 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient Data Reuse with Tile-Based Adaptive Stationary for Transformer Accelerators
Mar 25, 2025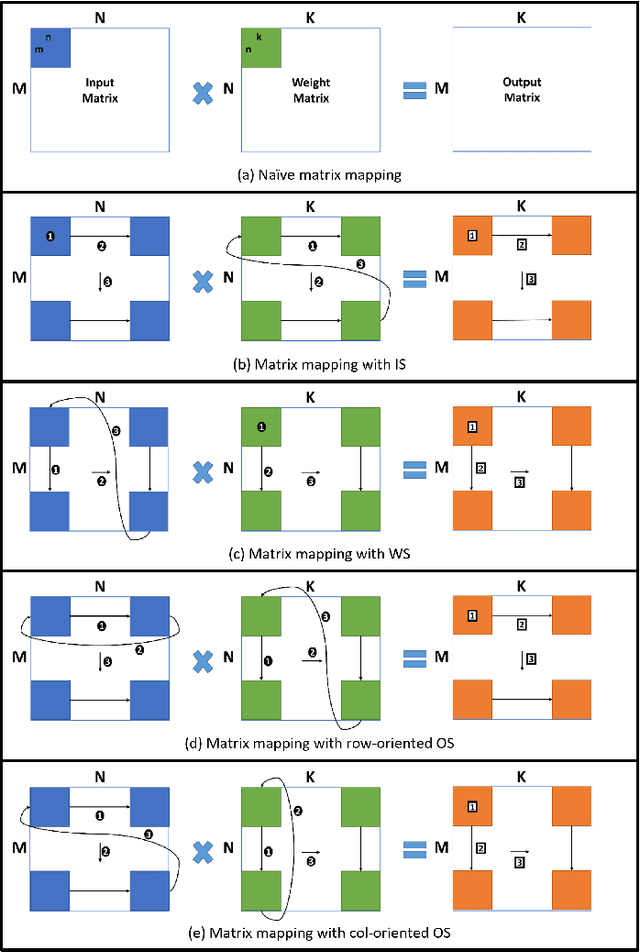
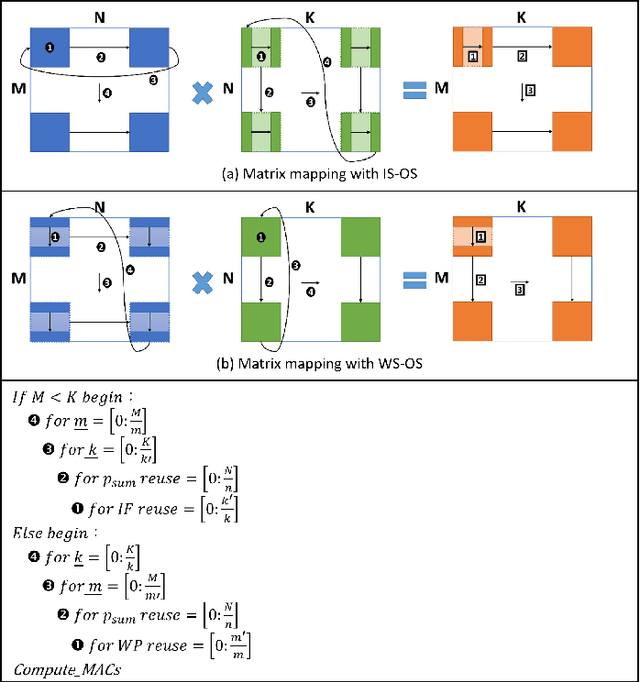
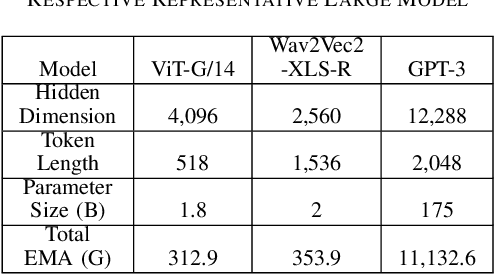
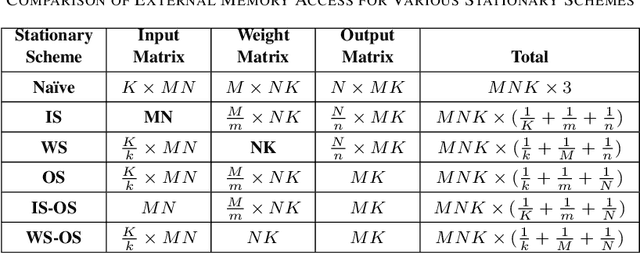
Transformer-based models have become the \textit{de facto} backbone across many fields, such as computer vision and natural language processing. However, as these models scale in size, external memory access (EMA) for weight and activations becomes a critical bottleneck due to its significantly higher energy consumption compared to internal computations. While most prior work has focused on optimizing the self-attention mechanism, little attention has been given to optimizing data transfer during linear projections, where EMA costs are equally important. In this paper, we propose the Tile-based Adaptive Stationary (TAS) scheme that selects the input or weight stationary in a tile granularity, based on the input sequence length. Our experimental results demonstrate that TAS can significantly reduce EMA by more than 97\% compared to traditional stationary schemes, while being compatible with various attention optimization techniques and hardware accelerators.