 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Power Vision Transformer Accelerator with Hardware-Aware Pruning and Optimized Dataflow
Oct 16, 2025Current transformer accelerators primarily focus on optimizing self-attention due to its quadratic complexity. However, this focus is less relevant for vision transformers with short token lengths, where the Feed-Forward Network (FFN) tends to be the dominant computational bottleneck. This paper presents a low power Vision Transformer accelerator, optimized through algorithm-hardware co-design. The model complexity is reduced using hardware-friendly dynamic token pruning without introducing complex mechanisms. Sparsity is further improved by replacing GELU with ReLU activations and employing dynamic FFN2 pruning, achieving a 61.5\% reduction in operations and a 59.3\% reduction in FFN2 weights, with an accuracy loss of less than 2\%. The hardware adopts a row-wise dataflow with output-oriented data access to eliminate data transposition, and supports dynamic operations with minimal area overhead. Implemented in TSMC's 28nm CMOS technology, our design occupies 496.4K gates and includes a 232KB SRAM buffer, achieving a peak throughput of 1024 GOPS at 1GHz, with an energy efficiency of 2.31 TOPS/W and an area efficiency of 858.61 GOPS/mm2.
A 71.2-$μ$W Speech Recognition Accelerator with Recurrent Spiking Neural Network
Mar 27, 2025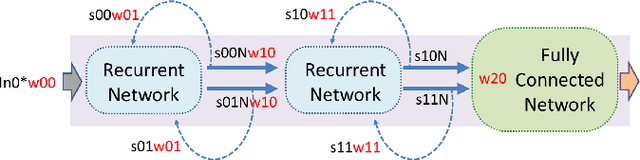
