous approaches that estimate the spatial field through a centralized Gaussian process, this work leverages the spatial structure of the coverage problem and presents a decentralized strategy where samples are aggregated locally by establishing communications through the boundaries of a Voronoi partition. We present an algorithm whereby each robot runs a local Gaussian process calculated from its own measurements and those provided by its Voronoi neighbors, which are incorporated into the individual robot's Gaussian process only if they provide sufficiently novel information. The performance of the algorithm is evaluated in simulation and compared with centralized approaches.
One More Step Towards Reality: Cooperative Bandits with Imperfect Communication
Nov 24, 2021


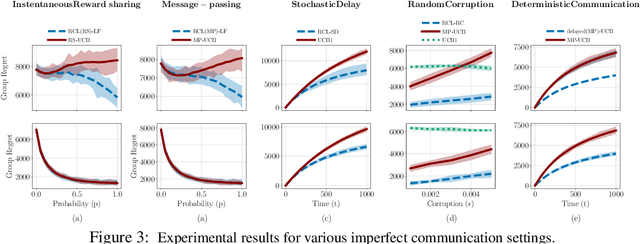
The cooperative bandit problem is increasingly becoming relevant due to its applications in large-scale decision-making. However, most research for this problem focuses exclusively on the setting with perfect communication, whereas in most real-world distributed settings, communication is often over stochastic networks, with arbitrary corruptions and delays. In this paper, we study cooperative bandit learning under three typical real-world communication scenarios, namely, (a) message-passing over stochastic time-varying networks, (b) instantaneous reward-sharing over a network with random delays, and (c) message-passing with adversarially corrupted rewards, including byzantine communication. For each of these environments, we propose decentralized algorithms that achieve competitive performance, along with near-optimal guarantees on the incurred group regret as well. Furthermore, in the setting with perfect communication, we present an improved delayed-update algorithm that outperforms the existing state-of-the-art on various network topologies. Finally, we present tight network-dependent minimax lower bounds on the group regret. Our proposed algorithms are straightforward to implement and obtain competitive empirical performance.