 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 71.2-$μ$W Speech Recognition Accelerator with Recurrent Spiking Neural Network
Mar 27, 2025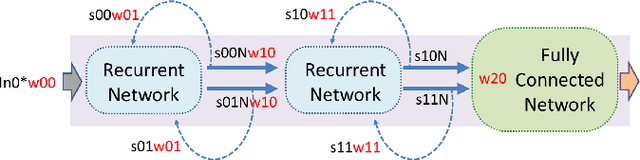
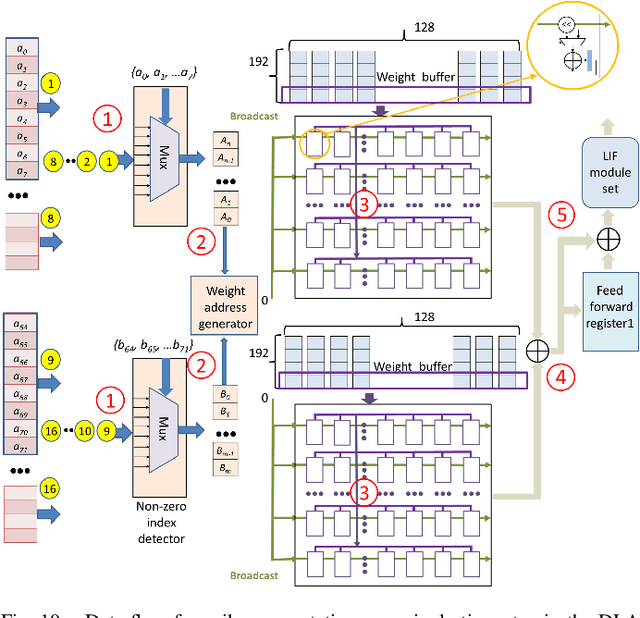
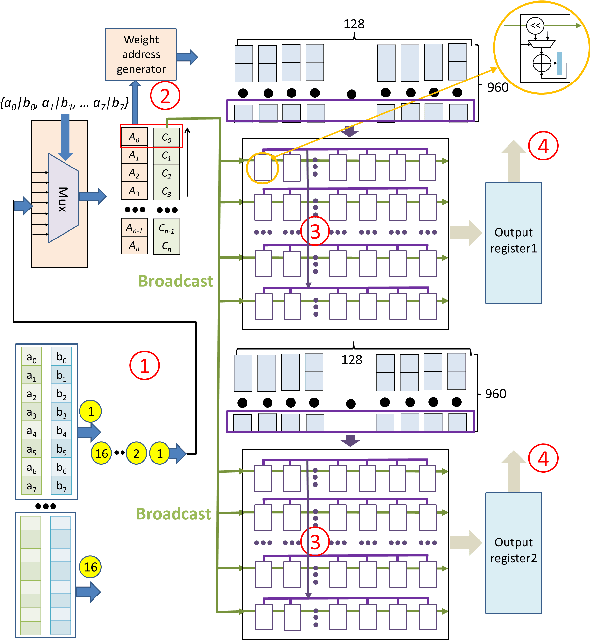
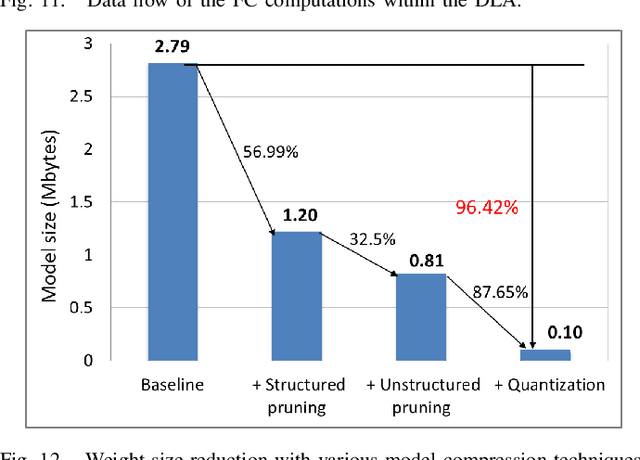
This paper introduces a 71.2-$\mu$W speech recognition accelerator designed for edge devices' real-time applications, emphasizing an ultra low power design. Achieved through algorithm and hardware co-optimizations, we propose a compact recurrent spiking neural network with two recurrent layers, one fully connected layer, and a low time step (1 or 2). The 2.79-MB model undergoes pruning and 4-bit fixed-point quantization, shrinking it by 96.42\% to 0.1 MB. On the hardware front, we take advantage of \textit{mixed-level pruning}, \textit{zero-skipping} and \textit{merged spike} techniques, reducing complexity by 90.49\% to 13.86 MMAC/S. The \textit{parallel time-step execution} addresses