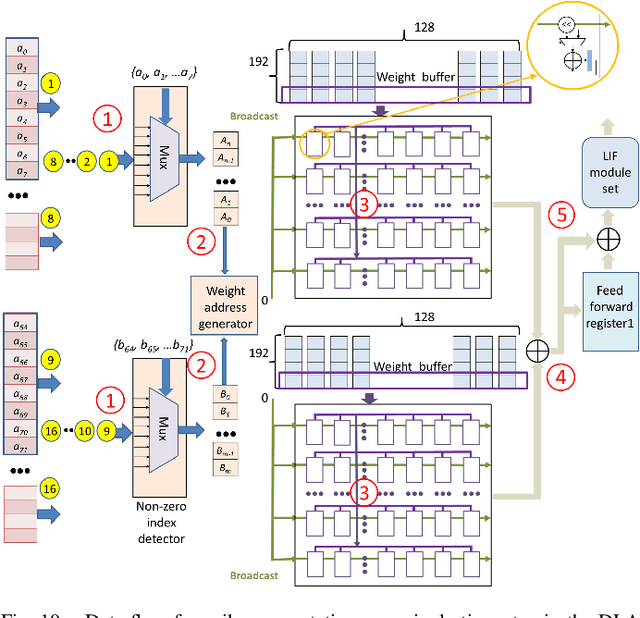
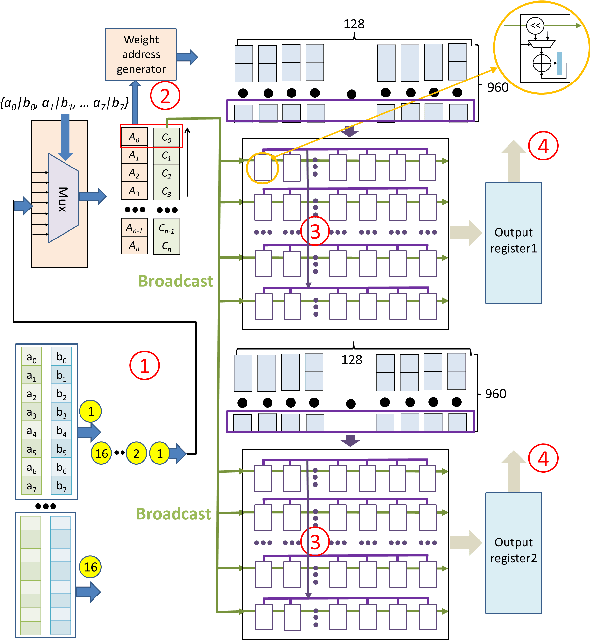
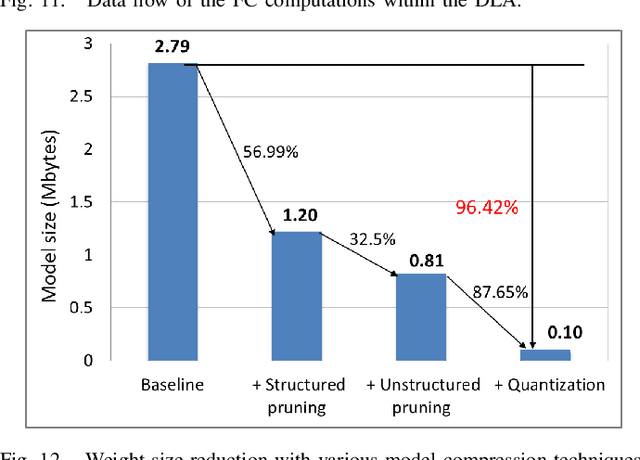
This paper introduces a 71.2-$\mu$W speech recognition accelerator designed for edge devices' real-time applications, emphasizing an ultra low power design. Achieved through algorithm and hardware co-optimizations, we propose a compact recurrent spiking neural network with two recurrent layers, one fully connected layer, and a low time step (1 or 2). The 2.79-MB model undergoes pruning and 4-bit fixed-point quantization, shrinking it by 96.42\% to 0.1 MB. On the hardware front, we take advantage of \textit{mixed-level pruning}, \textit{zero-skipping} and \textit{merged spike} techniques, reducing complexity by 90.49\% to 13.86 MMAC/S. The \textit{parallel time-step execution} addresses inter-time-step data dependencies and enables weight buffer power savings through weight sharing. Capitalizing on the sparse spike activity, an input broadcasting scheme eliminates zero computations, further saving power. Implemented on the TSMC 28-nm process, the design operates in real time at 100 kHz, consuming 71.2 $\mu$W, surpassing state-of-the-art designs. At 500 MHz, it has 28.41 TOPS/W and 1903.11 GOPS/mm$^2$ in energy and area efficiency, respectively.
A Low-Power Streaming Speech Enhancement Accelerator For Edge Devices
Mar 27, 2025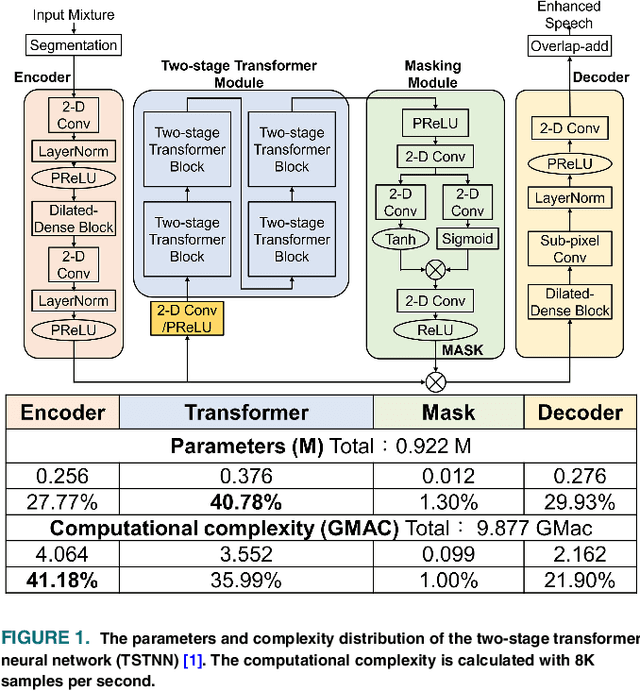

