 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real Time 1280x720 Object Detection Chip With 585MB/s Memory Traffic
May 02, 2022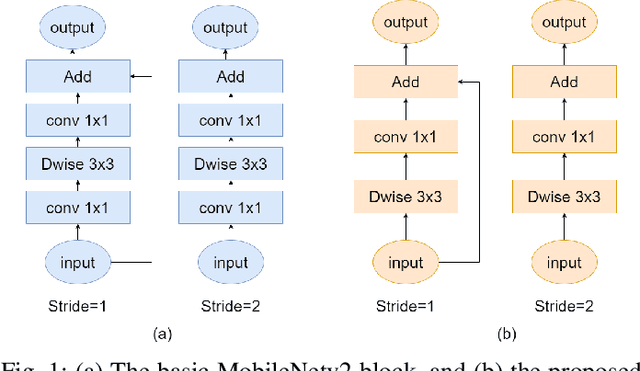
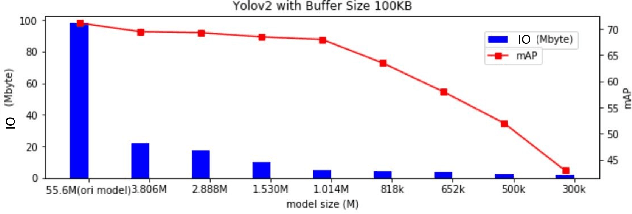
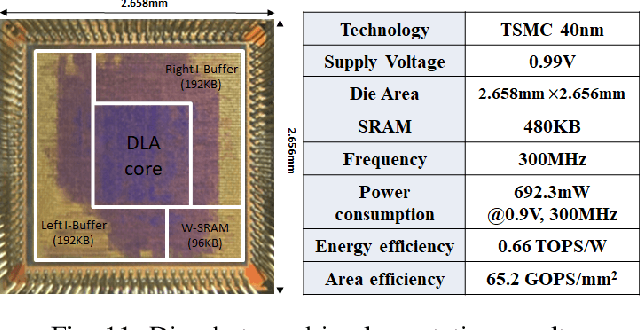

Memory bandwidth has become the real-time bottleneck of current deep learning accelerators (DLA), particularly for high definition (HD) object detection. Under resource constraints, this paper proposes a low memory traffic DLA chip with joint hardware and software optimization. To maximize hardware utilization under memory bandwidth, we morph and fuse the object detection model into a group fusion-ready model to reduce intermediate data access. This reduces the YOLOv2's feature memory traffic from 2.9 GB/s to 0.15 GB/s. To support group fusion, our previous DLA based hardware employes a unified buffer with write-masking for simple layer-by-layer processing in a fusion group. When compared to our previous DLA with the same PE numbers, the chip implemented in a TSMC 40nm process supports 1280x720@30FPS object detection and consumes 7.9X less external DRAM access energy, from 2607 mJ to 327.6 mJ.
Zebra: Memory Bandwidth Reduction for CNN Accelerators With Zero Block Regularization of Activation Maps
May 02, 2022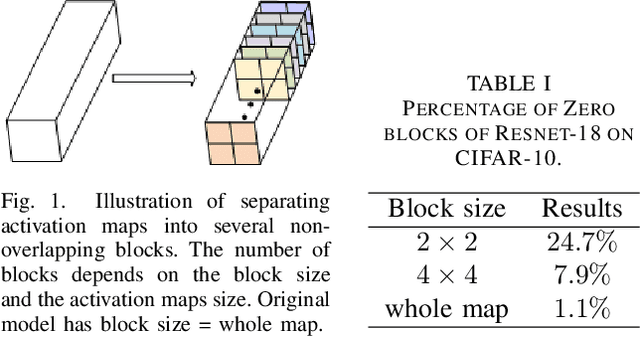

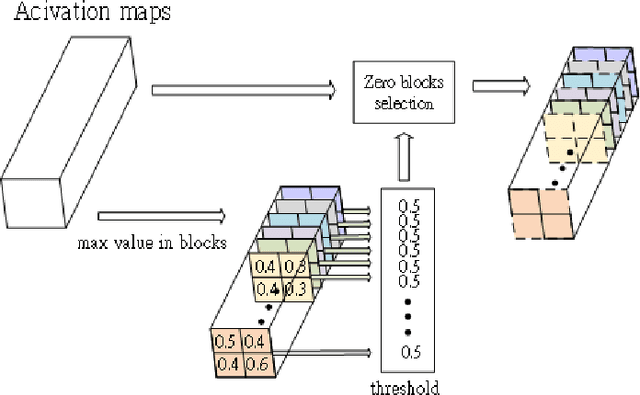

The large amount of memory bandwidth between local buffer and external DRAM has become the speedup bottleneck of CNN hardware accelerators, especially for activation maps. To reduce memory bandwidth, we propose to learn pruning unimportant blocks dynamically with zero block regularization of activation maps (Zebra). This strategy has low computational overhead and could easily integrate with other pruning methods for better performance. The experimental results show that the proposed method can reduce 70\% of memory bandwidth for Resnet-18 on Tiny-Imagenet within 1\% accuracy drops and 2\% accuracy gain with the combination of Network Slimming.