 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Accelerator for Dilated and Transposed Convolution with Decomposition
May 02, 2022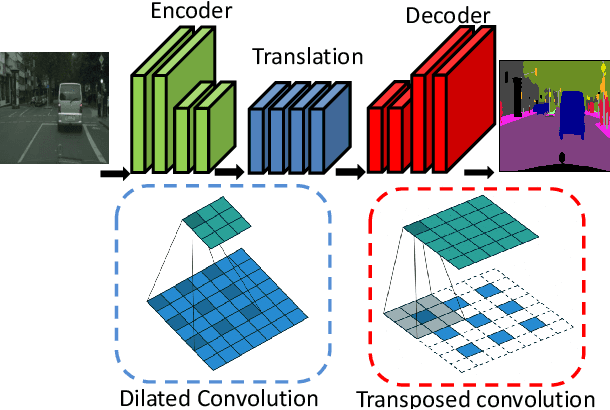
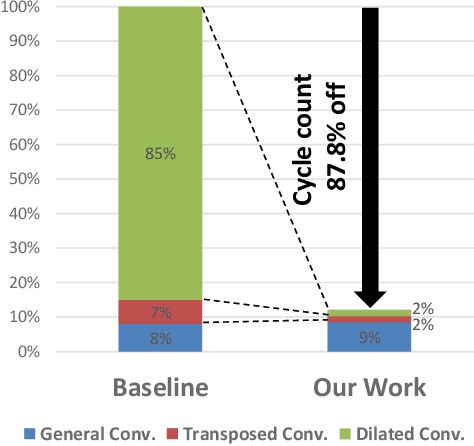
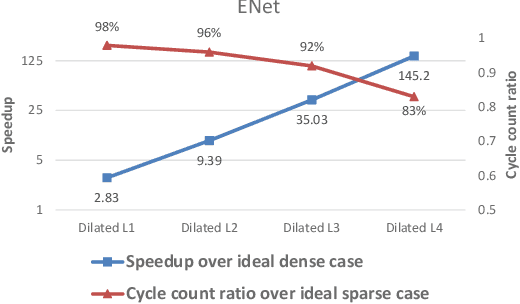
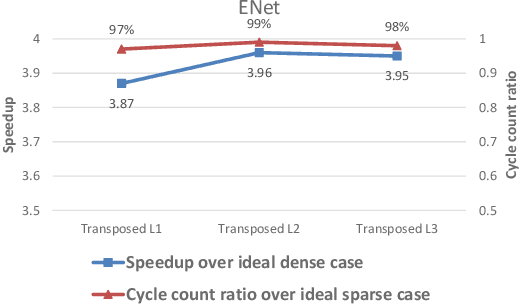
Hardware acceleration for dilated and transposed convolution enables real time execution of related tasks like segmentation, but current designs are specific for these convolutional types or suffer from complex control for reconfigurable designs. This paper presents a design that decomposes input or weight for dilated and transposed convolutions respectively to skip redundant computations and thus executes efficiently on existing dense CNN hardware as well. The proposed architecture can cut down 87.8\% of the cycle counts to achieve 8.2X speedup over a naive execution for the ENet case.
A Real Time 1280x720 Object Detection Chip With 585MB/s Memory Traffic
May 02, 2022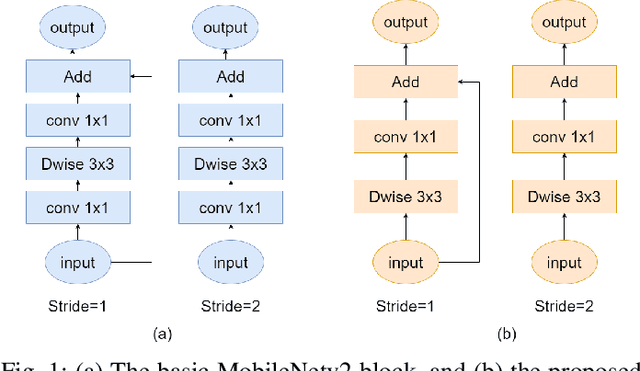
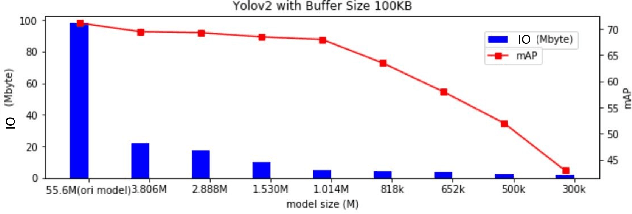
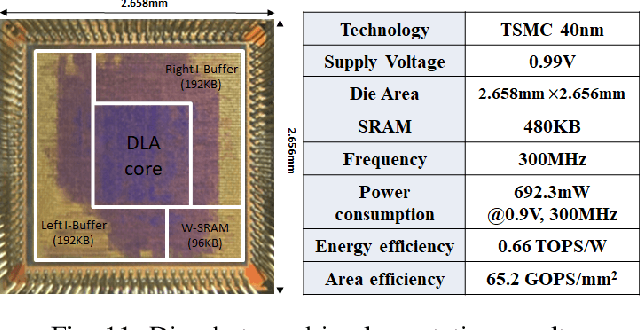

Memory bandwidth has become the real-time bottleneck of current deep learning accelerators (DLA), particularly for high definition (HD) object detection. Under resource constraints, this paper proposes a low memory traffic DLA chip with joint hardware and software optimization. To maximize hardware utilization under memory bandwidth, we morph and fuse the object detection model into a group fusion-ready model to reduce intermediate data access. This reduces the YOLOv2's feature memory traffic from 2.9 GB/s to 0.15 GB/s. To support group fusion, our previous DLA based hardware employes a unified buffer with write-masking for simple layer-by-layer processing in a fusion group. When compared to our previous DLA with the same PE numbers, the chip implemented in a TSMC 40nm process supports 1280x720@30FPS object detection and consumes 7.9X less external DRAM access energy, from 2607 mJ to 327.6 mJ.