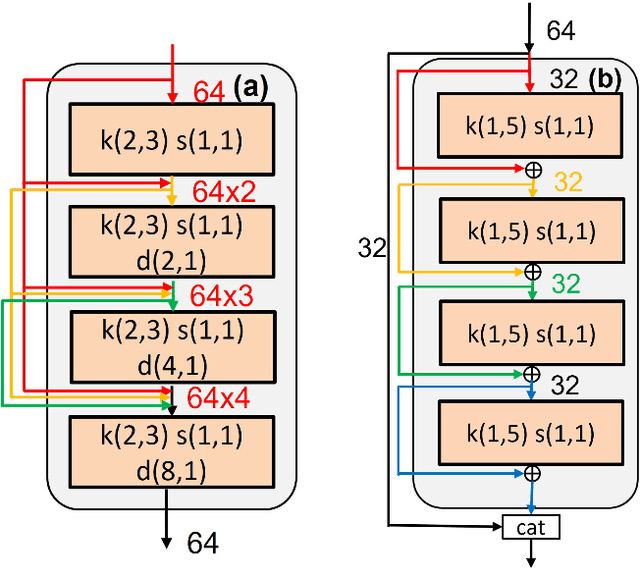
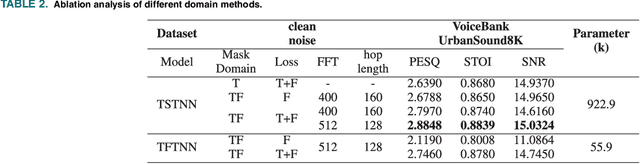
Transformer-based speech enhancement models yield impressive results. However, their heterogeneous and complex structure restricts model compression potential, resulting in greater complexity and reduced hardware efficiency. Additionally, these models are not tailored for streaming and low-power applications. Addressing these challenges, this paper proposes a low-power streaming speech enhancement accelerator through model and hardware optimization. The proposed high performance model is optimized for hardware execution with the co-design of model compression and target application, which reduces 93.9\% of model size by the proposed domain-aware and streaming-aware pruning techniques. The required latency is further reduced with batch normalization-based transformers. Additionally, we employed softmax-free attention, complemented by an extra batch normalization, facilitating simpler hardware design. The tailored hardware accommodates these diverse computing patterns by breaking them down into element-wise multiplication and accumulation (MAC). This is achieved through a 1-D processing array, utilizing configurable SRAM addressing, thereby minimizing hardware complexities and simplifying zero skipping. Using the TSMC 40nm CMOS process, the final implementation requires merely 207.8K gates and 53.75KB SRAM. It consumes only 8.08 mW for real-time inference at a 62.5MHz frequency.