inter-time-step data dependencies and enables weight buffer power savings through weight sharing. Capitalizing on the sparse spike activity, an input broadcasting scheme eliminates zero computations, further saving power. Implemented on the TSMC 28-nm process, the design operates in real time at 100 kHz, consuming 71.2 $\mu$W, surpassing state-of-the-art designs. At 500 MHz, it has 28.41 TOPS/W and 1903.11 GOPS/mm$^2$ in energy and area efficiency, respectively.
A 1.6-mW Sparse Deep Learning Accelerator for Speech Separation
Dec 15, 2023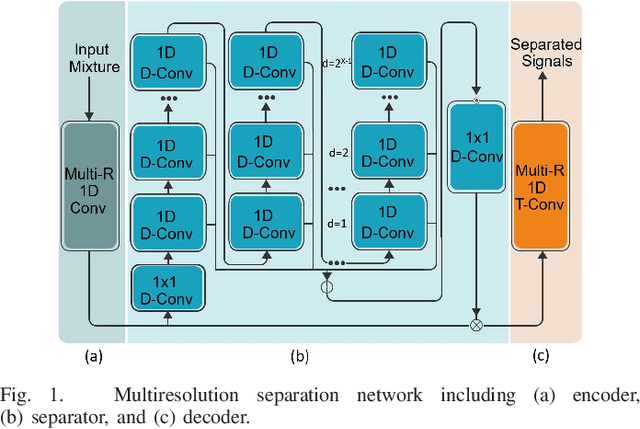
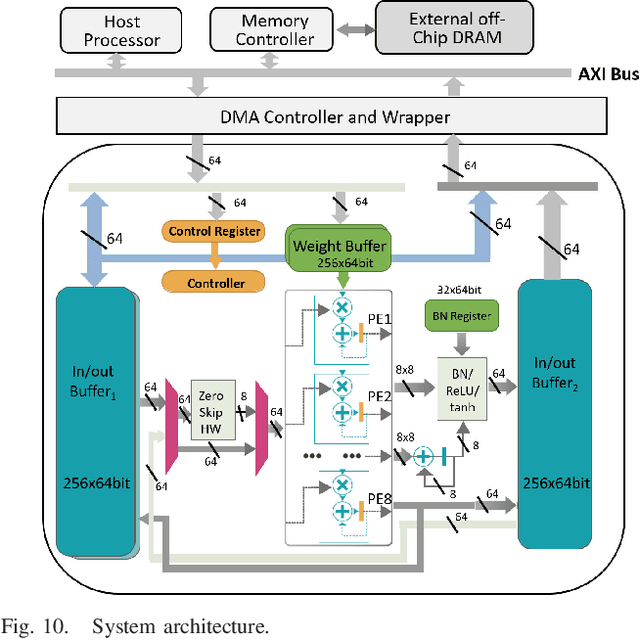
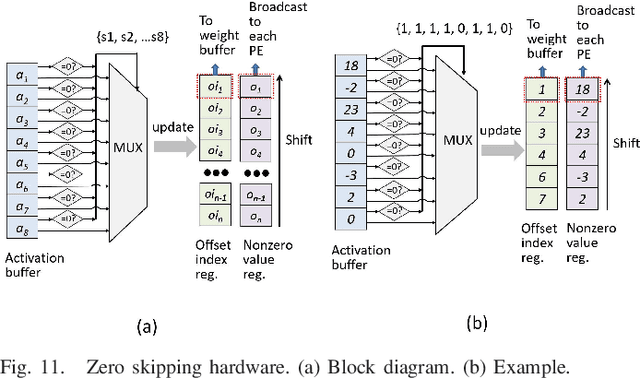
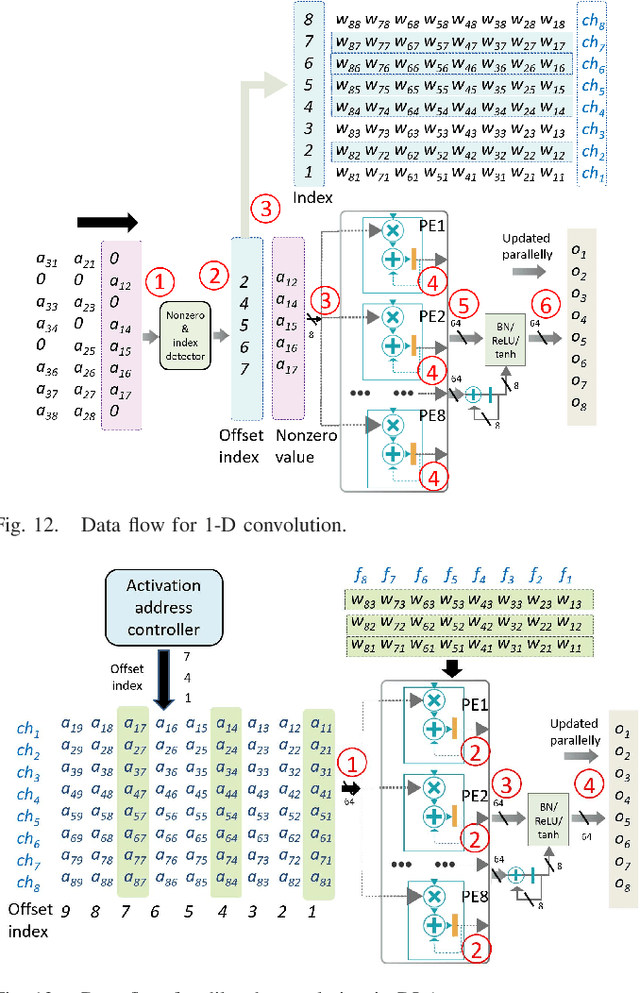
Low power deep learning accelerators on the speech processing enable real-time applications on edge devices. However, most of the existing accelerators suffer from high power consumption and focus on image applications only. This paper presents a low power accelerator for speech separation through algorithm and hardware optimizations. At the algorithm level, the model is compressed with structured sensitivity as well as unstructured pruning, and further quantized to the shifted 8-bit floating-point format instead of the 32-bit floating-point format. The computations with the zero kernel and zero activation values are skipped by decomposition of the dilated and transposed convolutions. At the hardware level, the compressed model is then supported by an architecture with eight independent multipliers and accumulators (MACs) with a simple zero-skipping hardware to take advantage of the activation sparsity and low power processing. The proposed approach reduces the model size by 95.44\% and computation complexity by 93.88\%. The final implementation with the TSMC 40 $nm$ process can achieve real-time speech separation and consumes 1.6 mW power when operated at 150 MHz. The normalized energy efficiency and area efficiency are 2.344 TOPS/W and 14.42 GOPS/mm$^2$, respectively.