ESSR: An 8K@30FPS Super-Resolution Accelerator With Edge Selective Network
Mar 26, 2025
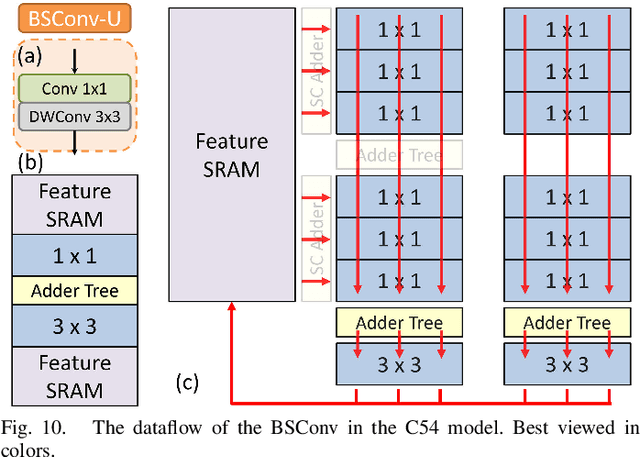
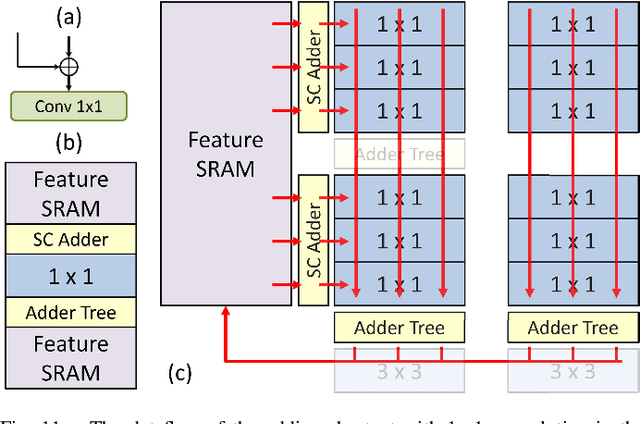
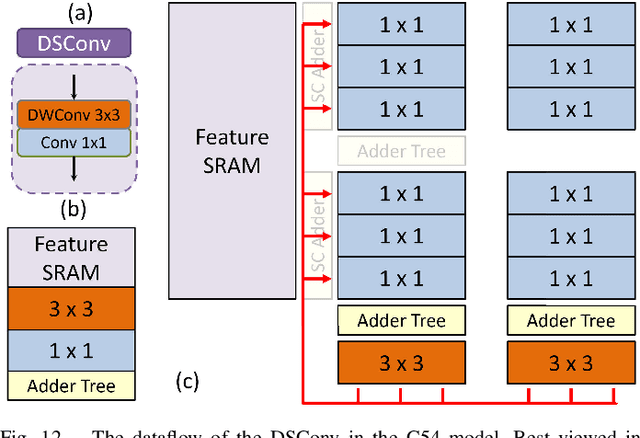
Deep learning-based super-resolution (SR) is challenging to implement in resource-constrained edge devices for resolutions beyond full HD due to its high computational complexity and memory bandwidth requirements. This paper introduces an 8K@30FPS SR accelerator with edge-selective dynamic input processing. Dynamic processing chooses the appropriate subnets for different patches based on simple input edge criteria, achieving a 50\% MAC reduction with only a 0.1dB PSNR decrease. The quality of reconstruction images is guaranteed and maximized its potential with \textit{resource adaptive model switching} even under resource constraints. In conjunction with hardware-specific refinements, the model size is reduced by 84\% to 51K, but with a decrease of less than 0.6dB PSNR. Additionally, to support dynamic processing with high utilization, this design incorporates a \textit{configurable group of layer mapping} that synergizes with the \textit{structure-friendly fusion block}, resulting in 77\% hardware utilization and up to 79\% reduction in feature SRAM access. The implementation, using the TSMC 28nm process, can achieve 8K@30FPS throughput at 800MHz with a gate count of 2749K, 0.2075W power consumption, and 4797Mpixels/J energy efficiency, exceeding previous work.
An Efficient Data Reuse with Tile-Based Adaptive Stationary for Transformer Accelerators
Mar 25, 2025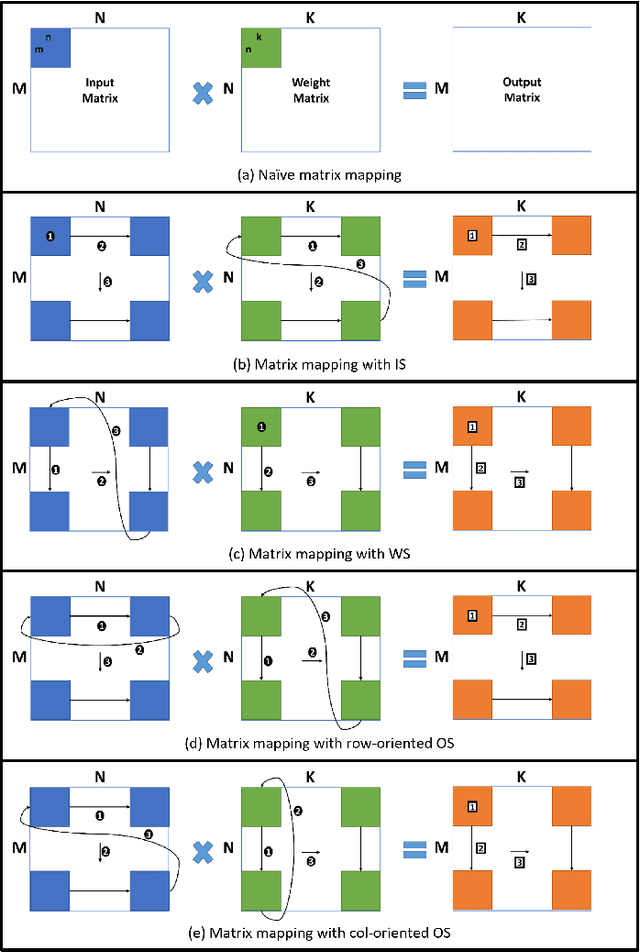
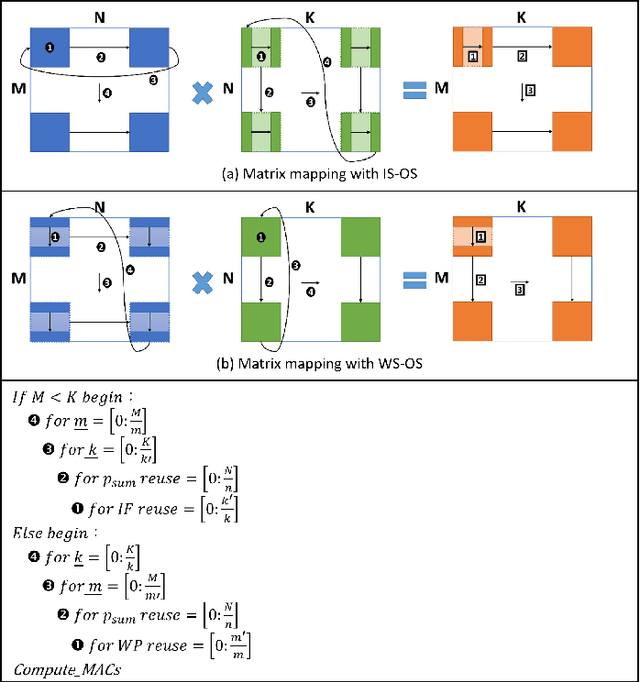
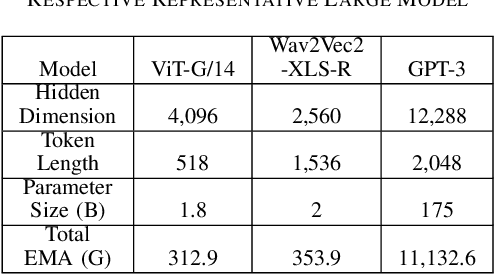
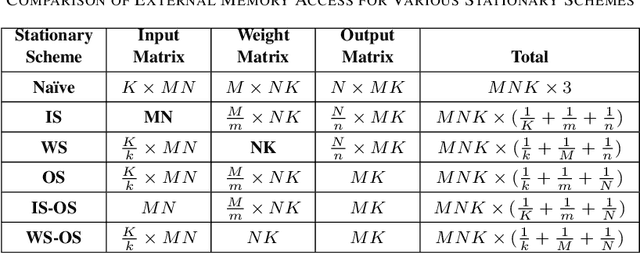
Transformer-based models have become the \textit{de facto} backbone across many fields, such as computer vision and natural language processing. However, as these models scale in size, external memory access (EMA) for weight and activations becomes a critical bottleneck due to its significantly higher energy consumption compared to internal computations. While most prior work has focused on optimizing the self-attention mechanism, little attention has been given to optimizing data transfer during linear projections, where EMA costs are equally important. In this paper, we propose the Tile-based Adaptive Stationary (TAS) scheme that selects the input or weight stationary in a tile granularity, based on the input sequence length. Our experimental results demonstrate that TAS can significantly reduce EMA by more than 97\% compared to traditional stationary schemes, while being compatible with various attention optimization techniques and hardware accelerators.
A 1.6-mW Sparse Deep Learning Accelerator for Speech Separation
Dec 15, 2023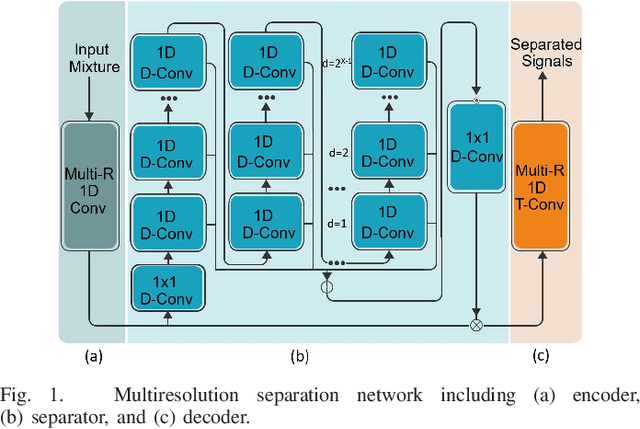