Pre-RTL DNN Hardware Evaluator With Fused Layer Support
May 02, 2022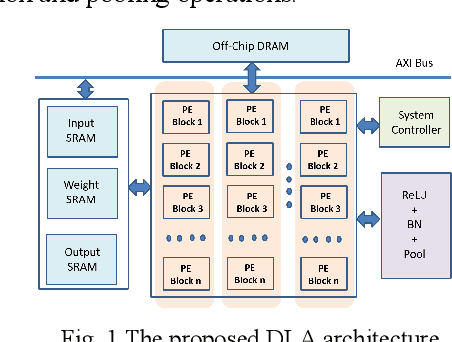
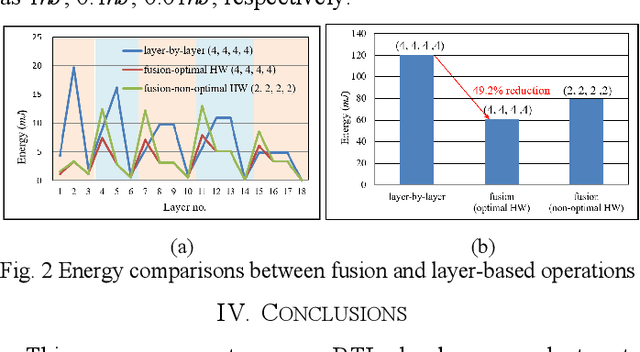
With the popularity of the deep neural network (DNN), hardware accelerators are demanded for real time execution. However, lengthy design process and fast evolving DNN models make hardware evaluation hard to meet the time to market need. This paper proposes a pre-RTL DNN hardware evaluator that supports conventional layer-by-layer processing as well as the fused layer processing for low external bandwidth requirement. The evaluator supports two state-of-the-art accelerator architectures and finds the best hardware and layer fusion group The experimental results show the layer fusion scheme can achieve 55.6% memory bandwidth reduction, 36.7% latency improvement and 49.2% energy reduction compared with layer-by-layer operation.
A Real Time 1280x720 Object Detection Chip With 585MB/s Memory Traffic
May 02, 2022
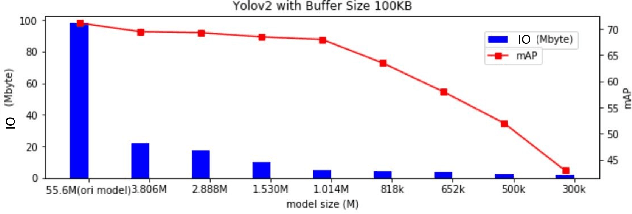
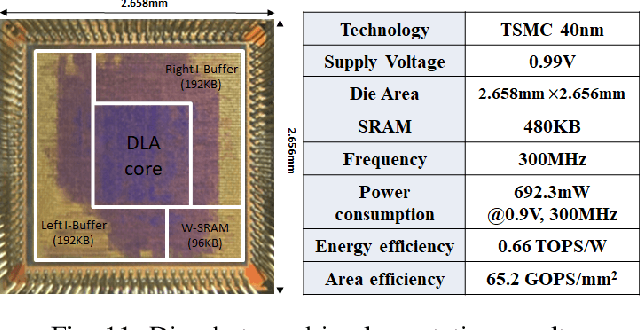

Memory bandwidth has become the real-time bottleneck of current deep learning accelerators (DLA), particularly for high definition (HD) object detection. Under resource constraints, this paper proposes a low memory traffic DLA chip with joint hardware and software optimization. To maximize hardware utilization under memory bandwidth, we morph and fuse the object detection model into a group fusion-ready model to reduce intermediate data access. This reduces the YOLOv2's feature memory traffic from 2.9 GB/s to 0.15 GB/s. To support group fusion, our previous DLA based hardware employes a unified buffer with write-masking for simple layer-by-layer processing in a fusion group. When compared to our previous DLA with the same PE numbers, the chip implemented in a TSMC 40nm process supports 1280x720@30FPS object detection and consumes 7.9X less external DRAM access energy, from 2607 mJ to 327.6 mJ.