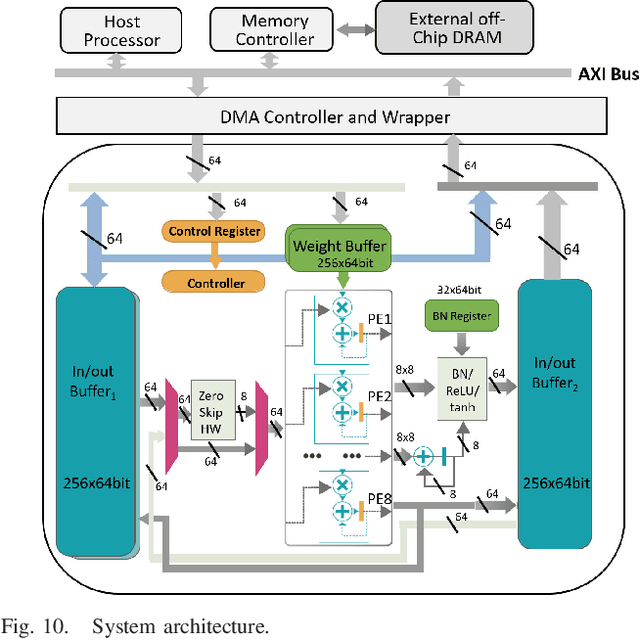
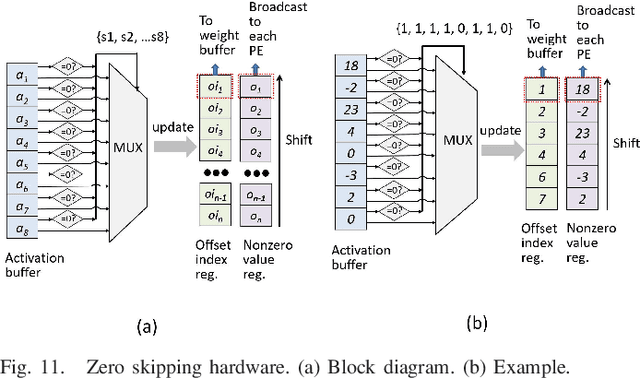
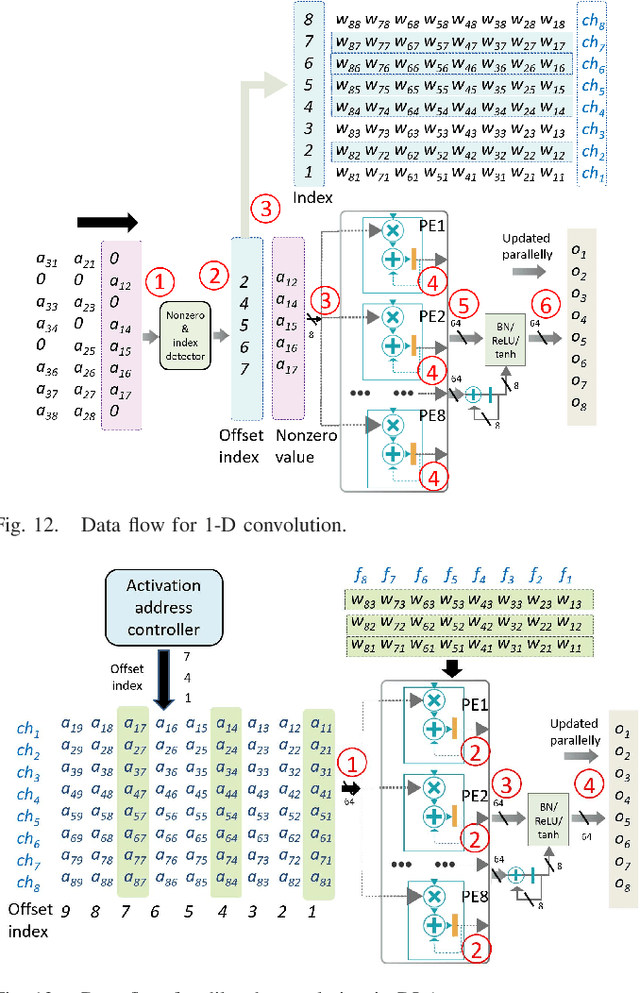
Low power deep learning accelerators on the speech processing enable real-time applications on edge devices. However, most of the existing accelerators suffer from high power consumption and focus on image applications only. This paper presents a low power accelerator for speech separation through algorithm and hardware optimizations. At the algorithm level, the model is compressed with structured sensitivity as well as unstructured pruning, and further quantized to the shifted 8-bit floating-point format instead of the 32-bit floating-point format. The computations with the zero kernel and zero activation values are skipped by decomposition of the dilated and transposed convolutions. At the hardware level, the compressed model is then supported by an architecture with eight independent multipliers and accumulators (MACs) with a simple zero-skipping hardware to take advantage of the activation sparsity and low power processing. The proposed approach reduces the model size by 95.44\% and computation complexity by 93.88\%. The final implementation with the TSMC 40 $nm$ process can achieve real-time speech separation and consumes 1.6 mW power when operated at 150 MHz. The normalized energy efficiency and area efficiency are 2.344 TOPS/W and 14.42 GOPS/mm$^2$, respectively.
IQNet: Image Quality Assessment Guided Just Noticeable Difference Prefiltering For Versatile Video Coding
Dec 15, 2023



Image prefiltering with just noticeable distortion (JND) improves coding efficiency in a visual lossless way by filtering the perceptually redundant information prior to compression. However, real JND cannot be well modeled with inaccurate masking equations in traditional approaches or image-level subject tests in deep learning approaches. Thus, this paper proposes a fine-grained JND prefiltering dataset guided by image quality assessment for accurate block-level JND modeling. The dataset is constructed from decoded images to include coding effects and is also perceptually enhanced with block overlap and edge preservation. Furthermore, based on this dataset, we propose a lightweight JND prefiltering network, IQNet, which can be applied directly to different quantization cases with the same model and only needs 3K parameters. The experimental results show that the proposed approach to Versatile Video Coding could yield maximum/average bitrate savings of 41\%/15\% and 53\%/19\% for all-intra and low-delay P configurations, respectively, with negligible subjective quality loss. Our method demonstrates higher perceptual quality and a model size that is an order of magnitude smaller than previous deep learning methods.
ASC: Adaptive Scale Feature Map Compression for Deep Neural Network
Dec 13, 2023



Deep-learning accelerators are increasingly in demand; however, their performance is constrained by the size of the feature map, leading to high bandwidth requirements and large buffer sizes. We propose an adaptive scale feature map compression technique leveraging the unique properties of the feature map. This technique adopts independent channel indexing given the weak channel correlation and utilizes a cubical-like block shape to benefit from strong local correlations. The method further optimizes compression using a switchable endpoint mode and adaptive scale interpolation to handle unimodal data distributions, both with and without outliers. This results in 4$\times$ and up to 7.69$\times$ compression rates for 16-bit data in constant and variable bitrates, respectively. Our hardware design minimizes area cost by adjusting interpolation scales, which facilitates hardware sharing among interpolation points. Additionally, we introduce a threshold concept for straightforward interpolation, preventing the need for intricate hardware. The TSMC 28nm implementation showcases an equivalent gate count of 6135 for the 8-bit version. Furthermore, the hardware architecture scales effectively, with only a sublinear increase in area cost. Achieving a 32$\times$ throughput increase meets the theoretical bandwidth of DDR5-6400 at just 7.65$\times$ the hardware cost.
ACNPU: A 4.75TOPS/W 1080P@30FPS Super Resolution Accelerator with Decoupled Asymmetric Convolution
Aug 30, 2023



Deep learning-driven superresolution (SR) outperforms traditional techniques but also faces the challenge of high complexity and memory bandwidth. This challenge leads many accelerators to opt for simpler and shallow models like FSRCNN, compromising performance for real-time needs, especially for resource-limited edge devices. This paper proposes an energy-efficient SR accelerator, ACNPU, to tackle this challenge. The ACNPU enhances image quality by 0.34dB with a 27-layer model, but needs 36\% less complexity than FSRCNN, while maintaining a similar model size, with the \textit{decoupled asymmetric convolution and split-bypass structure}. The hardware-friendly 17K-parameter model enables \textit{holistic model fusion} instead of localized layer fusion to remove external DRAM access of intermediate feature maps. The on-chip memory bandwidth is further reduced with the \textit{input stationary flow} and \textit{parallel-layer execution} to reduce power consumption. Hardware is regular and easy to control to support different layers by \textit{processing elements (PEs) clusters with reconfigurable input and uniform data flow}. The implementation in the 40 nm CMOS process consumes 2333 K gate counts and 198KB SRAMs. The ACNPU achieves 31.7 FPS and 124.4 FPS for x2 and x4 scales Full-HD generation, respectively, which attains 4.75 TOPS/W energy efficiency.
Real-Time Wearable Gait Phase Segmentation For Running And Walking
May 10, 2022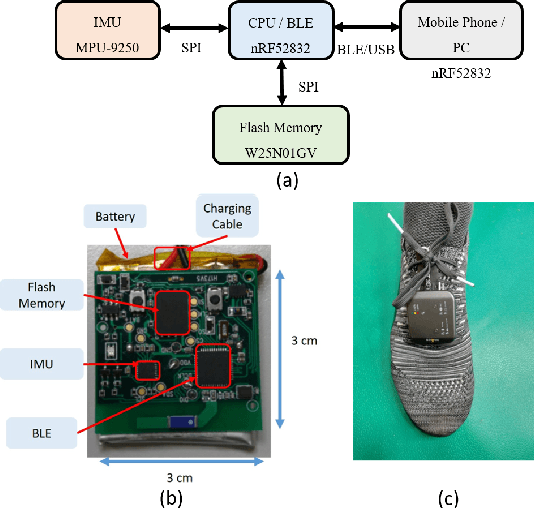
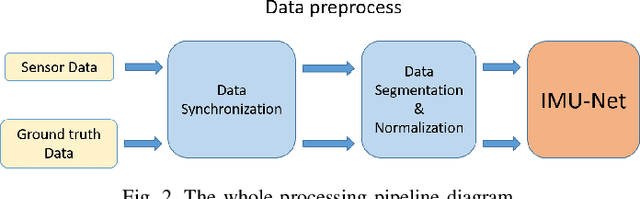
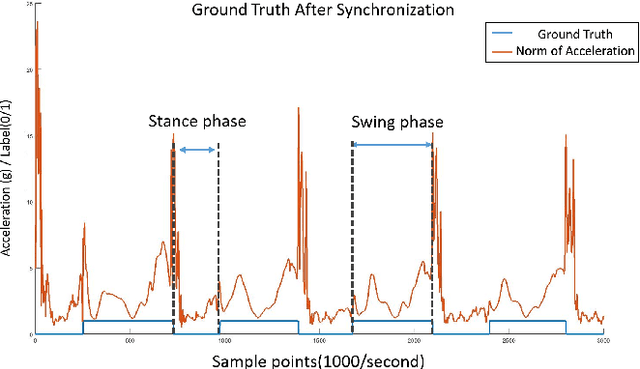
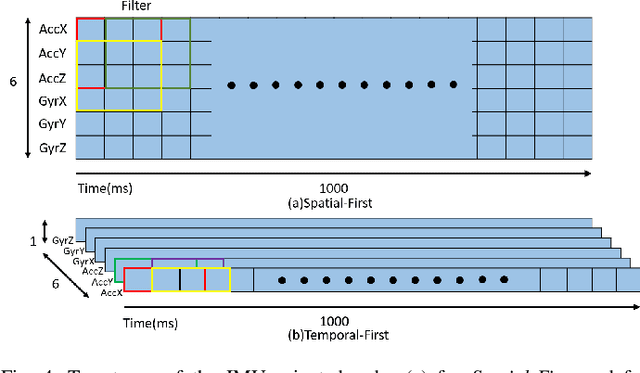
Previous gait phase detection as convolutional neural network (CNN) based classification task requires cumbersome manual setting of time delay or heavy overlapped sliding windows to accurately classify each phase under different test cases, which is not suitable for streaming Inertial-Measurement-Unit (IMU) sensor data and fails to adapt to different scenarios. This paper presents a segmentation based gait phase detection with only a single six-axis IMU sensor, which can easily adapt to both walking and running at various speeds. The proposed segmentation uses CNN with gait phase aware receptive field setting and IMU oriented processing order, which can fit to high sampling rate of IMU up to 1000Hz for high accuracy and low sampling rate down to 20Hz for real time calculation. The proposed model on the 20Hz sampling rate data can achieve average error of 8.86 ms in swing time, 9.12 ms in stance time and 96.44\% accuracy of gait phase detection and 99.97\% accuracy of stride detection. Its real-time implementation on mobile phone only takes 36 ms for 1 second length of sensor data.
* 5 pages, 5 figures, published in IEEE ISCAS 2020